 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Verifiable Agentic Data Science: Solving Irregular TSQA Via Tool-Grounded Reasoning
Jun 13, 2026Time series data in real-world deployments is overwhelmingly irregular. Observations are asynchronous, missing values are informative rather than random, and sampling frequencies vary across sensors and operational windows. However, existing Time Series Question Answering (TSQA) benchmarks mostly assume regularly sampled inputs, leaving a fundamental gap in understanding how large language models (LLMs) and AI agents perform under irregular conditions. To bridge this gap, we introduce IRTS-ToolBench, a benchmark of 1,700 questions spanning 10 task types across 13 domains. IRTS-ToolBench is designed to be used independently by any researcher working on LLM-based irregular time series analysis, providing standardized inputs and a reproducible evaluation protocol. Code can be found in https://github.com/SanhornC/IRTS-ToolBench.
FAIR-Calib: Frontier-Aware Instability-Reweighted Calibration for Post-Training Quantization of Diffusion Large Language Models
Jun 04, 2026Diffusion Large Language Models (dLLMs) refine tokens iteratively but commit them irreversibly, leading to a "stability lag" where early decisions remain fragile even after being written. We reveal that Post-Training Quantization (PTQ) error easily flips these borderline decisions at the write frontier, which are then permanently locked in and amplified. To address this, we propose Frontier-Aware Instability-Reweighted Calibration (FAIR-Calib), a two-stage PTQ framework for dLLMs. Stage I probes a full-precision teacher to estimate a position prior that combines frontier hits and masked-stage reliability. Stage II performs off-policy, layer-wise calibration by minimizing a reweighted hidden-state MSE, effectively prioritizing the protection of fragile frontier states without requiring expensive end-to-end diffusion rollouts. We further theoretically justify our weighted objective as a surrogate for output KL divergence. Empirically, FAIR-Calib consistently outperforms state-of-the-art baselines on LLaDA and Dream (W4A4), significantly reducing frontier decision flips and suppressing post-commit mismatches across diverse benchmarks.
MambaRain: Multi-Scale Mamba-Attention Framework for 0-3 Hour Precipitation Nowcasting
May 14, 2026Accurate precipitation nowcasting over extended horizons (0-3 hours) is essential for disaster mitigation and operational decision-making, yet remains a critical challenge in the field. Existing deterministic approaches are predominantly constrained to shorter prediction windows (0-2 hours), exhibiting severe performance degradation beyond 90 minutes owing to their inherent difficulty in capturing long-range spatiotemporal dependencies from radar-derived observations. To address these fundamental limitations, we propose MambaRain, a novel multi-scale encoder-decoder architecture that synergistically integrates Mamba's linear-complexity long-range temporal modeling with self-attention mechanisms for explicit spatial correlation capture. The core innovation lies in a hybrid design paradigm wherein Mamba blocks leverage selective state space mechanisms to model global temporal dynamics across extended sequences with computational efficiency, while self-attention modules explicitly characterize spatial correlations within precipitation fields - a capability inherently absent in Mamba's sequential processing paradigm. This complementary synergy enables comprehensive spatiotemporal representation learning, effectively extending the viable forecasting horizon to 2-3 hours with substantial accuracy improvements. Furthermore, we introduce a spectral loss formulation to mitigate blurring artifacts characteristic of chaotic precipitation systems, thereby preserving fine-scale motion details critical for nowcasting accuracy. Experimental validation demonstrates that MambaRain substantially outperforms existing deterministic methodologies in 0-3 hour nowcasting tasks, with particularly pronounced performance gains in the challenging 2-3 hour prediction range.
VMU-Diff: A Coarse-to-fine Multi-source Data Fusion Framework for Precipitation Nowcasting
May 14, 2026Precipitation nowcasting is a vital spatio-temporal prediction task for meteorological applications but faces challenges due to the chaotic property of precipitation systems. Existing methods predominantly rely on single-source radar data to build either deterministic or probabilistic models for extrapolation. However, the single deterministic model suffers from blurring due to MSE convergence. The single probabilistic model, typically represented by diffusion models, can generate fine details but suffers from spurious artifacts that compromise accuracy and computational inefficiency. To address these challenges, this paper proposes a novel coarse-to-fine Vision Mamba Unet and residual Diffusion (VMU-Diff) based precipitation nowcasting framework. It realizes precipitation nowcasting through a two-stage process, i.e., a deterministic model-based coarse stage to predict global motion trends and a probabilistic model-based fine stage to generate fine prediction details. In the coarse prediction stage, rather than single-source radar data, both radar and multi-band satellite data are taken as input. A spatial-temporal attention block and several Vision mamba state-space blocks realize multi-source data fusion, and predict the future echo global dynamics. The fine-grained stage is realized by a spatio-temporal refine generator based on residual conditional diffusion models. It first obtains spatio-temporal residual features based on coarse prediction and ground truth, and further reconstructs the residual via conditional Mamba state-space module. Experiments on Jiangsu SWAN datasets demonstrate the improvements of our method over state-of-the-art methods, particularly in short-term forecasts.
Motion Manipulation via Unsupervised Keypoint Positioning in Face Animation
Mar 04, 2026Face animation deals with controlling and generating facial features with a wide range of applications. The methods based on unsupervised keypoint positioning can produce realistic and detailed virtual portraits. However, they cannot achieve controllable face generation since the existing keypoint decomposition pipelines fail to fully decouple identity semantics and intertwined motion information (e.g., rotation, translation, and expression). To address these issues, we present a new method, Motion Manipulation via unsupervised keypoint positioning in Face Animation (MMFA). We first introduce self-supervised representation learning to encode and decode expressions in the latent feature space and decouple them from other motion information. Secondly, we propose a new way to compute keypoints aiming to achieve arbitrary motion control. Moreover, we design a variational autoencoder to map expression features to a continuous Gaussian distribution, allowing us for the first time to interpolate facial expressions in an unsupervised framework. We have conducted extensive experiments on publicly available datasets to validate the effectiveness of MMFA, which show that MMFA offers pronounced advantages over prior arts in creating realistic animation and manipulating face motion.
TSAQA: Time Series Analysis Question And Answering Benchmark
Jan 30, 2026Time series data are integral to critical applications across domains such as finance, healthcare, transportation, and environmental science. While recent work has begun to explore multi-task time series question answering (QA), current benchmarks remain limited to forecasting and anomaly detection tasks. We introduce TSAQA, a novel unified benchmark designed to broaden task coverage and evaluate diverse temporal analysis capabilities. TSAQA integrates six diverse tasks under a single framework ranging from conventional analysis, including anomaly detection and classification, to advanced analysis, such as characterization, comparison, data transformation, and temporal relationship analysis. Spanning 210k samples across 13 domains, the dataset employs diverse formats, including true-or-false (TF), multiple-choice (MC), and a novel puzzling (PZ), to comprehensively assess time series analysis. Zero-shot evaluation demonstrates that these tasks are challenging for current Large Language Models (LLMs): the best-performing commercial LLM, Gemini-2.5-Flash, achieves an average score of only 65.08. Although instruction tuning boosts open-source performance: the best-performing open-source model, LLaMA-3.1-8B, shows significant room for improvement, highlighting the complexity of temporal analysis for LLMs.
Neural Field Classifiers via Target Encoding and Classification Loss
Mar 02, 2024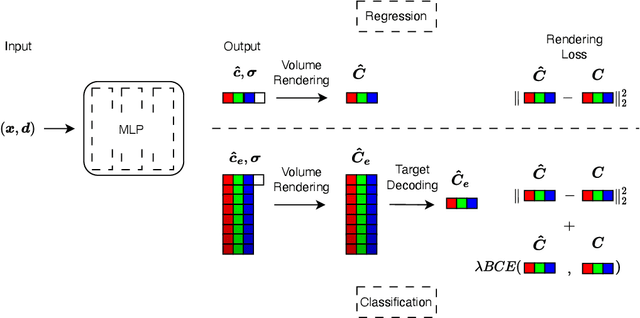
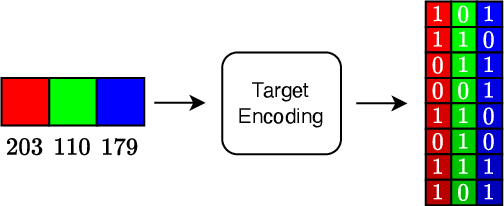

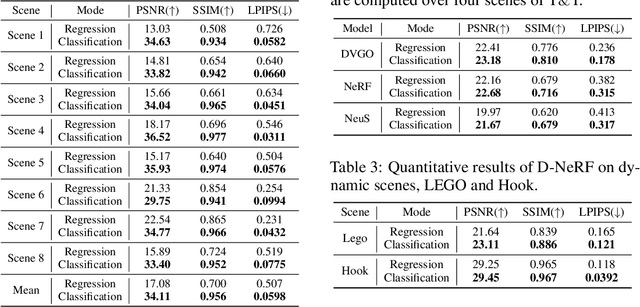
Neural field methods have seen great progress in various long-standing tasks in computer vision and computer graphics, including novel view synthesis and geometry reconstruction. As existing neural field methods try to predict some coordinate-based continuous target values, such as RGB for Neural Radiance Field (NeRF), all of these methods are regression models and are optimized by some regression loss. However, are regression models really better than classification models for neural field methods? In this work, we try to visit this very fundamental but overlooked question for neural fields from a machine learning perspective. We successfully propose a novel Neural Field Classifier (NFC) framework which formulates existing neural field methods as classification tasks rather than regression tasks. The proposed NFC can easily transform arbitrary Neural Field Regressor (NFR) into its classification variant via employing a novel Target Encoding module and optimizing a classification loss. By encoding a continuous regression target into a high-dimensional discrete encoding, we naturally formulate a multi-label classification task. Extensive experiments demonstrate the impressive effectiveness of NFC at the nearly free extra computational costs. Moreover, NFC also shows robustness to sparse inputs, corrupted images, and dynamic scenes.
MFMAN-YOLO: A Method for Detecting Pole-like Obstacles in Complex Environment
Jul 24, 2023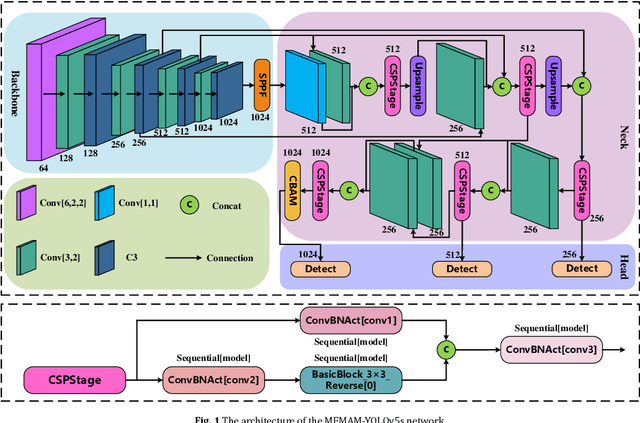
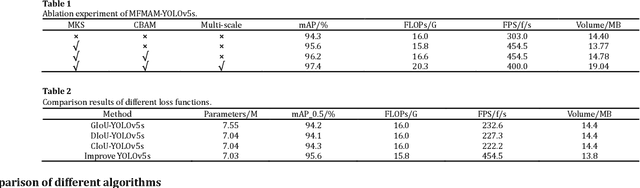
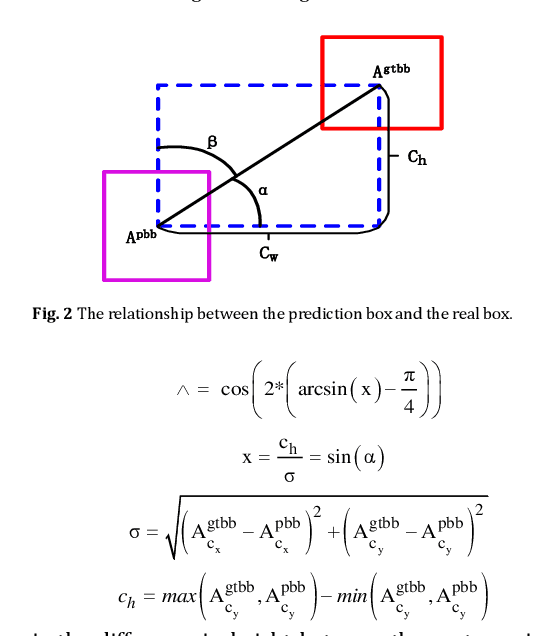
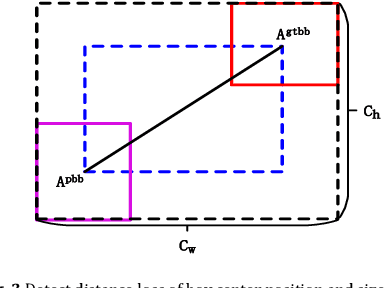
In real-world traffic, there are various uncertainties and complexities in road and weather conditions. To solve the problem that the feature information of pole-like obstacles in complex environments is easily lost, resulting in low detection accuracy and low real-time performance, a multi-scale hybrid attention mechanism detection algorithm is proposed in this paper. First, the optimal transport function Monge-Kantorovich (MK) is incorporated not only to solve the problem of overlapping multiple prediction frames with optimal matching but also the MK function can be regularized to prevent model over-fitting; then, the features at different scales are up-sampled separately according to the optimized efficient multi-scale feature pyramid. Finally, the extraction of multi-scale feature space channel information is enhanced in complex environments based on the hybrid attention mechanism, which suppresses the irrelevant complex environment background information and focuses the feature information of pole-like obstacles. Meanwhile, this paper conducts real road test experiments in a variety of complex environments. The experimental results show that the detection precision, recall, and average precision of the method are 94.7%, 93.1%, and 97.4%, respectively, and the detection frame rate is 400 f/s. This research method can detect pole-like obstacles in a complex road environment in real time and accurately, which further promotes innovation and progress in the field of automatic driving.
Face Animation with an Attribute-Guided Diffusion Model
Apr 06, 2023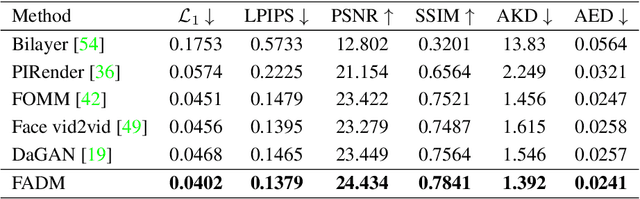
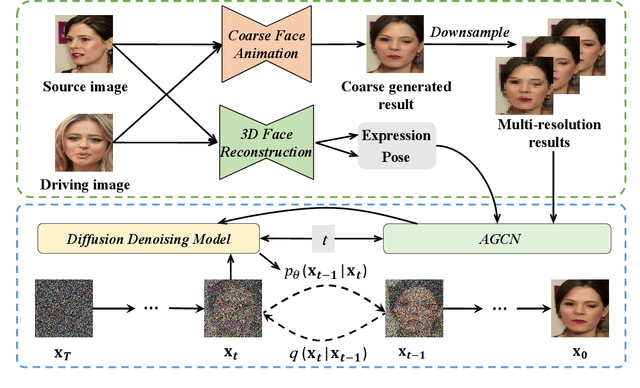
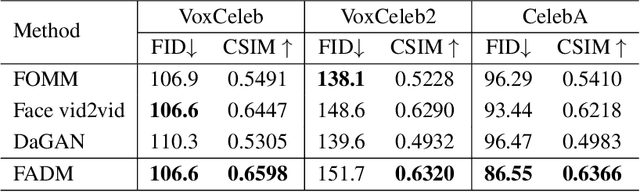
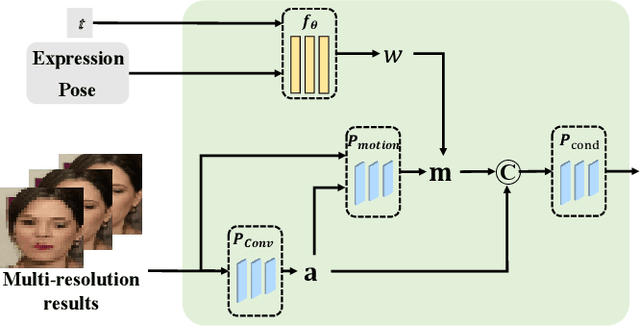
Face animation has achieved much progress in computer vision. However, prevailing GAN-based methods suffer from unnatural distortions and artifacts due to sophisticated motion deformation. In this paper, we propose a Face Animation framework with an attribute-guided Diffusion Model (FADM), which is the first work to exploit the superior modeling capacity of diffusion models for photo-realistic talking-head generation. To mitigate the uncontrollable synthesis effect of the diffusion model, we design an Attribute-Guided Conditioning Network (AGCN) to adaptively combine the coarse animation features and 3D face reconstruction results, which can incorporate appearance and motion conditions into the diffusion process. These specific designs help FADM rectify unnatural artifacts and distortions, and also enrich high-fidelity facial details through iterative diffusion refinements with accurate animation attributes. FADM can flexibly and effectively improve existing animation videos. Extensive experiments on widely used talking-head benchmarks validate the effectiveness of FADM over prior arts.
Cybersecurity Challenges of Power Transformers
Feb 25, 2023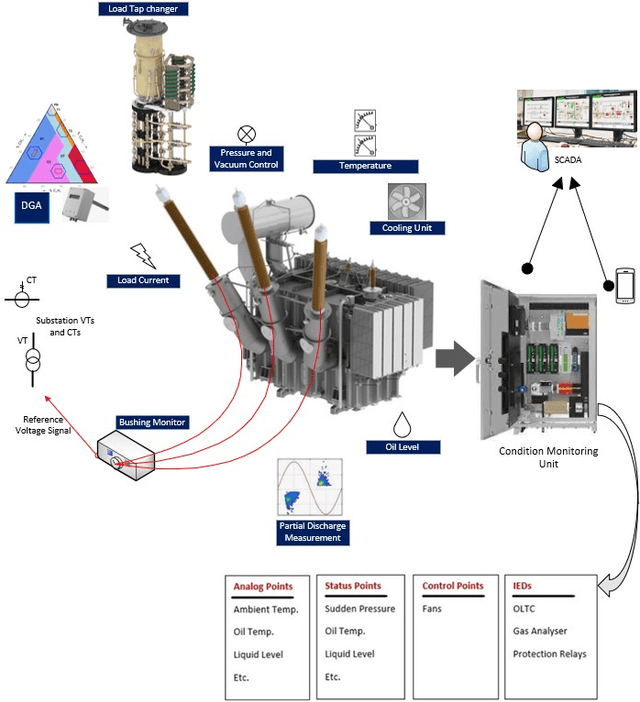
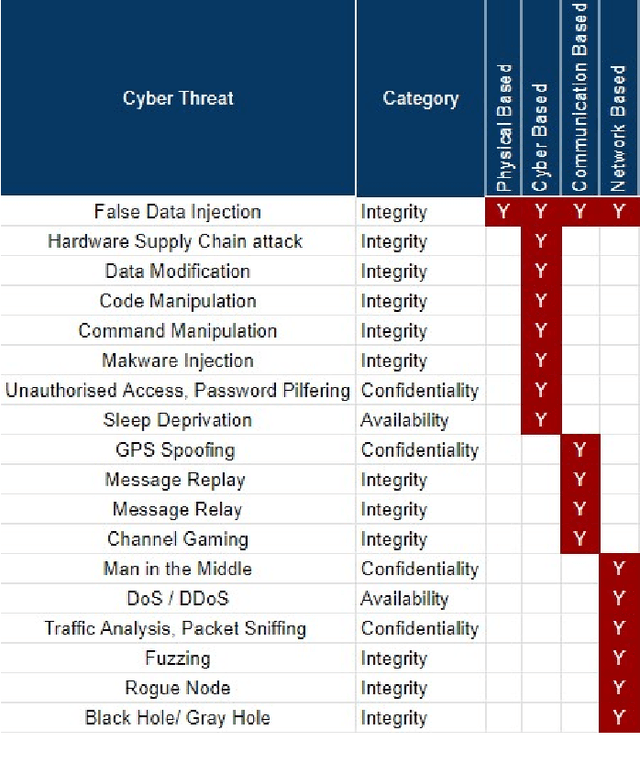
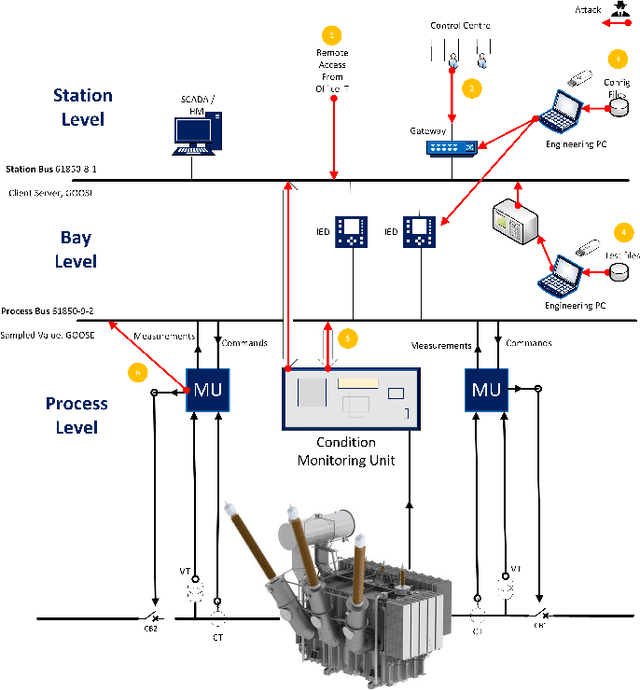
The rise of cyber threats on critical infrastructure and its potential for devastating consequences, has significantly increased. The dependency of new power grid technology on information, data analytic and communication systems make the entire electricity network vulnerable to cyber threats. Power transformers play a critical role within the power grid and are now commonly enhanced through factory add-ons or intelligent monitoring systems added later to improve the condition monitoring of critical and long lead time assets such as transformers. However, the increased connectivity of those power transformers opens the door to more cyber attacks. Therefore, the need to detect and prevent cyber threats is becoming critical. The first step towards that would be a deeper understanding of the potential cyber-attacks landscape against power transformers. Much of the existing literature pays attention to smart equipment within electricity distribution networks, and most methods proposed are based on model-based detection algorithms. Moreover, only a few of these works address the security vulnerabilities of power elements, especially transformers within the transmission network. To the best of our knowledge, there is no study in the literature that systematically investigate the cybersecurity challenges against the newly emerged smart transformers. This paper addresses this shortcoming by exploring the vulnerabilities and the attack vectors of power transformers within electricity networks, the possible attack scenarios and the risks associated with these attacks.