 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeBridge: Variational Schrödinger Bridges for Cellular Transition Dynamics
Jun 09, 2026High-content imaging assays quantify cellular responses to chemical and genetic perturbations, yet continuous trajectories of individual cells are unobservable because cells are chemically fixed at acquisition. Perturbation modeling therefore reduces to inferring stochastic transport between control and treated populations observed only as separate marginals. While recent generative models achieve strong end-point alignment, boundary consistency does not determine intermediate evolution: multiple stochastic processes may connect identical marginals while traversing regions unsupported by observed single-cell morphologies. We introduce \textbf{FreeBridge}, a Schrödinger Bridge formulation for single-cell transition modeling under endpoint-only supervision. FreeBridge defines atomic states as instance-segmented single-cell representations, establishing a fixed cellular manifold, and learns stochastic transport constrained within this geometry via empirical latent support regularization. Across BBBC021, RxRx1, and JUMP, FreeBridge maintains competitive or improved endpoint fidelity and mechanism-of-action retention under a unified evaluation protocol; on BBBC021, it further reduces intermediate support violations. These findings highlight the importance of geometric grounding for biologically interpretable perturbation dynamics. Project page: https://y-research-sbu.github.io/FreeBridge/.
Ouroboros: Single-step Diffusion Models for Cycle-consistent Forward and Inverse Rendering
Aug 20, 2025



While multi-step diffusion models have advanced both forward and inverse rendering, existing approaches often treat these problems independently, leading to cycle inconsistency and slow inference speed. In this work, we present Ouroboros, a framework composed of two single-step diffusion models that handle forward and inverse rendering with mutual reinforcement. Our approach extends intrinsic decomposition to both indoor and outdoor scenes and introduces a cycle consistency mechanism that ensures coherence between forward and inverse rendering outputs. Experimental results demonstrate state-of-the-art performance across diverse scenes while achieving substantially faster inference speed compared to other diffusion-based methods. We also demonstrate that Ouroboros can transfer to video decomposition in a training-free manner, reducing temporal inconsistency in video sequences while maintaining high-quality per-frame inverse rendering.
OTSurv: A Novel Multiple Instance Learning Framework for Survival Prediction with Heterogeneity-aware Optimal Transport
Jun 25, 2025Survival prediction using whole slide images (WSIs) can be formulated as a multiple instance learning (MIL) problem. However, existing MIL methods often fail to explicitly capture pathological heterogeneity within WSIs, both globally -- through long-tailed morphological distributions, and locally through -- tile-level prediction uncertainty. Optimal transport (OT) provides a principled way of modeling such heterogeneity by incorporating marginal distribution constraints. Building on this insight, we propose OTSurv, a novel MIL framework from an optimal transport perspective. Specifically, OTSurv formulates survival predictions as a heterogeneity-aware OT problem with two constraints: (1) global long-tail constraint that models prior morphological distributions to avert both mode collapse and excessive uniformity by regulating transport mass allocation, and (2) local uncertainty-aware constraint that prioritizes high-confidence patches while suppressing noise by progressively raising the total transport mass. We then recast the initial OT problem, augmented by these constraints, into an unbalanced OT formulation that can be solved with an efficient, hardware-friendly matrix scaling algorithm. Empirically, OTSurv sets new state-of-the-art results across six popular benchmarks, achieving an absolute 3.6% improvement in average C-index. In addition, OTSurv achieves statistical significance in log-rank tests and offers high interpretability, making it a powerful tool for survival prediction in digital pathology. Our codes are available at https://github.com/Y-Research-SBU/OTSurv.
LONGER: Scaling Up Long Sequence Modeling in Industrial Recommenders
May 07, 2025

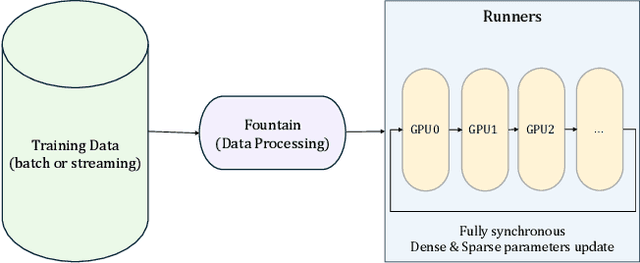
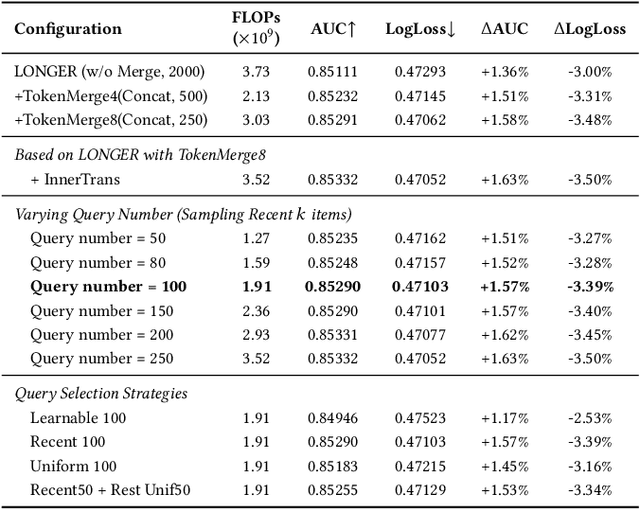
Modeling ultra-long user behavior sequences is critical for capturing both long- and short-term preferences in industrial recommender systems. Existing solutions typically rely on two-stage retrieval or indirect modeling paradigms, incuring upstream-downstream inconsistency and computational inefficiency. In this paper, we present LONGER, a Long-sequence Optimized traNsformer for GPU-Efficient Recommenders. LONGER incorporates (i) a global token mechanism for stabilizing attention over long contexts, (ii) a token merge module with lightweight InnerTransformers and hybrid attention strategy to reduce quadratic complexity, and (iii) a series of engineering optimizations, including training with mixed-precision and activation recomputation, KV cache serving, and the fully synchronous model training and serving framework for unified GPU-based dense and sparse parameter updates. LONGER consistently outperforms strong baselines in both offline metrics and online A/B testing in both advertising and e-commerce services at ByteDance, validating its consistent effectiveness and industrial-level scaling laws. Currently, LONGER has been fully deployed at more than 10 influential scenarios at ByteDance, serving billion users.
Adaptive Domain Scaling for Personalized Sequential Modeling in Recommenders
Feb 08, 2025



Users generally exhibit complex behavioral patterns and diverse intentions in multiple business scenarios of super applications like Douyin, presenting great challenges to current industrial multi-domain recommenders. To mitigate the discrepancies across diverse domains, researches and industrial practices generally emphasize sophisticated network structures to accomodate diverse data distributions, while neglecting the inherent understanding of user behavioral sequence from the multi-domain perspective. In this paper, we present Adaptive Domain Scaling (ADS) model, which comprehensively enhances the personalization capability in target-aware sequence modeling across multiple domains. Specifically, ADS comprises of two major modules, including personalized sequence representation generation (PSRG) and personalized candidate representation generation (PCRG). The modules contribute to the tailored multi-domain learning by dynamically learning both the user behavioral sequence item representation and the candidate target item representation under different domains, facilitating adaptive user intention understanding. Experiments are performed on both a public dataset and two billion-scaled industrial datasets, and the extensive results verify the high effectiveness and compatibility of ADS. Besides, we conduct online experiments on two influential business scenarios including Douyin Advertisement Platform and Douyin E-commerce Service Platform, both of which show substantial business improvements. Currently, ADS has been fully deployed in many recommendation services at ByteDance, serving billions of users.
ViBERTgrid: A Jointly Trained Multi-Modal 2D Document Representation for Key Information Extraction from Documents
May 25, 2021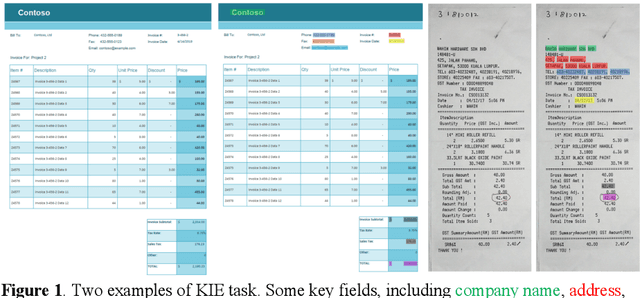
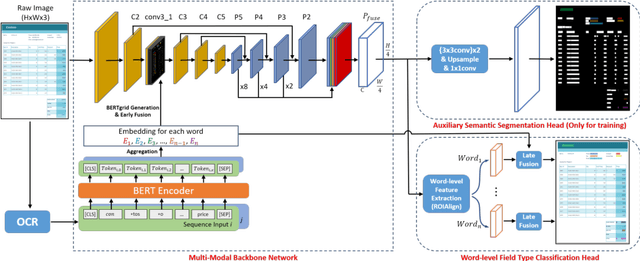
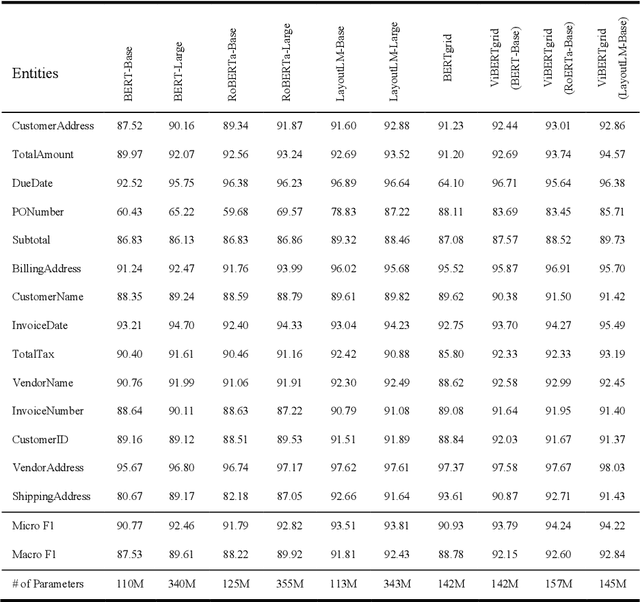
Recent grid-based document representations like BERTgrid allow the simultaneous encoding of the textual and layout information of a document in a 2D feature map so that state-of-the-art image segmentation and/or object detection models can be straightforwardly leveraged to extract key information from documents. However, such methods have not achieved comparable performance to state-of-the-art sequence- and graph-based methods such as LayoutLM and PICK yet. In this paper, we propose a new multi-modal backbone network by concatenating a BERTgrid to an intermediate layer of a CNN model, where the input of CNN is a document image and the BERTgrid is a grid of word embeddings, to generate a more powerful grid-based document representation, named ViBERTgrid. Unlike BERTgrid, the parameters of BERT and CNN in our multimodal backbone network are trained jointly. Our experimental results demonstrate that this joint training strategy improves significantly the representation ability of ViBERTgrid. Consequently, our ViBERTgrid-based key information extraction approach has achieved state-of-the-art performance on real-world datasets.