 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Distance Measurement based on Multi-Kernel Gaussian Processes
Dec 13, 2025Semantic distance measurement is a fundamental problem in computational linguistics, providing a quantitative characterization of similarity or relatedness between text segments, and underpinning tasks such as text retrieval and text classification. From a mathematical perspective, a semantic distance can be viewed as a metric defined on a space of texts or on a representation space derived from them. However, most classical semantic distance methods are essentially fixed, making them difficult to adapt to specific data distributions and task requirements. In this paper, a semantic distance measure based on multi-kernel Gaussian processes (MK-GP) was proposed. The latent semantic function associated with texts was modeled as a Gaussian process, with its covariance function given by a combined kernel combining Matérn and polynomial components. The kernel parameters were learned automatically from data under supervision, rather than being hand-crafted. This semantic distance was instantiated and evaluated in the context of fine-grained sentiment classification with large language models under an in-context learning (ICL) setup. The experimental results demonstrated the effectiveness of the proposed measure.
Tool Graph Retriever: Exploring Dependency Graph-based Tool Retrieval for Large Language Models
Aug 07, 2025With the remarkable advancement of AI agents, the number of their equipped tools is increasing rapidly. However, integrating all tool information into the limited model context becomes impractical, highlighting the need for efficient tool retrieval methods. In this regard, dominant methods primarily rely on semantic similarities between tool descriptions and user queries to retrieve relevant tools. However, they often consider each tool independently, overlooking dependencies between tools, which may lead to the omission of prerequisite tools for successful task execution. To deal with this defect, in this paper, we propose Tool Graph Retriever (TGR), which exploits the dependencies among tools to learn better tool representations for retrieval. First, we construct a dataset termed TDI300K to train a discriminator for identifying tool dependencies. Then, we represent all candidate tools as a tool dependency graph and use graph convolution to integrate the dependencies into their representations. Finally, these updated tool representations are employed for online retrieval. Experimental results on several commonly used datasets show that our TGR can bring a performance improvement to existing dominant methods, achieving SOTA performance. Moreover, in-depth analyses also verify the importance of tool dependencies and the effectiveness of our TGR.
Learning from Ambiguous Data with Hard Labels
Jan 08, 2025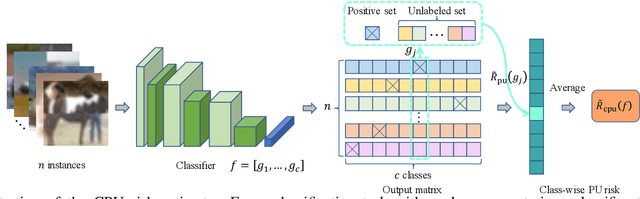

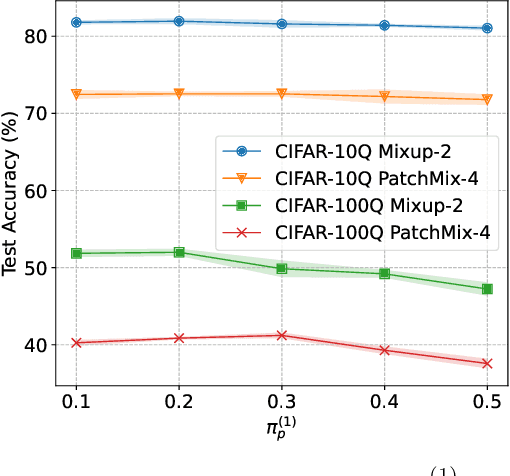
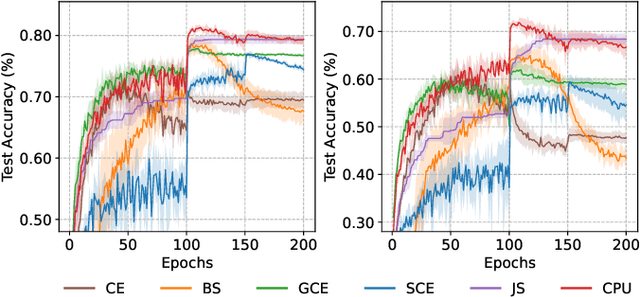
Real-world data often contains intrinsic ambiguity that the common single-hard-label annotation paradigm ignores. Standard training using ambiguous data with these hard labels may produce overly confident models and thus leading to poor generalization. In this paper, we propose a novel framework called Quantized Label Learning (QLL) to alleviate this issue. First, we formulate QLL as learning from (very) ambiguous data with hard labels: ideally, each ambiguous instance should be associated with a ground-truth soft-label distribution describing its corresponding probabilistic weight in each class, however, this is usually not accessible; in practice, we can only observe a quantized label, i.e., a hard label sampled (quantized) from the corresponding ground-truth soft-label distribution, of each instance, which can be seen as a biased approximation of the ground-truth soft-label. Second, we propose a Class-wise Positive-Unlabeled (CPU) risk estimator that allows us to train accurate classifiers from only ambiguous data with quantized labels. Third, to simulate ambiguous datasets with quantized labels in the real world, we design a mixing-based ambiguous data generation procedure for empirical evaluation. Experiments demonstrate that our CPU method can significantly improve model generalization performance and outperform the baselines.
One2set + Large Language Model: Best Partners for Keyphrase Generation
Oct 04, 2024


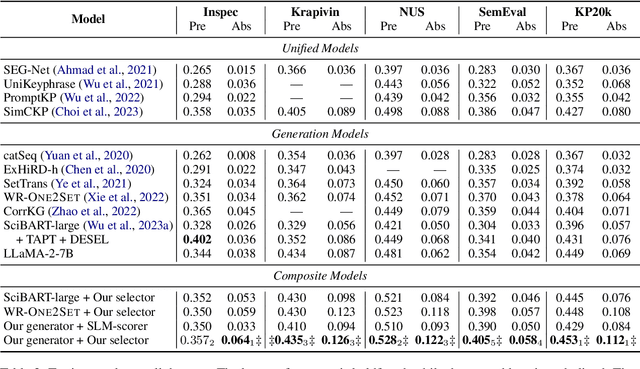
Keyphrase generation (KPG) aims to automatically generate a collection of phrases representing the core concepts of a given document. The dominant paradigms in KPG include one2seq and one2set. Recently, there has been increasing interest in applying large language models (LLMs) to KPG. Our preliminary experiments reveal that it is challenging for a single model to excel in both recall and precision. Further analysis shows that: 1) the one2set paradigm owns the advantage of high recall, but suffers from improper assignments of supervision signals during training; 2) LLMs are powerful in keyphrase selection, but existing selection methods often make redundant selections. Given these observations, we introduce a generate-then-select framework decomposing KPG into two steps, where we adopt a one2set-based model as generator to produce candidates and then use an LLM as selector to select keyphrases from these candidates. Particularly, we make two important improvements on our generator and selector: 1) we design an Optimal Transport-based assignment strategy to address the above improper assignments; 2) we model the keyphrase selection as a sequence labeling task to alleviate redundant selections. Experimental results on multiple benchmark datasets show that our framework significantly surpasses state-of-the-art models, especially in absent keyphrase prediction.
Large Margin Prototypical Network for Few-shot Relation Classification with Fine-grained Features
Sep 06, 2024Relation classification (RC) plays a pivotal role in both natural language understanding and knowledge graph completion. It is generally formulated as a task to recognize the relationship between two entities of interest appearing in a free-text sentence. Conventional approaches on RC, regardless of feature engineering or deep learning based, can obtain promising performance on categorizing common types of relation leaving a large proportion of unrecognizable long-tail relations due to insufficient labeled instances for training. In this paper, we consider few-shot learning is of great practical significance to RC and thus improve a modern framework of metric learning for few-shot RC. Specifically, we adopt the large-margin ProtoNet with fine-grained features, expecting they can generalize well on long-tail relations. Extensive experiments were conducted by FewRel, a large-scale supervised few-shot RC dataset, to evaluate our framework: LM-ProtoNet (FGF). The results demonstrate that it can achieve substantial improvements over many baseline approaches.
MOBIUS: Towards the Next Generation of Query-Ad Matching in Baidu's Sponsored Search
Sep 05, 2024


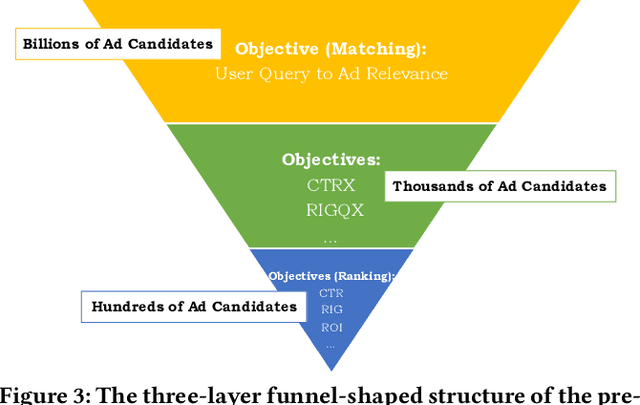
Baidu runs the largest commercial web search engine in China, serving hundreds of millions of online users every day in response to a great variety of queries. In order to build a high-efficiency sponsored search engine, we used to adopt a three-layer funnel-shaped structure to screen and sort hundreds of ads from billions of ad candidates subject to the requirement of low response latency and the restraints of computing resources. Given a user query, the top matching layer is responsible for providing semantically relevant ad candidates to the next layer, while the ranking layer at the bottom concerns more about business indicators (e.g., CPM, ROI, etc.) of those ads. The clear separation between the matching and ranking objectives results in a lower commercial return. The Mobius project has been established to address this serious issue. It is our first attempt to train the matching layer to consider CPM as an additional optimization objective besides the query-ad relevance, via directly predicting CTR (click-through rate) from billions of query-ad pairs. Specifically, this paper will elaborate on how we adopt active learning to overcome the insufficiency of click history at the matching layer when training our neural click networks offline, and how we use the SOTA ANN search technique for retrieving ads more efficiently (Here ``ANN'' stands for approximate nearest neighbor search). We contribute the solutions to Mobius-V1 as the first version of our next generation query-ad matching system.
VIP: Versatile Image Outpainting Empowered by Multimodal Large Language Model
Jun 03, 2024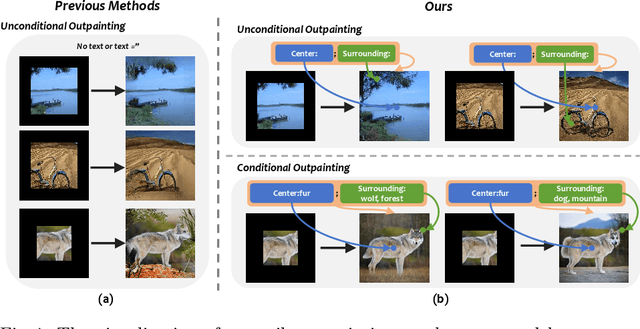
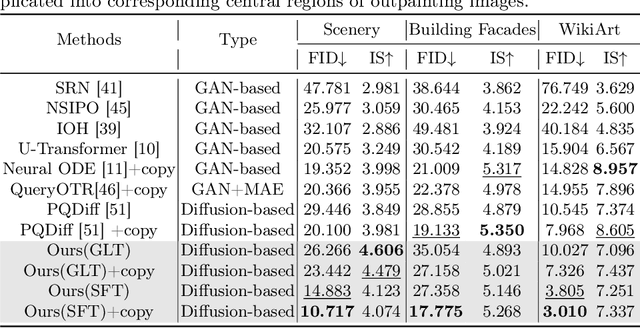
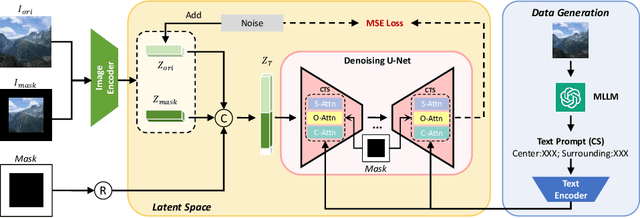
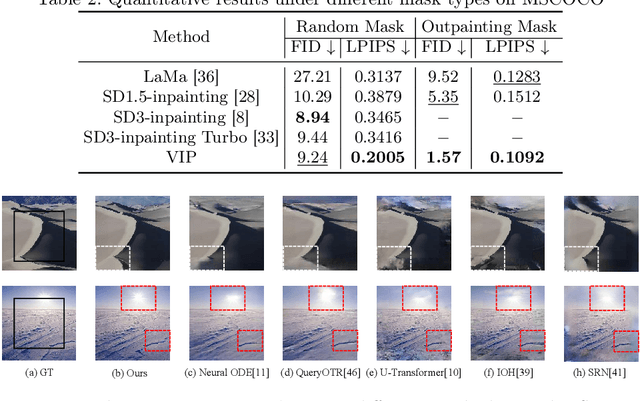
In this paper, we focus on resolving the problem of image outpainting, which aims to extrapolate the surrounding parts given the center contents of an image. Although recent works have achieved promising performance, the lack of versatility and customization hinders their practical applications in broader scenarios. Therefore, this work presents a novel image outpainting framework that is capable of customizing the results according to the requirement of users. First of all, we take advantage of a Multimodal Large Language Model (MLLM) that automatically extracts and organizes the corresponding textual descriptions of the masked and unmasked part of a given image. Accordingly, the obtained text prompts are introduced to endow our model with the capacity to customize the outpainting results. In addition, a special Cross-Attention module, namely Center-Total-Surrounding (CTS), is elaborately designed to enhance further the the interaction between specific space regions of the image and corresponding parts of the text prompts. Note that unlike most existing methods, our approach is very resource-efficient since it is just slightly fine-tuned on the off-the-shelf stable diffusion (SD) model rather than being trained from scratch. Finally, the experimental results on three commonly used datasets, i.e. Scenery, Building, and WikiArt, demonstrate our model significantly surpasses the SoTA methods. Moreover, versatile outpainting results are listed to show its customized ability.
SGD: Street View Synthesis with Gaussian Splatting and Diffusion Prior
Mar 29, 2024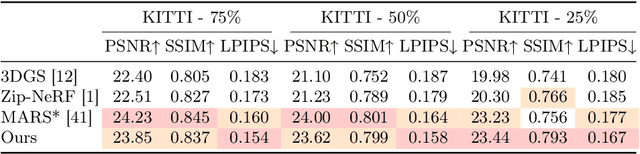
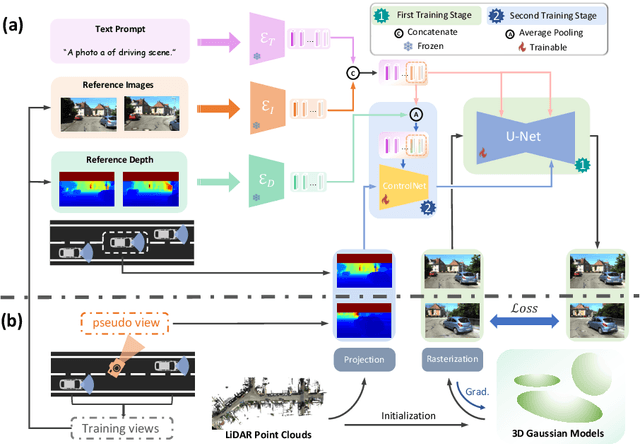
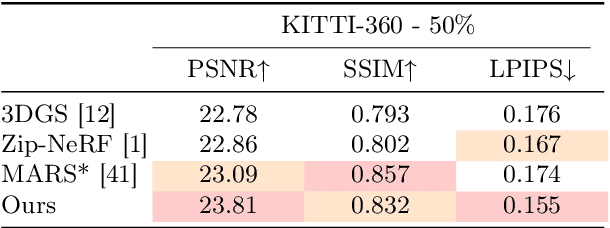
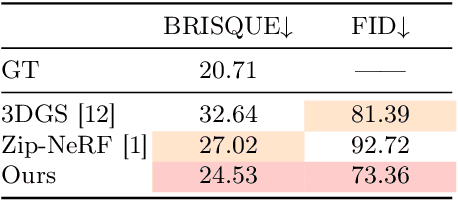
Novel View Synthesis (NVS) for street scenes play a critical role in the autonomous driving simulation. The current mainstream technique to achieve it is neural rendering, such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS). Although thrilling progress has been made, when handling street scenes, current methods struggle to maintain rendering quality at the viewpoint that deviates significantly from the training viewpoints. This issue stems from the sparse training views captured by a fixed camera on a moving vehicle. To tackle this problem, we propose a novel approach that enhances the capacity of 3DGS by leveraging prior from a Diffusion Model along with complementary multi-modal data. Specifically, we first fine-tune a Diffusion Model by adding images from adjacent frames as condition, meanwhile exploiting depth data from LiDAR point clouds to supply additional spatial information. Then we apply the Diffusion Model to regularize the 3DGS at unseen views during training. Experimental results validate the effectiveness of our method compared with current state-of-the-art models, and demonstrate its advance in rendering images from broader views.
Neural Field Classifiers via Target Encoding and Classification Loss
Mar 02, 2024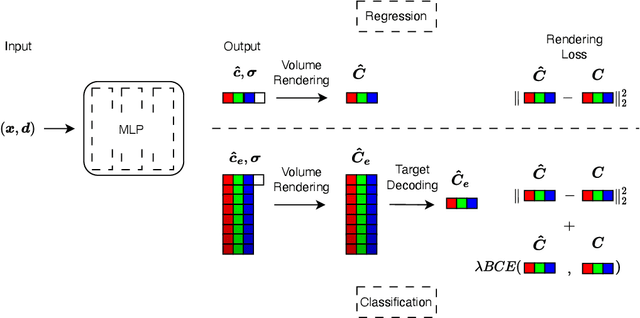
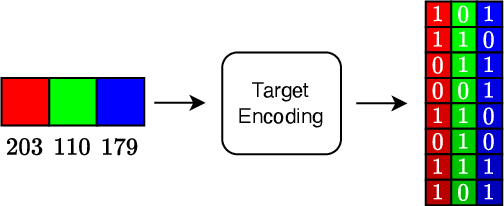

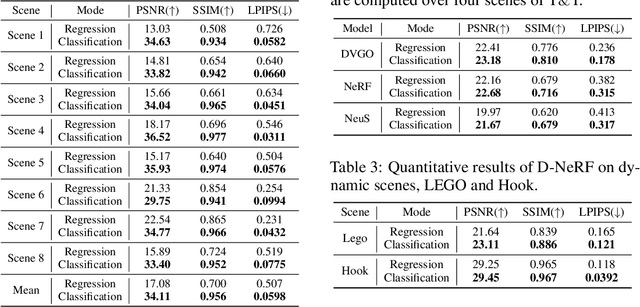
Neural field methods have seen great progress in various long-standing tasks in computer vision and computer graphics, including novel view synthesis and geometry reconstruction. As existing neural field methods try to predict some coordinate-based continuous target values, such as RGB for Neural Radiance Field (NeRF), all of these methods are regression models and are optimized by some regression loss. However, are regression models really better than classification models for neural field methods? In this work, we try to visit this very fundamental but overlooked question for neural fields from a machine learning perspective. We successfully propose a novel Neural Field Classifier (NFC) framework which formulates existing neural field methods as classification tasks rather than regression tasks. The proposed NFC can easily transform arbitrary Neural Field Regressor (NFR) into its classification variant via employing a novel Target Encoding module and optimizing a classification loss. By encoding a continuous regression target into a high-dimensional discrete encoding, we naturally formulate a multi-label classification task. Extensive experiments demonstrate the impressive effectiveness of NFC at the nearly free extra computational costs. Moreover, NFC also shows robustness to sparse inputs, corrupted images, and dynamic scenes.
MQuinE: a cure for "Z-paradox" in knowledge graph embedding models
Feb 07, 2024



Knowledge graph embedding (KGE) models achieved state-of-the-art results on many knowledge graph tasks including link prediction and information retrieval. Despite the superior performance of KGE models in practice, we discover a deficiency in the expressiveness of some popular existing KGE models called \emph{Z-paradox}. Motivated by the existence of Z-paradox, we propose a new KGE model called \emph{MQuinE} that does not suffer from Z-paradox while preserves strong expressiveness to model various relation patterns including symmetric/asymmetric, inverse, 1-N/N-1/N-N, and composition relations with theoretical justification. Experiments on real-world knowledge bases indicate that Z-paradox indeed degrades the performance of existing KGE models, and can cause more than 20\% accuracy drop on some challenging test samples. Our experiments further demonstrate that MQuinE can mitigate the negative impact of Z-paradox and outperform existing KGE models by a visible margin on link prediction tasks.