 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPMambaIR:All-in-One Image Restoration via Degradation-Aware Prompt State Space Model
Apr 24, 2025All-in-One image restoration aims to address multiple image degradation problems using a single model, significantly reducing training costs and deployment complexity compared to traditional methods that design dedicated models for each degradation type. Existing approaches typically rely on Degradation-specific models or coarse-grained degradation prompts to guide image restoration. However, they lack fine-grained modeling of degradation information and face limitations in balancing multi-task conflicts. To overcome these limitations, we propose DPMambaIR, a novel All-in-One image restoration framework. By integrating a Degradation-Aware Prompt State Space Model (DP-SSM) and a High-Frequency Enhancement Block (HEB), DPMambaIR enables fine-grained modeling of complex degradation information and efficient global integration, while mitigating the loss of high-frequency details caused by task competition. Specifically, the DP-SSM utilizes a pre-trained degradation extractor to capture fine-grained degradation features and dynamically incorporates them into the state space modeling process, enhancing the model's adaptability to diverse degradation types. Concurrently, the HEB supplements high-frequency information, effectively addressing the loss of critical details, such as edges and textures, in multi-task image restoration scenarios. Extensive experiments on a mixed dataset containing seven degradation types show that DPMambaIR achieves the best performance, with 27.69dB and 0.893 in PSNR and SSIM, respectively. These results highlight the potential and superiority of DPMambaIR as a unified solution for All-in-One image restoration.
NTIRE 2025 Challenge on Event-Based Image Deblurring: Methods and Results
Apr 16, 2025This paper presents an overview of NTIRE 2025 the First Challenge on Event-Based Image Deblurring, detailing the proposed methodologies and corresponding results. The primary goal of the challenge is to design an event-based method that achieves high-quality image deblurring, with performance quantitatively assessed using Peak Signal-to-Noise Ratio (PSNR). Notably, there are no restrictions on computational complexity or model size. The task focuses on leveraging both events and images as inputs for single-image deblurring. A total of 199 participants registered, among whom 15 teams successfully submitted valid results, offering valuable insights into the current state of event-based image deblurring. We anticipate that this challenge will drive further advancements in event-based vision research.
Align before Adapt: Leveraging Entity-to-Region Alignments for Generalizable Video Action Recognition
Nov 27, 2023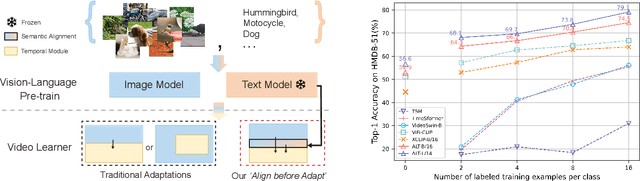
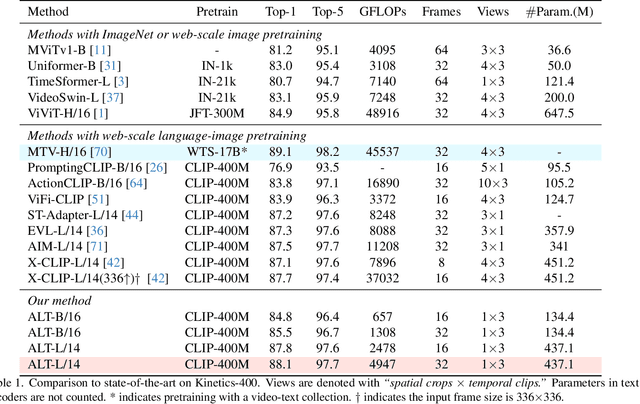
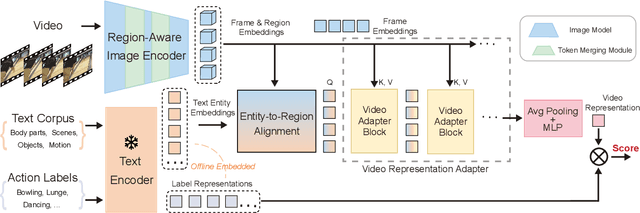
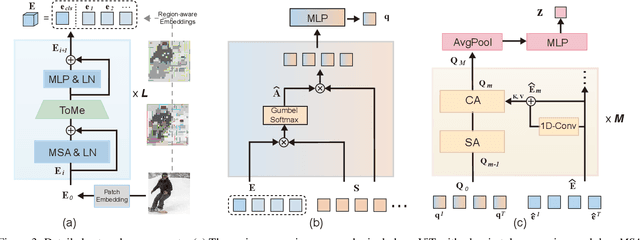
Large-scale visual-language pre-trained models have achieved significant success in various video tasks. However, most existing methods follow an "adapt then align" paradigm, which adapts pre-trained image encoders to model video-level representations and utilizes one-hot or text embedding of the action labels for supervision. This paradigm overlooks the challenge of mapping from static images to complicated activity concepts. In this paper, we propose a novel "Align before Adapt" (ALT) paradigm. Prior to adapting to video representation learning, we exploit the entity-to-region alignments for each frame. The alignments are fulfilled by matching the region-aware image embeddings to an offline-constructed text corpus. With the aligned entities, we feed their text embeddings to a transformer-based video adapter as the queries, which can help extract the semantics of the most important entities from a video to a vector. This paradigm reuses the visual-language alignment of VLP during adaptation and tries to explain an action by the underlying entities. This helps understand actions by bridging the gap with complex activity semantics, particularly when facing unfamiliar or unseen categories. ALT achieves competitive performance and superior generalizability while requiring significantly low computational costs. In fully supervised scenarios, it achieves 88.1% top-1 accuracy on Kinetics-400 with only 4947 GFLOPs. In 2-shot experiments, ALT outperforms the previous state-of-the-art by 7.1% and 9.2% on HMDB-51 and UCF-101, respectively.
ChartDETR: A Multi-shape Detection Network for Visual Chart Recognition
Aug 15, 2023Visual chart recognition systems are gaining increasing attention due to the growing demand for automatically identifying table headers and values from chart images. Current methods rely on keypoint detection to estimate data element shapes in charts but suffer from grouping errors in post-processing. To address this issue, we propose ChartDETR, a transformer-based multi-shape detector that localizes keypoints at the corners of regular shapes to reconstruct multiple data elements in a single chart image. Our method predicts all data element shapes at once by introducing query groups in set prediction, eliminating the need for further postprocessing. This property allows ChartDETR to serve as a unified framework capable of representing various chart types without altering the network architecture, effectively detecting data elements of diverse shapes. We evaluated ChartDETR on three datasets, achieving competitive results across all chart types without any additional enhancements. For example, ChartDETR achieved an F1 score of 0.98 on Adobe Synthetic, significantly outperforming the previous best model with a 0.71 F1 score. Additionally, we obtained a new state-of-the-art result of 0.97 on ExcelChart400k. The code will be made publicly available.