 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Memory Network for Recommendation
Feb 08, 2025



Modeling user behavior sequences in recommender systems is essential for understanding user preferences over time, enabling personalized and accurate recommendations for improving user retention and enhancing business values. Despite its significance, there are two challenges for current sequential modeling approaches. From the spatial dimension, it is difficult to mutually perceive similar users' interests for a generalized intention understanding; from the temporal dimension, current methods are generally prone to forgetting long-term interests due to the fixed-length input sequence. In this paper, we present Large Memory Network (LMN), providing a novel idea by compressing and storing user history behavior information in a large-scale memory block. With the elaborated online deployment strategy, the memory block can be easily scaled up to million-scale in the industry. Extensive offline comparison experiments, memory scaling up experiments, and online A/B test on Douyin E-Commerce Search (ECS) are performed, validating the superior performance of LMN. Currently, LMN has been fully deployed in Douyin ECS, serving millions of users each day.
Distributed Hierarchical GPU Parameter Server for Massive Scale Deep Learning Ads Systems
Mar 12, 2020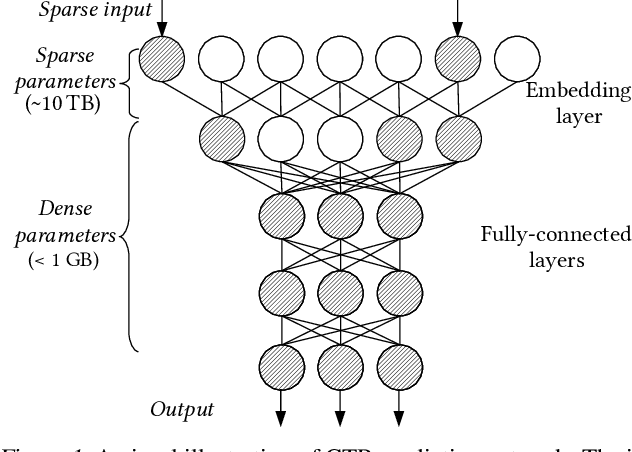

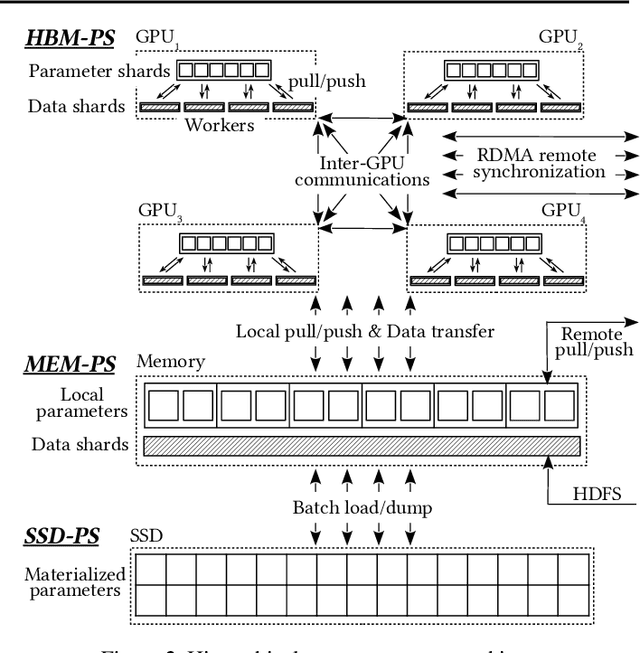

Neural networks of ads systems usually take input from multiple resources, e.g., query-ad relevance, ad features and user portraits. These inputs are encoded into one-hot or multi-hot binary features, with typically only a tiny fraction of nonzero feature values per example. Deep learning models in online advertising industries can have terabyte-scale parameters that do not fit in the GPU memory nor the CPU main memory on a computing node. For example, a sponsored online advertising system can contain more than $10^{11}$ sparse features, making the neural network a massive model with around 10 TB parameters. In this paper, we introduce a distributed GPU hierarchical parameter server for massive scale deep learning ads systems. We propose a hierarchical workflow that utilizes GPU High-Bandwidth Memory, CPU main memory and SSD as 3-layer hierarchical storage. All the neural network training computations are contained in GPUs. Extensive experiments on real-world data confirm the effectiveness and the scalability of the proposed system. A 4-node hierarchical GPU parameter server can train a model more than 2X faster than a 150-node in-memory distributed parameter server in an MPI cluster. In addition, the price-performance ratio of our proposed system is 4-9 times better than an MPI-cluster solution.