 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgocentric World Model for Photorealistic Hand-Object Interaction Synthesis
Mar 13, 2026To serve as a scalable data source for embodied AI, world models should act as true simulators that infer interaction dynamics strictly from user actions, rather than mere conditional video generators relying on privileged future object states. In this context, egocentric Human-Object Interaction (HOI) world models are critical for predicting physically grounded first-person rollouts. However, building such models is profoundly challenging due to rapid head motions, severe occlusions, and high-DoF hand articulations that abruptly alter contact topologies. Consequently, existing approaches often circumvent these physics challenges by resorting to conditional video generation with access to known future object trajectories. We introduce EgoHOI, an egocentric HOI world model that breaks away from this shortcut to simulate photorealistic, contact-consistent interactions from action signals alone. To ensure physical accuracy without future-state inputs, EgoHOI distills geometric and kinematic priors from 3D estimates into physics-informed embeddings. These embeddings regularize the egocentric rollouts toward physically valid dynamics. Experiments on the HOT3D dataset demonstrate consistent gains over strong baselines, and ablations validate the effectiveness of our physics-informed design.
HorizonForge: Driving Scene Editing with Any Trajectories and Any Vehicles
Feb 24, 2026Controllable driving scene generation is critical for realistic and scalable autonomous driving simulation, yet existing approaches struggle to jointly achieve photorealism and precise control. We introduce HorizonForge, a unified framework that reconstructs scenes as editable Gaussian Splats and Meshes, enabling fine-grained 3D manipulation and language-driven vehicle insertion. Edits are rendered through a noise-aware video diffusion process that enforces spatial and temporal consistency, producing diverse scene variations in a single feed-forward pass without per-trajectory optimization. To standardize evaluation, we further propose HorizonSuite, a comprehensive benchmark spanning ego- and agent-level editing tasks such as trajectory modifications and object manipulation. Extensive experiments show that Gaussian-Mesh representation delivers substantially higher fidelity than alternative 3D representations, and that temporal priors from video diffusion are essential for coherent synthesis. Combining these findings, HorizonForge establishes a simple yet powerful paradigm for photorealistic, controllable driving simulation, achieving an 83.4% user-preference gain and a 25.19% FID improvement over the second best state-of-the-art method. Project page: https://horizonforge.github.io/ .
CSRv2: Unlocking Ultra-Sparse Embeddings
Feb 05, 2026In the era of large foundation models, the quality of embeddings has become a central determinant of downstream task performance and overall system capability. Yet widely used dense embeddings are often extremely high-dimensional, incurring substantial costs in storage, memory, and inference latency. To address these, Contrastive Sparse Representation (CSR) is recently proposed as a promising direction, mapping dense embeddings into high-dimensional but k-sparse vectors, in contrast to compact dense embeddings such as Matryoshka Representation Learning (MRL). Despite its promise, CSR suffers severe degradation in the ultra-sparse regime, where over 80% of neurons remain inactive, leaving much of its efficiency potential unrealized. In this paper, we introduce CSRv2, a principled training approach designed to make ultra-sparse embeddings viable. CSRv2 stabilizes sparsity learning through progressive k-annealing, enhances representational quality via supervised contrastive objectives, and ensures end-to-end adaptability with full backbone finetuning. CSRv2 reduces dead neurons from 80% to 20% and delivers a 14% accuracy gain at k=2, bringing ultra-sparse embeddings on par with CSR at k=8 and MRL at 32 dimensions, all with only two active features. While maintaining comparable performance, CSRv2 delivers a 7x speedup over MRL, and yields up to 300x improvements in compute and memory efficiency relative to dense embeddings in text representation. Extensive experiments across text and vision demonstrate that CSRv2 makes ultra-sparse embeddings practical without compromising performance, where CSRv2 achieves 7%/4% improvement over CSR when k=4 and further increases this gap to 14%/6% when k=2 in text/vision representation. By making extreme sparsity viable, CSRv2 broadens the design space for real-time and edge-deployable AI systems where both embedding quality and efficiency are critical.
FORESTLLM: Large Language Models Make Random Forest Great on Few-shot Tabular Learning
Jan 16, 2026Tabular data high-stakes critical decision-making in domains such as finance, healthcare, and scientific discovery. Yet, learning effectively from tabular data in few-shot settings, where labeled examples are scarce, remains a fundamental challenge. Traditional tree-based methods often falter in these regimes due to their reliance on statistical purity metrics, which become unstable and prone to overfitting with limited supervision. At the same time, direct applications of large language models (LLMs) often overlook its inherent structure, leading to suboptimal performance. To overcome these limitations, we propose FORESTLLM, a novel framework that unifies the structural inductive biases of decision forests with the semantic reasoning capabilities of LLMs. Crucially, FORESTLLM leverages the LLM only during training, treating it as an offline model designer that encodes rich, contextual knowledge into a lightweight, interpretable forest model, eliminating the need for LLM inference at test time. Our method is two-fold. First, we introduce a semantic splitting criterion in which the LLM evaluates candidate partitions based on their coherence over both labeled and unlabeled data, enabling the induction of more robust and generalizable tree structures under few-shot supervision. Second, we propose a one-time in-context inference mechanism for leaf node stabilization, where the LLM distills the decision path and its supporting examples into a concise, deterministic prediction, replacing noisy empirical estimates with semantically informed outputs. Across a diverse suite of few-shot classification and regression benchmarks, FORESTLLM achieves state-of-the-art performance.
Geometric and Dynamic Scaling in Deep Transformers
Jan 06, 2026Despite their empirical success, pushing Transformer architectures to extreme depth often leads to a paradoxical failure: representations become increasingly redundant, lose rank, and ultimately collapse. Existing explanations largely attribute this phenomenon to optimization instability or vanishing gradients, yet such accounts fail to explain why collapse persists even under modern normalization and initialization schemes. In this paper, we argue that the collapse of deep Transformers is fundamentally a geometric problem. Standard residual updates implicitly assume that feature accumulation is always beneficial, but offer no mechanism to constrain update directions or to erase outdated information. As depth increases, this leads to systematic drift off the semantic manifold and monotonic feature accumulation, causing representational degeneracy. We propose a unified geometric framework that addresses these failures through two orthogonal principles. First, manifold-constrained hyper-connections restrict residual updates to valid local tangent directions, preventing uncontrolled manifold drift. Second, deep delta learning introduces data-dependent, non-monotonic updates that enable reflection and erasure of redundant features rather than their unconditional accumulation. Together, these mechanisms decouple the direction and sign of feature updates, yielding a stable geometric evolution across depth. We term the resulting architecture the Manifold-Geometric Transformer (MGT). Our analysis predicts that enforcing geometric validity while allowing dynamic erasure is essential for avoiding rank collapse in ultra-deep networks. We outline an evaluation protocol for Transformers exceeding 100 layers to test the hypothesis that geometry, rather than depth itself, is the key limiting factor in deep representation learning.
Reflection Pretraining Enables Token-Level Self-Correction in Biological Sequence Models
Dec 24, 2025



Chain-of-Thought (CoT) prompting has significantly advanced task-solving capabilities in natural language processing with large language models. Unlike standard prompting, CoT encourages the model to generate intermediate reasoning steps, non-answer tokens, that help guide the model toward more accurate final outputs. These intermediate steps enable more complex reasoning processes such as error correction, memory management, future planning, and self-reflection. However, applying CoT to non-natural language domains, such as protein and RNA language models, is not yet possible, primarily due to the limited expressiveness of their token spaces (e.g., amino acid tokens). In this work, we propose and define the concept of language expressiveness: the ability of a given language, using its tokens and grammar, to encode information. We show that the limited expressiveness of protein language severely restricts the applicability of CoT-style reasoning. To overcome this, we introduce reflection pretraining, for the first time in a biological sequence model, which enables the model to engage in intermediate reasoning through the generation of auxiliary "thinking tokens" beyond simple answer tokens. Theoretically, we demonstrate that our augmented token set significantly enhances biological language expressiveness, thereby improving the overall reasoning capacity of the model. Experimentally, our pretraining approach teaches protein models to self-correct and leads to substantial performance gains compared to standard pretraining.
Accurate de novo sequencing of the modified proteome with OmniNovo
Dec 13, 2025Post-translational modifications (PTMs) serve as a dynamic chemical language regulating protein function, yet current proteomic methods remain blind to a vast portion of the modified proteome. Standard database search algorithms suffer from a combinatorial explosion of search spaces, limiting the identification of uncharacterized or complex modifications. Here we introduce OmniNovo, a unified deep learning framework for reference-free sequencing of unmodified and modified peptides directly from tandem mass spectra. Unlike existing tools restricted to specific modification types, OmniNovo learns universal fragmentation rules to decipher diverse PTMs within a single coherent model. By integrating a mass-constrained decoding algorithm with rigorous false discovery rate estimation, OmniNovo achieves state-of-the-art accuracy, identifying 51\% more peptides than standard approaches at a 1\% false discovery rate. Crucially, the model generalizes to biological sites unseen during training, illuminating the dark matter of the proteome and enabling unbiased comprehensive analysis of cellular regulation.
Route Experts by Sequence, not by Token
Nov 09, 2025Mixture-of-Experts (MoE) architectures scale large language models (LLMs) by activating only a subset of experts per token, but the standard TopK routing assigns the same fixed number of experts to all tokens, ignoring their varying complexity. Prior adaptive routing methods introduce additional modules and hyperparameters, often requiring costly retraining from scratch. We propose Sequence-level TopK (SeqTopK), a minimal modification that shifts the expert budget from the token level to the sequence level. By selecting the top $T \cdot K$ experts across all $T$ tokens, SeqTopK enables end-to-end learned dynamic allocation -- assigning more experts to difficult tokens and fewer to easy ones -- while preserving the same overall budget. SeqTopK requires only a few lines of code, adds less than 1% overhead, and remains fully compatible with pretrained MoE models. Experiments across math, coding, law, and writing show consistent improvements over TopK and prior parameter-free adaptive methods, with gains that become substantially larger under higher sparsity (up to 16.9%). These results highlight SeqTopK as a simple, efficient, and scalable routing strategy, particularly well-suited for the extreme sparsity regimes of next-generation LLMs. Code is available at https://github.com/Y-Research-SBU/SeqTopK.
PET Head Motion Estimation Using Supervised Deep Learning with Attention
Oct 14, 2025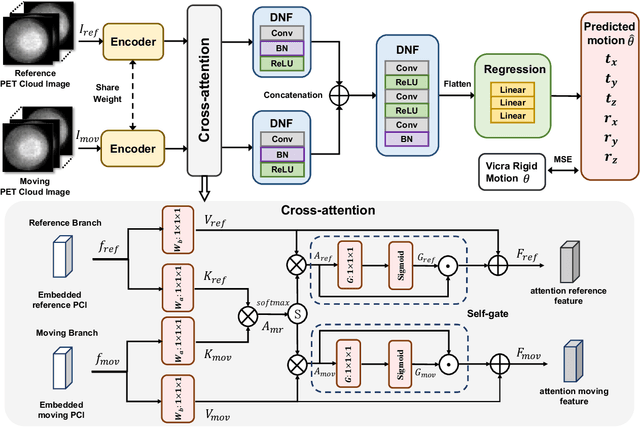
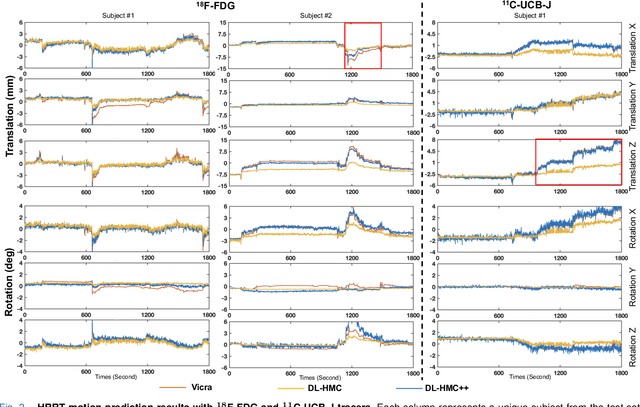
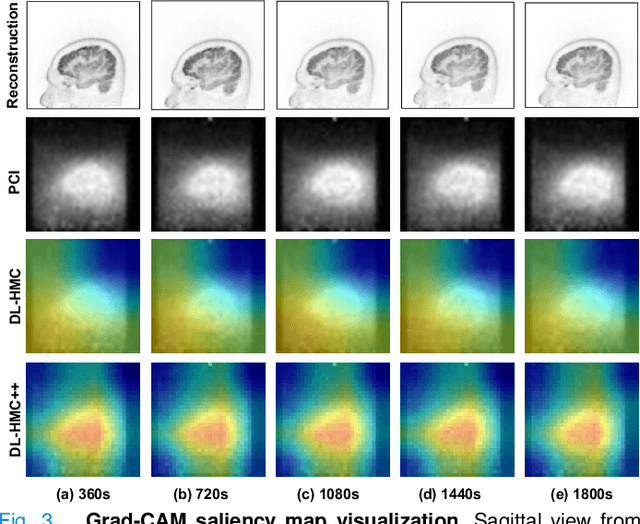
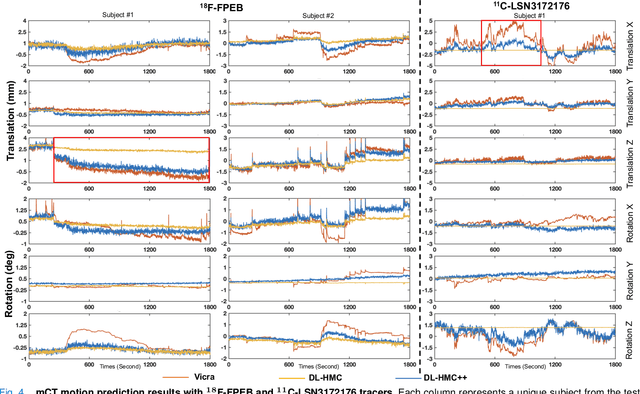
Head movement poses a significant challenge in brain positron emission tomography (PET) imaging, resulting in image artifacts and tracer uptake quantification inaccuracies. Effective head motion estimation and correction are crucial for precise quantitative image analysis and accurate diagnosis of neurological disorders. Hardware-based motion tracking (HMT) has limited applicability in real-world clinical practice. To overcome this limitation, we propose a deep-learning head motion correction approach with cross-attention (DL-HMC++) to predict rigid head motion from one-second 3D PET raw data. DL-HMC++ is trained in a supervised manner by leveraging existing dynamic PET scans with gold-standard motion measurements from external HMT. We evaluate DL-HMC++ on two PET scanners (HRRT and mCT) and four radiotracers (18F-FDG, 18F-FPEB, 11C-UCB-J, and 11C-LSN3172176) to demonstrate the effectiveness and generalization of the approach in large cohort PET studies. Quantitative and qualitative results demonstrate that DL-HMC++ consistently outperforms state-of-the-art data-driven motion estimation methods, producing motion-free images with clear delineation of brain structures and reduced motion artifacts that are indistinguishable from gold-standard HMT. Brain region of interest standard uptake value analysis exhibits average difference ratios between DL-HMC++ and gold-standard HMT to be 1.2 plus-minus 0.5% for HRRT and 0.5 plus-minus 0.2% for mCT. DL-HMC++ demonstrates the potential for data-driven PET head motion correction to remove the burden of HMT, making motion correction accessible to clinical populations beyond research settings. The code is available at https://github.com/maxxxxxxcai/DL-HMC-TMI.
TimeSeriesScientist: A General-Purpose AI Agent for Time Series Analysis
Oct 02, 2025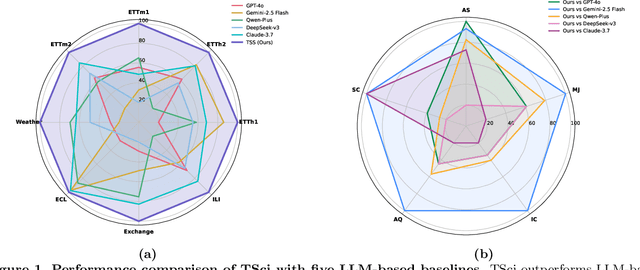
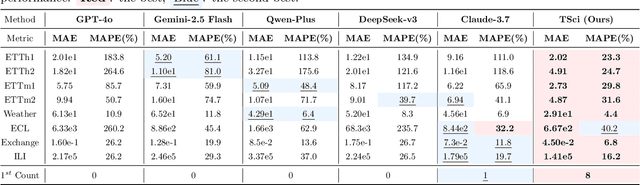
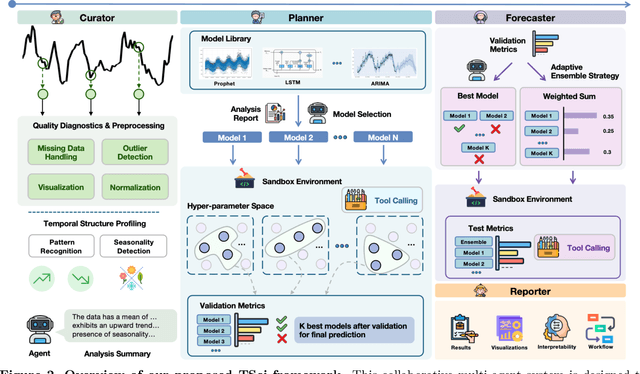
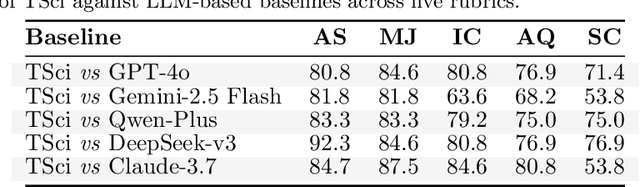
Time series forecasting is central to decision-making in domains as diverse as energy, finance, climate, and public health. In practice, forecasters face thousands of short, noisy series that vary in frequency, quality, and horizon, where the dominant cost lies not in model fitting, but in the labor-intensive preprocessing, validation, and ensembling required to obtain reliable predictions. Prevailing statistical and deep learning models are tailored to specific datasets or domains and generalize poorly. A general, domain-agnostic framework that minimizes human intervention is urgently in demand. In this paper, we introduce TimeSeriesScientist (TSci), the first LLM-driven agentic framework for general time series forecasting. The framework comprises four specialized agents: Curator performs LLM-guided diagnostics augmented by external tools that reason over data statistics to choose targeted preprocessing; Planner narrows the hypothesis space of model choice by leveraging multi-modal diagnostics and self-planning over the input; Forecaster performs model fitting and validation and, based on the results, adaptively selects the best model configuration as well as ensemble strategy to make final predictions; and Reporter synthesizes the whole process into a comprehensive, transparent report. With transparent natural-language rationales and comprehensive reports, TSci transforms the forecasting workflow into a white-box system that is both interpretable and extensible across tasks. Empirical results on eight established benchmarks demonstrate that TSci consistently outperforms both statistical and LLM-based baselines, reducing forecast error by an average of 10.4% and 38.2%, respectively. Moreover, TSci produces a clear and rigorous report that makes the forecasting workflow more transparent and interpretable.