 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Should LLMs Listen While Speaking? A Study of User-Stream Routing in Full-Duplex Spoken Dialogue
May 11, 2026Full-duplex spoken dialogue requires a model to keep listening while generating its own spoken response. This is challenging for large language models (LLMs), which are designed to extend a single coherent sequence and do not naturally support user input arriving during generation. We argue that how the user stream is routed into the LLM is therefore a key architectural question for full-duplex modeling. To study this question, we extend a text-only LLM into a unified full-duplex spoken dialogue system and compare two routing strategies under a shared training pipeline: (i) channel fusion, which injects the user stream directly into the LLM input, and (ii) cross-attention routing, which keeps the user stream as external memory accessed through cross-attention adapters. Experiments on spoken question answering and full-duplex interaction benchmarks reveal a clear tradeoff. Channel fusion yields stronger semantic grounding and consistently better question-answering performance. However, under semantically overlapping conditions such as user interruptions, it is more vulnerable to context corruption: if the model fails to stop in time, the overlapping user stream can interfere with ongoing generation and lead to semantically incoherent continuations. Cross-attention routing underperforms on question answering, but better preserves the LLM generation context and is more robust to this failure mode. These results establish user-stream routing as a central design axis in full-duplex spoken dialogue and offer practical guidance on the tradeoff between semantic integration and context robustness. We provide a demo page for qualitative inspection.
Towards Streaming Target Speaker Extraction via Chunk-wise Interleaved Splicing of Autoregressive Language Model
Apr 21, 2026While generative models have set new benchmarks for Target Speaker Extraction (TSE), their inherent reliance on global context precludes deployment in real-time applications. Direct adaptation to streaming scenarios often leads to catastrophic inference performance degradation due to the severe mismatch between training and streaming inference. To bridge this gap, we present the first autoregressive (AR) models tailored for streaming TSE. Our approach introduces a Chunk-wise Interleaved Splicing Paradigm that ensures highly efficient and stable streaming inference. To ensure the coherence between the extracted speech segments, we design a historical context refinement mechanism that mitigates boundary discontinuities by leveraging historical information. Experiments on Libri2Mix show that while AR generative baseline exhibits performance degradation at low latencies, our approach maintains 100% stability and superior intelligibility. Furthermore, our streaming results are comparable to or even surpass offline baselines. Additionally, our model achieves a Real-Time-Factor (RTF) of 0.248 on consumer-level GPUs. This work provides empirical evidence that AR generative backbones are viable for latency-sensitive applications through the Chunk-wise Interleaved Splicing Paradigm.
Compute Only Once: UG-Separation for Efficient Large Recommendation Models
Feb 11, 2026Driven by scaling laws, recommender systems increasingly rely on large-scale models to capture complex feature interactions and user behaviors, but this trend also leads to prohibitive training and inference costs. While long-sequence models(e.g., LONGER) can reuse user-side computation through KV caching, such reuse is difficult in dense feature interaction architectures(e.g., RankMixer), where user and group (candidate item) features are deeply entangled across layers. In this work, we propose User-Group Separation (UG-Sep), a novel framework that enables reusable user-side computation in dense interaction models for the first time. UG-Sep introduces a masking mechanism that explicitly disentangles user-side and item-side information flows within token-mixing layers, ensuring that a subset of tokens to preserve purely user-side representations across layers. This design enables corresponding token computations to be reused across multiple samples, significantly reducing redundant inference cost. To compensate for potential expressiveness loss induced by masking, we further propose an Information Compensation strategy that adaptively reconstructs suppressed user-item interactions. Moreover, as UG-Sep substantially reduces user-side FLOPs and exposes memory-bound components, we incorporate W8A16 (8-bit weight, 16-bit activation) weight-only quantization to alleviate memory bandwidth bottlenecks and achieve additional acceleration. We conduct extensive offline evaluations and large-scale online A/B experiments at ByteDance, demonstrating that UG-Sep reduces inference latency by up to 20 percent without degrading online user experience or commercial metrics across multiple business scenarios, including feed recommendation and advertising systems.
MSN: A Memory-based Sparse Activation Scaling Framework for Large-scale Industrial Recommendation
Feb 07, 2026Scaling deep learning recommendation models is an effective way to improve model expressiveness. Existing approaches often incur substantial computational overhead, making them difficult to deploy in large-scale industrial systems under strict latency constraints. Recent sparse activation scaling methods, such as Sparse Mixture-of-Experts, reduce computation by activating only a subset of parameters, but still suffer from high memory access costs and limited personalization capacity due to the large size and small number of experts. To address these challenges, we propose MSN, a memory-based sparse activation scaling framework for recommendation models. MSN dynamically retrieves personalized representations from a large parameterized memory and integrates them into downstream feature interaction modules via a memory gating mechanism, enabling fine-grained personalization with low computational overhead. To enable further expansion of the memory capacity while keeping both computational and memory access costs under control, MSN adopts a Product-Key Memory (PKM) mechanism, which factorizes the memory retrieval complexity from linear time to sub-linear complexity. In addition, normalization and over-parameterization techniques are introduced to maintain balanced memory utilization and prevent memory retrieval collapse. We further design customized Sparse-Gather operator and adopt the AirTopK operator to improve training and inference efficiency in industrial settings. Extensive experiments demonstrate that MSN consistently improves recommendation performance while maintaining high efficiency. Moreover, MSN has been successfully deployed in the Douyin Search Ranking System, achieving significant gains over deployed state-of-the-art models in both offline evaluation metrics and large-scale online A/B test.
TokenMixer-Large: Scaling Up Large Ranking Models in Industrial Recommenders
Feb 06, 2026In recent years, the study of scaling laws for large recommendation models has gradually gained attention. Works such as Wukong, HiFormer, and DHEN have attempted to increase the complexity of interaction structures in ranking models and validate scaling laws between performance and parameters/FLOPs by stacking multiple layers. However, their experimental scale remains relatively limited. Our previous work introduced the TokenMixer architecture, an efficient variant of the standard Transformer where the self-attention mechanism is replaced by a simple reshape operation, and the feed-forward network is adapted to a pertoken FFN. The effectiveness of this architecture was demonstrated in the ranking stage by the model presented in the RankMixer paper. However, this foundational TokenMixer architecture itself has several design limitations. In this paper, we propose TokenMixer-Large, which systematically addresses these core issues: sub-optimal residual design, insufficient gradient updates in deep models, incomplete MoE sparsification, and limited exploration of scalability. By leveraging a mixing-and-reverting operation, inter-layer residuals, the auxiliary loss and a novel Sparse-Pertoken MoE architecture, TokenMixer-Large successfully scales its parameters to 7-billion and 15-billion on online traffic and offline experiments, respectively. Currently deployed in multiple scenarios at ByteDance, TokenMixer -Large has achieved significant offline and online performance gains.
Make Anything Match Your Target: Universal Adversarial Perturbations against Closed-Source MLLMs via Multi-Crop Routed Meta Optimization
Jan 30, 2026Targeted adversarial attacks on closed-source multimodal large language models (MLLMs) have been increasingly explored under black-box transfer, yet prior methods are predominantly sample-specific and offer limited reusability across inputs. We instead study a more stringent setting, Universal Targeted Transferable Adversarial Attacks (UTTAA), where a single perturbation must consistently steer arbitrary inputs toward a specified target across unknown commercial MLLMs. Naively adapting existing sample-wise attacks to this universal setting faces three core difficulties: (i) target supervision becomes high-variance due to target-crop randomness, (ii) token-wise matching is unreliable because universality suppresses image-specific cues that would otherwise anchor alignment, and (iii) few-source per-target adaptation is highly initialization-sensitive, which can degrade the attainable performance. In this work, we propose MCRMO-Attack, which stabilizes supervision via Multi-Crop Aggregation with an Attention-Guided Crop, improves token-level reliability through alignability-gated Token Routing, and meta-learns a cross-target perturbation prior that yields stronger per-target solutions. Across commercial MLLMs, we boost unseen-image attack success rate by +23.7\% on GPT-4o and +19.9\% on Gemini-2.0 over the strongest universal baseline.
From Pretrain to Pain: Adversarial Vulnerability of Video Foundation Models Without Task Knowledge
Nov 10, 2025Large-scale Video Foundation Models (VFMs) has significantly advanced various video-related tasks, either through task-specific models or Multi-modal Large Language Models (MLLMs). However, the open accessibility of VFMs also introduces critical security risks, as adversaries can exploit full knowledge of the VFMs to launch potent attacks. This paper investigates a novel and practical adversarial threat scenario: attacking downstream models or MLLMs fine-tuned from open-source VFMs, without requiring access to the victim task, training data, model query, and architecture. In contrast to conventional transfer-based attacks that rely on task-aligned surrogate models, we demonstrate that adversarial vulnerabilities can be exploited directly from the VFMs. To this end, we propose the Transferable Video Attack (TVA), a temporal-aware adversarial attack method that leverages the temporal representation dynamics of VFMs to craft effective perturbations. TVA integrates a bidirectional contrastive learning mechanism to maximize the discrepancy between the clean and adversarial features, and introduces a temporal consistency loss that exploits motion cues to enhance the sequential impact of perturbations. TVA avoids the need to train expensive surrogate models or access to domain-specific data, thereby offering a more practical and efficient attack strategy. Extensive experiments across 24 video-related tasks demonstrate the efficacy of TVA against downstream models and MLLMs, revealing a previously underexplored security vulnerability in the deployment of video models.
FOAM: A General Frequency-Optimized Anti-Overlapping Framework for Overlapping Object Perception
Jun 16, 2025Overlapping object perception aims to decouple the randomly overlapping foreground-background features, extracting foreground features while suppressing background features, which holds significant application value in fields such as security screening and medical auxiliary diagnosis. Despite some research efforts to tackle the challenge of overlapping object perception, most solutions are confined to the spatial domain. Through frequency domain analysis, we observe that the degradation of contours and textures due to the overlapping phenomenon can be intuitively reflected in the magnitude spectrum. Based on this observation, we propose a general Frequency-Optimized Anti-Overlapping Framework (FOAM) to assist the model in extracting more texture and contour information, thereby enhancing the ability for anti-overlapping object perception. Specifically, we design the Frequency Spatial Transformer Block (FSTB), which can simultaneously extract features from both the frequency and spatial domains, helping the network capture more texture features from the foreground. In addition, we introduce the Hierarchical De-Corrupting (HDC) mechanism, which aligns adjacent features in the separately constructed base branch and corruption branch using a specially designed consistent loss during the training phase. This mechanism suppresses the response to irrelevant background features of FSTBs, thereby improving the perception of foreground contour. We conduct extensive experiments to validate the effectiveness and generalization of the proposed FOAM, which further improves the accuracy of state-of-the-art models on four datasets, specifically for the three overlapping object perception tasks: Prohibited Item Detection, Prohibited Item Segmentation, and Pneumonia Detection. The code will be open source once the paper is accepted.
SCORPIO: Serving the Right Requests at the Right Time for Heterogeneous SLOs in LLM Inference
May 29, 2025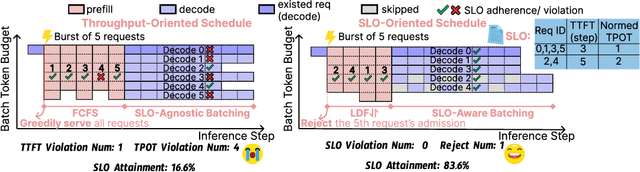
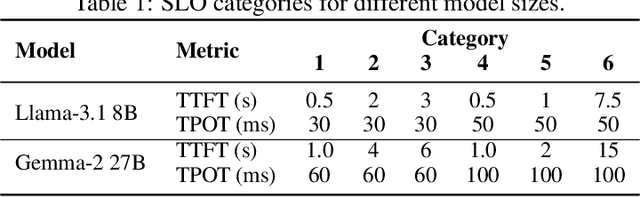
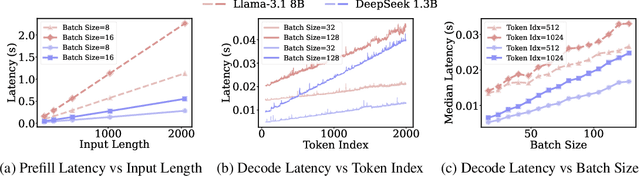
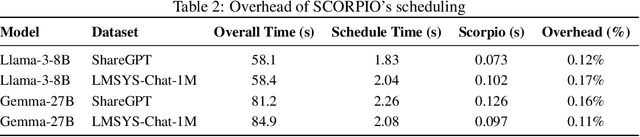
Existing Large Language Model (LLM) serving systems prioritize maximum throughput. They often neglect Service Level Objectives (SLOs) such as Time to First Token (TTFT) and Time Per Output Token (TPOT), which leads to suboptimal SLO attainment. This paper introduces SCORPIO, an SLO-oriented LLM serving system designed to maximize system goodput and SLO attainment for workloads with heterogeneous SLOs. Our core insight is to exploit SLO heterogeneity for adaptive scheduling across admission control, queue management, and batch selection. SCORPIO features a TTFT Guard, which employs least-deadline-first reordering and rejects unattainable requests, and a TPOT Guard, which utilizes a VBS-based admission control and a novel credit-based batching mechanism. Both guards are supported by a predictive module. Evaluations demonstrate that SCORPIO improves system goodput by up to 14.4X and SLO adherence by up to 46.5% compared to state-of-the-art baselines.
LONGER: Scaling Up Long Sequence Modeling in Industrial Recommenders
May 07, 2025

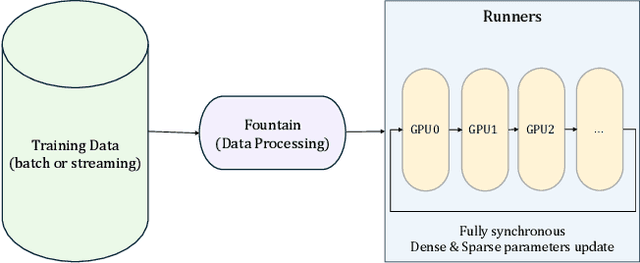
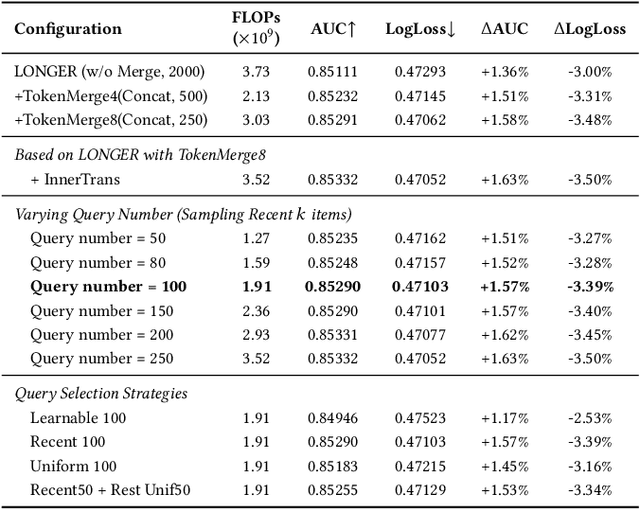
Modeling ultra-long user behavior sequences is critical for capturing both long- and short-term preferences in industrial recommender systems. Existing solutions typically rely on two-stage retrieval or indirect modeling paradigms, incuring upstream-downstream inconsistency and computational inefficiency. In this paper, we present LONGER, a Long-sequence Optimized traNsformer for GPU-Efficient Recommenders. LONGER incorporates (i) a global token mechanism for stabilizing attention over long contexts, (ii) a token merge module with lightweight InnerTransformers and hybrid attention strategy to reduce quadratic complexity, and (iii) a series of engineering optimizations, including training with mixed-precision and activation recomputation, KV cache serving, and the fully synchronous model training and serving framework for unified GPU-based dense and sparse parameter updates. LONGER consistently outperforms strong baselines in both offline metrics and online A/B testing in both advertising and e-commerce services at ByteDance, validating its consistent effectiveness and industrial-level scaling laws. Currently, LONGER has been fully deployed at more than 10 influential scenarios at ByteDance, serving billion users.