 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Semantic Consistency of Large Language Models through Model Editing: An Interpretability-Oriented Approach
Jan 19, 2025



A Large Language Model (LLM) tends to generate inconsistent and sometimes contradictory outputs when presented with a prompt that has equivalent semantics but is expressed differently from the original prompt. To achieve semantic consistency of an LLM, one of the key approaches is to finetune the model with prompt-output pairs with semantically equivalent meanings. Despite its effectiveness, a data-driven finetuning method incurs substantial computation costs in data preparation and model optimization. In this regime, an LLM is treated as a ``black box'', restricting our ability to gain deeper insights into its internal mechanism. In this paper, we are motivated to enhance the semantic consistency of LLMs through a more interpretable method (i.e., model editing) to this end. We first identify the model components (i.e., attention heads) that have a key impact on the semantic consistency of an LLM. We subsequently inject biases into the output of these model components along the semantic-consistency activation direction. It is noteworthy that these modifications are cost-effective, without reliance on mass manipulations of the original model parameters. Through comprehensive experiments on the constructed NLU and open-source NLG datasets, our method demonstrates significant improvements in the semantic consistency and task performance of LLMs. Additionally, our method exhibits promising generalization capabilities by performing well on tasks beyond the primary tasks.
A Survey on Hallucination in Large Vision-Language Models
Feb 01, 2024
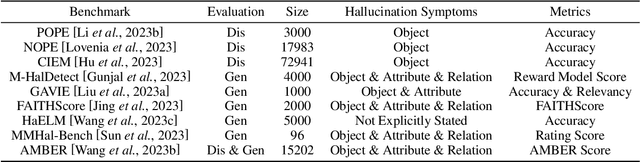
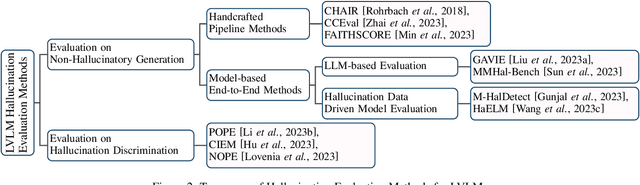
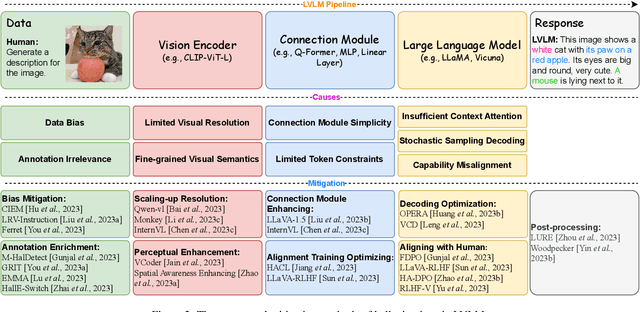
Recent development of Large Vision-Language Models (LVLMs) has attracted growing attention within the AI landscape for its practical implementation potential. However, ``hallucination'', or more specifically, the misalignment between factual visual content and corresponding textual generation, poses a significant challenge of utilizing LVLMs. In this comprehensive survey, we dissect LVLM-related hallucinations in an attempt to establish an overview and facilitate future mitigation. Our scrutiny starts with a clarification of the concept of hallucinations in LVLMs, presenting a variety of hallucination symptoms and highlighting the unique challenges inherent in LVLM hallucinations. Subsequently, we outline the benchmarks and methodologies tailored specifically for evaluating hallucinations unique to LVLMs. Additionally, we delve into an investigation of the root causes of these hallucinations, encompassing insights from the training data and model components. We also critically review existing methods for mitigating hallucinations. The open questions and future directions pertaining to hallucinations within LVLMs are discussed to conclude this survey.
Align before Adapt: Leveraging Entity-to-Region Alignments for Generalizable Video Action Recognition
Nov 27, 2023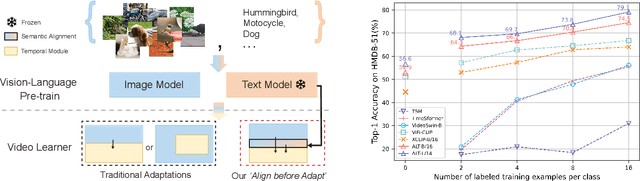
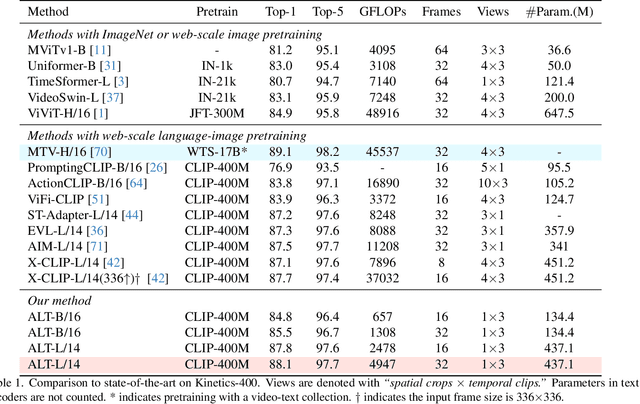
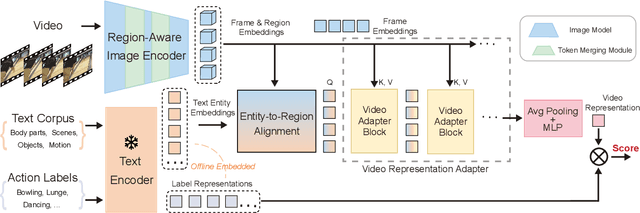
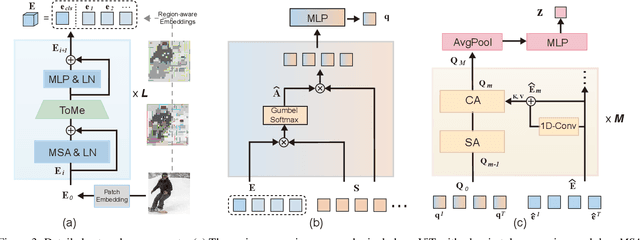
Large-scale visual-language pre-trained models have achieved significant success in various video tasks. However, most existing methods follow an "adapt then align" paradigm, which adapts pre-trained image encoders to model video-level representations and utilizes one-hot or text embedding of the action labels for supervision. This paradigm overlooks the challenge of mapping from static images to complicated activity concepts. In this paper, we propose a novel "Align before Adapt" (ALT) paradigm. Prior to adapting to video representation learning, we exploit the entity-to-region alignments for each frame. The alignments are fulfilled by matching the region-aware image embeddings to an offline-constructed text corpus. With the aligned entities, we feed their text embeddings to a transformer-based video adapter as the queries, which can help extract the semantics of the most important entities from a video to a vector. This paradigm reuses the visual-language alignment of VLP during adaptation and tries to explain an action by the underlying entities. This helps understand actions by bridging the gap with complex activity semantics, particularly when facing unfamiliar or unseen categories. ALT achieves competitive performance and superior generalizability while requiring significantly low computational costs. In fully supervised scenarios, it achieves 88.1% top-1 accuracy on Kinetics-400 with only 4947 GFLOPs. In 2-shot experiments, ALT outperforms the previous state-of-the-art by 7.1% and 9.2% on HMDB-51 and UCF-101, respectively.
PBFormer: Capturing Complex Scene Text Shape with Polynomial Band Transformer
Aug 29, 2023



We present PBFormer, an efficient yet powerful scene text detector that unifies the transformer with a novel text shape representation Polynomial Band (PB). The representation has four polynomial curves to fit a text's top, bottom, left, and right sides, which can capture a text with a complex shape by varying polynomial coefficients. PB has appealing features compared with conventional representations: 1) It can model different curvatures with a fixed number of parameters, while polygon-points-based methods need to utilize a different number of points. 2) It can distinguish adjacent or overlapping texts as they have apparent different curve coefficients, while segmentation-based or points-based methods suffer from adhesive spatial positions. PBFormer combines the PB with the transformer, which can directly generate smooth text contours sampled from predicted curves without interpolation. A parameter-free cross-scale pixel attention (CPA) module is employed to highlight the feature map of a suitable scale while suppressing the other feature maps. The simple operation can help detect small-scale texts and is compatible with the one-stage DETR framework, where no postprocessing exists for NMS. Furthermore, PBFormer is trained with a shape-contained loss, which not only enforces the piecewise alignment between the ground truth and the predicted curves but also makes curves' positions and shapes consistent with each other. Without bells and whistles about text pre-training, our method is superior to the previous state-of-the-art text detectors on the arbitrary-shaped text datasets.
ChartDETR: A Multi-shape Detection Network for Visual Chart Recognition
Aug 15, 2023Visual chart recognition systems are gaining increasing attention due to the growing demand for automatically identifying table headers and values from chart images. Current methods rely on keypoint detection to estimate data element shapes in charts but suffer from grouping errors in post-processing. To address this issue, we propose ChartDETR, a transformer-based multi-shape detector that localizes keypoints at the corners of regular shapes to reconstruct multiple data elements in a single chart image. Our method predicts all data element shapes at once by introducing query groups in set prediction, eliminating the need for further postprocessing. This property allows ChartDETR to serve as a unified framework capable of representing various chart types without altering the network architecture, effectively detecting data elements of diverse shapes. We evaluated ChartDETR on three datasets, achieving competitive results across all chart types without any additional enhancements. For example, ChartDETR achieved an F1 score of 0.98 on Adobe Synthetic, significantly outperforming the previous best model with a 0.71 F1 score. Additionally, we obtained a new state-of-the-art result of 0.97 on ExcelChart400k. The code will be made publicly available.
Improving Table Structure Recognition with Visual-Alignment Sequential Coordinate Modeling
Mar 20, 2023


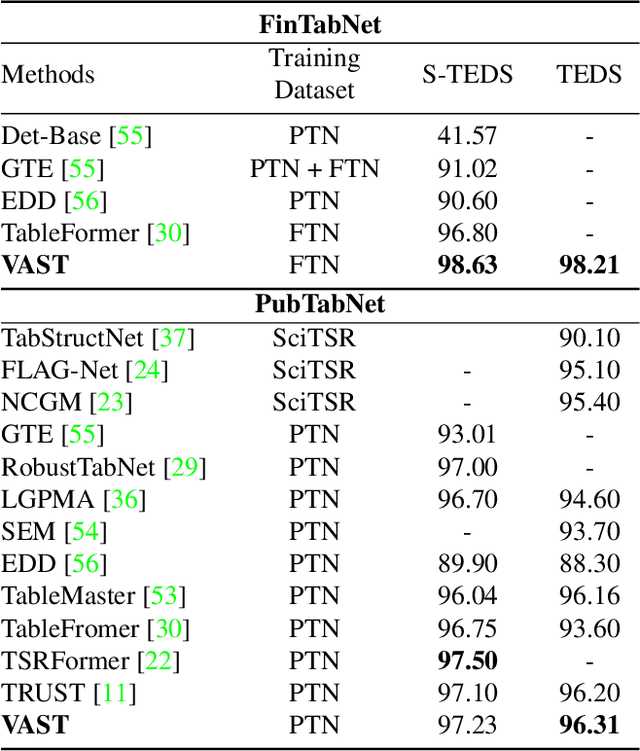
Table structure recognition aims to extract the logical and physical structure of unstructured table images into a machine-readable format. The latest end-to-end image-to-text approaches simultaneously predict the two structures by two decoders, where the prediction of the physical structure (the bounding boxes of the cells) is based on the representation of the logical structure. However, the previous methods struggle with imprecise bounding boxes as the logical representation lacks local visual information. To address this issue, we propose an end-to-end sequential modeling framework for table structure recognition called VAST. It contains a novel coordinate sequence decoder triggered by the representation of the non-empty cell from the logical structure decoder. In the coordinate sequence decoder, we model the bounding box coordinates as a language sequence, where the left, top, right and bottom coordinates are decoded sequentially to leverage the inter-coordinate dependency. Furthermore, we propose an auxiliary visual-alignment loss to enforce the logical representation of the non-empty cells to contain more local visual details, which helps produce better cell bounding boxes. Extensive experiments demonstrate that our proposed method can achieve state-of-the-art results in both logical and physical structure recognition. The ablation study also validates that the proposed coordinate sequence decoder and the visual-alignment loss are the keys to the success of our method.
Video Action Recognition with Attentive Semantic Units
Mar 17, 2023



Visual-Language Models (VLMs) have significantly advanced action video recognition. Supervised by the semantics of action labels, recent works adapt the visual branch of VLMs to learn video representations. Despite the effectiveness proved by these works, we believe that the potential of VLMs has yet to be fully harnessed. In light of this, we exploit the semantic units (SU) hiding behind the action labels and leverage their correlations with fine-grained items in frames for more accurate action recognition. SUs are entities extracted from the language descriptions of the entire action set, including body parts, objects, scenes, and motions. To further enhance the alignments between visual contents and the SUs, we introduce a multi-region module (MRA) to the visual branch of the VLM. The MRA allows the perception of region-aware visual features beyond the original global feature. Our method adaptively attends to and selects relevant SUs with visual features of frames. With a cross-modal decoder, the selected SUs serve to decode spatiotemporal video representations. In summary, the SUs as the medium can boost discriminative ability and transferability. Specifically, in fully-supervised learning, our method achieved 87.8\% top-1 accuracy on Kinetics-400. In K=2 few-shot experiments, our method surpassed the previous state-of-the-art by +7.1% and +15.0% on HMDB-51 and UCF-101, respectively.
FNeVR: Neural Volume Rendering for Face Animation
Sep 21, 2022
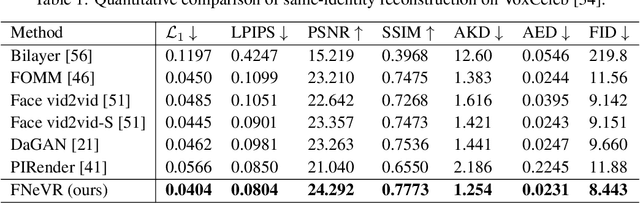
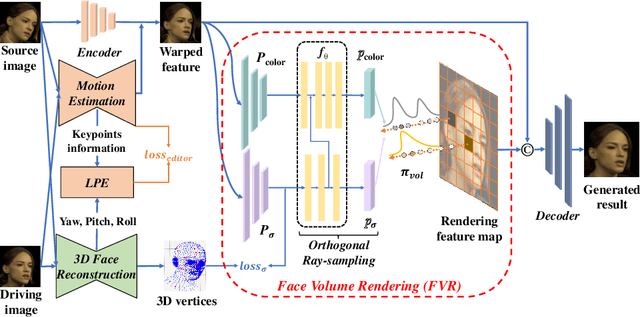
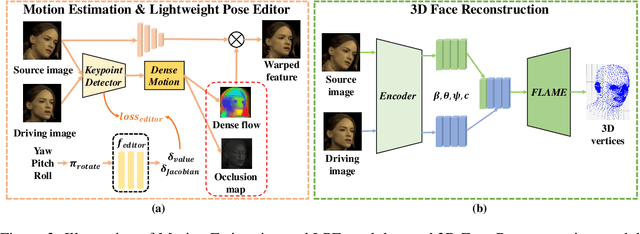
Face animation, one of the hottest topics in computer vision, has achieved a promising performance with the help of generative models. However, it remains a critical challenge to generate identity preserving and photo-realistic images due to the sophisticated motion deformation and complex facial detail modeling. To address these problems, we propose a Face Neural Volume Rendering (FNeVR) network to fully explore the potential of 2D motion warping and 3D volume rendering in a unified framework. In FNeVR, we design a 3D Face Volume Rendering (FVR) module to enhance the facial details for image rendering. Specifically, we first extract 3D information with a well-designed architecture, and then introduce an orthogonal adaptive ray-sampling module for efficient rendering. We also design a lightweight pose editor, enabling FNeVR to edit the facial pose in a simple yet effective way. Extensive experiments show that our FNeVR obtains the best overall quality and performance on widely used talking-head benchmarks.
Learning to Predict 3D Lane Shape and Camera Pose from a Single Image via Geometry Constraints
Dec 31, 2021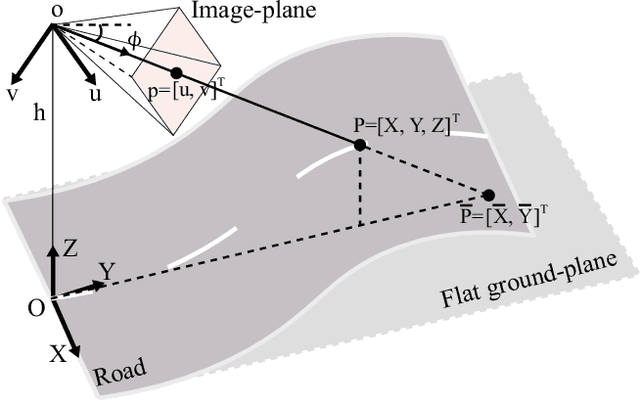
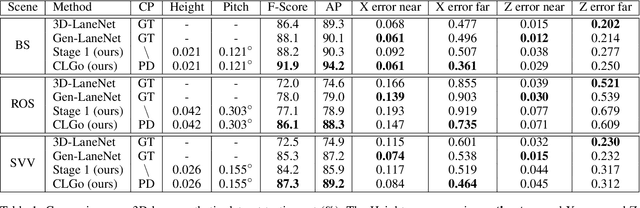
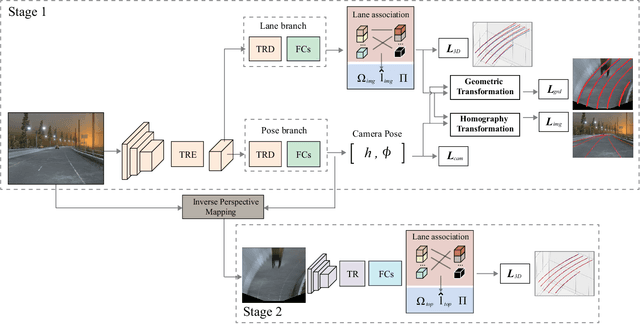
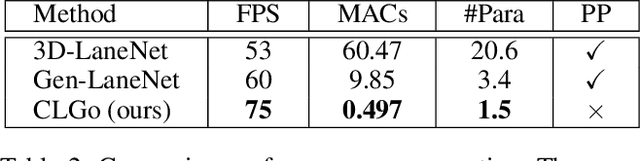
Detecting 3D lanes from the camera is a rising problem for autonomous vehicles. In this task, the correct camera pose is the key to generating accurate lanes, which can transform an image from perspective-view to the top-view. With this transformation, we can get rid of the perspective effects so that 3D lanes would look similar and can accurately be fitted by low-order polynomials. However, mainstream 3D lane detectors rely on perfect camera poses provided by other sensors, which is expensive and encounters multi-sensor calibration issues. To overcome this problem, we propose to predict 3D lanes by estimating camera pose from a single image with a two-stage framework. The first stage aims at the camera pose task from perspective-view images. To improve pose estimation, we introduce an auxiliary 3D lane task and geometry constraints to benefit from multi-task learning, which enhances consistencies between 3D and 2D, as well as compatibility in the above two tasks. The second stage targets the 3D lane task. It uses previously estimated pose to generate top-view images containing distance-invariant lane appearances for predicting accurate 3D lanes. Experiments demonstrate that, without ground truth camera pose, our method outperforms the state-of-the-art perfect-camera-pose-based methods and has the fewest parameters and computations. Codes are available at https://github.com/liuruijin17/CLGo.
Multiple Domain Experts Collaborative Learning: Multi-Source Domain Generalization For Person Re-Identification
May 26, 2021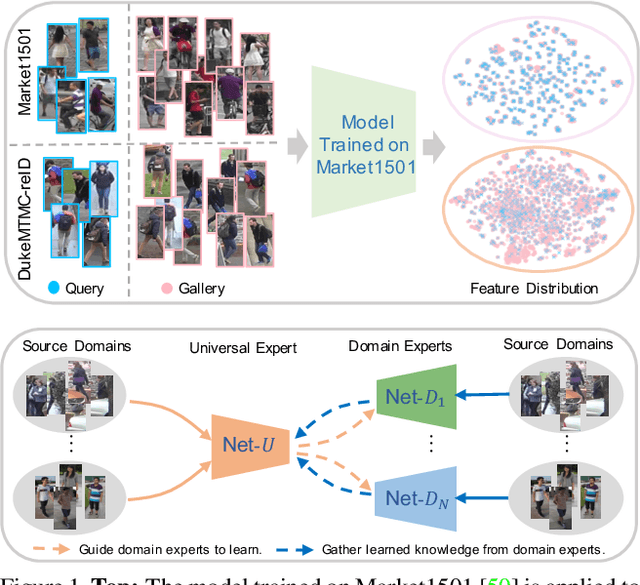
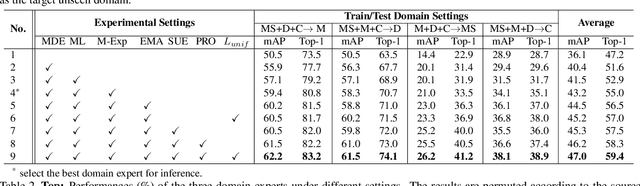
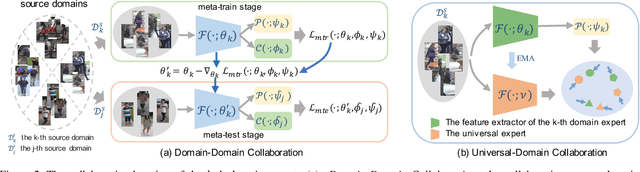
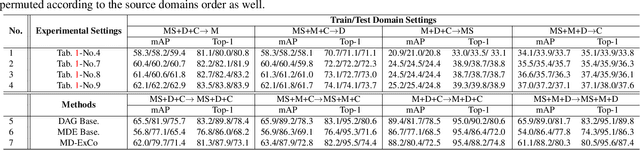
Recent years have witnessed significant progress in person re-identification (ReID). However, current ReID approaches suffer from considerable performance degradation when the test target domains exhibit different characteristics from the training ones, known as the domain shift problem. To make ReID more practical and generalizable, we formulate person re-identification as a Domain Generalization (DG) problem and propose a novel training framework, named Multiple Domain Experts Collaborative Learning (MD-ExCo). Specifically, the MD-ExCo consists of a universal expert and several domain experts. Each domain expert focuses on learning from a specific domain, and periodically communicates with other domain experts to regulate its learning strategy in the meta-learning manner to avoid overfitting. Besides, the universal expert gathers knowledge from the domain experts, and also provides supervision to them as feedback. Extensive experiments on DG-ReID benchmarks show that our MD-ExCo outperforms the state-of-the-art methods by a large margin, showing its ability to improve the generalization capability of the ReID models.