 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetMamba+: A Framework of Pre-trained Models for Efficient and Accurate Network Traffic Classification
Jan 29, 2026With the rapid growth of encrypted network traffic, effective traffic classification has become essential for network security and quality of service management. Current machine learning and deep learning approaches for traffic classification face three critical challenges: computational inefficiency of Transformer architectures, inadequate traffic representations with loss of crucial byte-level features while retaining detrimental biases, and poor handling of long-tail distributions in real-world data. We propose NetMamba+, a framework that addresses these challenges through three key innovations: (1) an efficient architecture considering Mamba and Flash Attention mechanisms, (2) a multimodal traffic representation scheme that preserves essential traffic information while eliminating biases, and (3) a label distribution-aware fine-tuning strategy. Evaluation experiments on massive datasets encompassing four main classification tasks showcase NetMamba+'s superior classification performance compared to state-of-the-art baselines, with improvements of up to 6.44\% in F1 score. Moreover, NetMamba+ demonstrates excellent efficiency, achieving 1.7x higher inference throughput than the best baseline while maintaining comparably low memory usage. Furthermore, NetMamba+ exhibits superior few-shot learning abilities, achieving better classification performance with fewer labeled data. Additionally, we implement an online traffic classification system that demonstrates robust real-world performance with a throughput of 261.87 Mb/s. As the first framework to adapt Mamba architecture for network traffic classification, NetMamba+ opens new possibilities for efficient and accurate traffic analysis in complex network environments.
Bias in the Shadows: Explore Shortcuts in Encrypted Network Traffic Classification
Jan 15, 2026Pre-trained models operating directly on raw bytes have achieved promising performance in encrypted network traffic classification (NTC), but often suffer from shortcut learning-relying on spurious correlations that fail to generalize to real-world data. Existing solutions heavily rely on model-specific interpretation techniques, which lack adaptability and generality across different model architectures and deployment scenarios. In this paper, we propose BiasSeeker, the first semi-automated framework that is both model-agnostic and data-driven for detecting dataset-specific shortcut features in encrypted traffic. By performing statistical correlation analysis directly on raw binary traffic, BiasSeeker identifies spurious or environment-entangled features that may compromise generalization, independent of any classifier. To address the diverse nature of shortcut features, we introduce a systematic categorization and apply category-specific validation strategies that reduce bias while preserving meaningful information. We evaluate BiasSeeker on 19 public datasets across three NTC tasks. By emphasizing context-aware feature selection and dataset-specific diagnosis, BiasSeeker offers a novel perspective for understanding and addressing shortcut learning in encrypted network traffic classification, raising awareness that feature selection should be an intentional and scenario-sensitive step prior to model training.
UMAMI: Unifying Masked Autoregressive Models and Deterministic Rendering for View Synthesis
Dec 23, 2025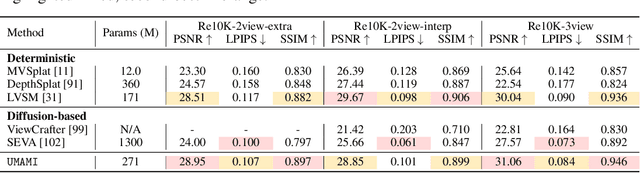
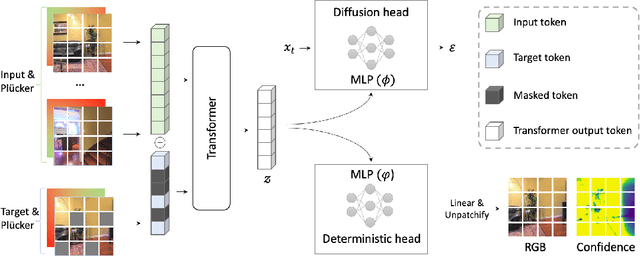
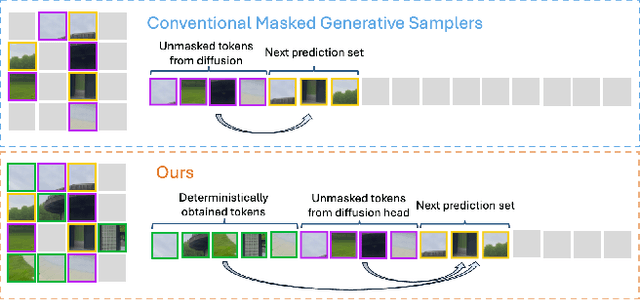

Novel view synthesis (NVS) seeks to render photorealistic, 3D-consistent images of a scene from unseen camera poses given only a sparse set of posed views. Existing deterministic networks render observed regions quickly but blur unobserved areas, whereas stochastic diffusion-based methods hallucinate plausible content yet incur heavy training- and inference-time costs. In this paper, we propose a hybrid framework that unifies the strengths of both paradigms. A bidirectional transformer encodes multi-view image tokens and Plucker-ray embeddings, producing a shared latent representation. Two lightweight heads then act on this representation: (i) a feed-forward regression head that renders pixels where geometry is well constrained, and (ii) a masked autoregressive diffusion head that completes occluded or unseen regions. The entire model is trained end-to-end with joint photometric and diffusion losses, without handcrafted 3D inductive biases, enabling scalability across diverse scenes. Experiments demonstrate that our method attains state-of-the-art image quality while reducing rendering time by an order of magnitude compared with fully generative baselines.
CoRA: A Collaborative Robust Architecture with Hybrid Fusion for Efficient Perception
Dec 15, 2025Collaborative perception has garnered significant attention as a crucial technology to overcome the perceptual limitations of single-agent systems. Many state-of-the-art (SOTA) methods have achieved communication efficiency and high performance via intermediate fusion. However, they share a critical vulnerability: their performance degrades under adverse communication conditions due to the misalignment induced by data transmission, which severely hampers their practical deployment. To bridge this gap, we re-examine different fusion paradigms, and recover that the strengths of intermediate and late fusion are not a trade-off, but a complementary pairing. Based on this key insight, we propose CoRA, a novel collaborative robust architecture with a hybrid approach to decouple performance from robustness with low communication. It is composed of two components: a feature-level fusion branch and an object-level correction branch. Its first branch selects critical features and fuses them efficiently to ensure both performance and scalability. The second branch leverages semantic relevance to correct spatial displacements, guaranteeing resilience against pose errors. Experiments demonstrate the superiority of CoRA. Under extreme scenarios, CoRA improves upon its baseline performance by approximately 19% in AP@0.7 with more than 5x less communication volume, which makes it a promising solution for robust collaborative perception.
MoME: Mixture of Visual Language Medical Experts for Medical Imaging Segmentation
Oct 30, 2025In this study, we propose MoME, a Mixture of Visual Language Medical Experts, for Medical Image Segmentation. MoME adapts the successful Mixture of Experts (MoE) paradigm, widely used in Large Language Models (LLMs), for medical vision-language tasks. The architecture enables dynamic expert selection by effectively utilizing multi-scale visual features tailored to the intricacies of medical imagery, enriched with textual embeddings. This work explores a novel integration of vision-language models for this domain. Utilizing an assembly of 10 datasets, encompassing 3,410 CT scans, MoME demonstrates strong performance on a comprehensive medical imaging segmentation benchmark. Our approach explores the integration of foundation models for medical imaging, benefiting from the established efficacy of MoE in boosting model performance by incorporating textual information. Demonstrating competitive precision across multiple datasets, MoME explores a novel architecture for achieving robust results in medical image analysis.
XOCT: Enhancing OCT to OCTA Translation via Cross-Dimensional Supervised Multi-Scale Feature Learning
Sep 09, 2025Optical Coherence Tomography Angiography (OCTA) and its derived en-face projections provide high-resolution visualization of the retinal and choroidal vasculature, which is critical for the rapid and accurate diagnosis of retinal diseases. However, acquiring high-quality OCTA images is challenging due to motion sensitivity and the high costs associated with software modifications for conventional OCT devices. Moreover, current deep learning methods for OCT-to-OCTA translation often overlook the vascular differences across retinal layers and struggle to reconstruct the intricate, dense vascular details necessary for reliable diagnosis. To overcome these limitations, we propose XOCT, a novel deep learning framework that integrates Cross-Dimensional Supervision (CDS) with a Multi-Scale Feature Fusion (MSFF) network for layer-aware vascular reconstruction. Our CDS module leverages 2D layer-wise en-face projections, generated via segmentation-weighted z-axis averaging, as supervisory signals to compel the network to learn distinct representations for each retinal layer through fine-grained, targeted guidance. Meanwhile, the MSFF module enhances vessel delineation through multi-scale feature extraction combined with a channel reweighting strategy, effectively capturing vascular details at multiple spatial scales. Our experiments on the OCTA-500 dataset demonstrate XOCT's improvements, especially for the en-face projections which are significant for clinical evaluation of retinal pathologies, underscoring its potential to enhance OCTA accessibility, reliability, and diagnostic value for ophthalmic disease detection and monitoring. The code is available at https://github.com/uci-cbcl/XOCT.
Ouroboros: Single-step Diffusion Models for Cycle-consistent Forward and Inverse Rendering
Aug 20, 2025



While multi-step diffusion models have advanced both forward and inverse rendering, existing approaches often treat these problems independently, leading to cycle inconsistency and slow inference speed. In this work, we present Ouroboros, a framework composed of two single-step diffusion models that handle forward and inverse rendering with mutual reinforcement. Our approach extends intrinsic decomposition to both indoor and outdoor scenes and introduces a cycle consistency mechanism that ensures coherence between forward and inverse rendering outputs. Experimental results demonstrate state-of-the-art performance across diverse scenes while achieving substantially faster inference speed compared to other diffusion-based methods. We also demonstrate that Ouroboros can transfer to video decomposition in a training-free manner, reducing temporal inconsistency in video sequences while maintaining high-quality per-frame inverse rendering.
Leveraging LLM Agents for Translating Network Configurations
Jan 15, 2025Configuration translation is a critical and frequent task in network operations. When a network device is damaged or outdated, administrators need to replace it to maintain service continuity. The replacement devices may originate from different vendors, necessitating configuration translation to ensure seamless network operation. However, translating configurations manually is a labor-intensive and error-prone process. In this paper, we propose an intent-based framework for translating network configuration with Large Language Model (LLM) Agents. The core of our approach is an Intent-based Retrieval Augmented Generation (IRAG) module that systematically splits a configuration file into fragments, extracts intents, and generates accurate translations. We also design a two-stage verification method to validate the syntax and semantics correctness of the translated configurations. We implement and evaluate the proposed method on real-world network configurations. Experimental results show that our method achieves 97.74% syntax correctness, outperforming state-of-the-art methods in translation accuracy.
CoMA: Compositional Human Motion Generation with Multi-modal Agents
Dec 10, 2024



3D human motion generation has seen substantial advancement in recent years. While state-of-the-art approaches have improved performance significantly, they still struggle with complex and detailed motions unseen in training data, largely due to the scarcity of motion datasets and the prohibitive cost of generating new training examples. To address these challenges, we introduce CoMA, an agent-based solution for complex human motion generation, editing, and comprehension. CoMA leverages multiple collaborative agents powered by large language and vision models, alongside a mask transformer-based motion generator featuring body part-specific encoders and codebooks for fine-grained control. Our framework enables generation of both short and long motion sequences with detailed instructions, text-guided motion editing, and self-correction for improved quality. Evaluations on the HumanML3D dataset demonstrate competitive performance against state-of-the-art methods. Additionally, we create a set of context-rich, compositional, and long text prompts, where user studies show our method significantly outperforms existing approaches.
Contrastive Learning for Implicit Social Factors in Social Media Popularity Prediction
Oct 12, 2024On social media sharing platforms, some posts are inherently destined for popularity. Therefore, understanding the reasons behind this phenomenon and predicting popularity before post publication holds significant practical value. The previous work predominantly focuses on enhancing post content extraction for better prediction results. However, certain factors introduced by social platforms also impact post popularity, which has not been extensively studied. For instance, users are more likely to engage with posts from individuals they follow, potentially influencing the popularity of these posts. We term these factors, unrelated to the explicit attractiveness of content, as implicit social factors. Through the analysis of users' post browsing behavior (also validated in public datasets), we propose three implicit social factors related to popularity, including content relevance, user influence similarity, and user identity. To model the proposed social factors, we introduce three supervised contrastive learning tasks. For different task objectives and data types, we assign them to different encoders and control their gradient flows to achieve joint optimization. We also design corresponding sampling and augmentation algorithms to improve the effectiveness of contrastive learning. Extensive experiments on the Social Media Popularity Dataset validate the superiority of our proposed method and also confirm the important role of implicit social factors in popularity prediction. We open source the code at https://github.com/Daisy-zzz/PPCL.git.