 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDarkDriving: A Real-World Day and Night Aligned Dataset for Autonomous Driving in the Dark Environment
Mar 18, 2026The low-light conditions are challenging to the vision-centric perception systems for autonomous driving in the dark environment. In this paper, we propose a new benchmark dataset (named DarkDriving) to investigate the low-light enhancement for autonomous driving. The existing real-world low-light enhancement benchmark datasets can be collected by controlling various exposures only in small-ranges and static scenes. The dark images of the current nighttime driving datasets do not have the precisely aligned daytime counterparts. The extreme difficulty to collect a real-world day and night aligned dataset in the dynamic driving scenes significantly limited the research in this area. With a proposed automatic day-night Trajectory Tracking based Pose Matching (TTPM) method in a large real-world closed driving test field (area: 69 acres), we collected the first real-world day and night aligned dataset for autonomous driving in the dark environment. The DarkDriving dataset has 9,538 day and night image pairs precisely aligned in location and spatial contents, whose alignment error is in just several centimeters. For each pair, we also manually label the object 2D bounding boxes. DarkDriving introduces four perception related tasks, including low-light enhancement, generalized low-light enhancement, and low-light enhancement for 2D detection and 3D detection of autonomous driving in the dark environment. The experimental results show that our DarkDriving dataset provides a comprehensive benchmark for evaluating low-light enhancement for autonomous driving and it can also be generalized to enhance dark images and promote detection in some other low-light driving environment, such as nuScenes.
PSTTS: A Plug-and-Play Token Selector for Efficient Event-based Spatio-temporal Representation Learning
Sep 26, 2025Mainstream event-based spatio-temporal representation learning methods typically process event streams by converting them into sequences of event frames, achieving remarkable performance. However, they neglect the high spatial sparsity and inter-frame motion redundancy inherent in event frame sequences, leading to significant computational overhead. Existing token sparsification methods for RGB videos rely on unreliable intermediate token representations and neglect the influence of event noise, making them ineffective for direct application to event data. In this paper, we propose Progressive Spatio-Temporal Token Selection (PSTTS), a Plug-and-Play module for event data without introducing any additional parameters. PSTTS exploits the spatio-temporal distribution characteristics embedded in raw event data to effectively identify and discard spatio-temporal redundant tokens, achieving an optimal trade-off between accuracy and efficiency. Specifically, PSTTS consists of two stages, Spatial Token Purification and Temporal Token Selection. Spatial Token Purification discards noise and non-event regions by assessing the spatio-temporal consistency of events within each event frame to prevent interference with subsequent temporal redundancy evaluation. Temporal Token Selection evaluates the motion pattern similarity between adjacent event frames, precisely identifying and removing redundant temporal information. We apply PSTTS to four representative backbones UniformerV2, VideoSwin, EVMamba, and ExACT on the HARDVS, DailyDVS-200, and SeACT datasets. Experimental results demonstrate that PSTTS achieves significant efficiency improvements. Specifically, PSTTS reduces FLOPs by 29-43.6% and increases FPS by 21.6-41.3% on the DailyDVS-200 dataset, while maintaining task accuracy. Our code will be available.
Focus Through Motion: RGB-Event Collaborative Token Sparsification for Efficient Object Detection
Sep 04, 2025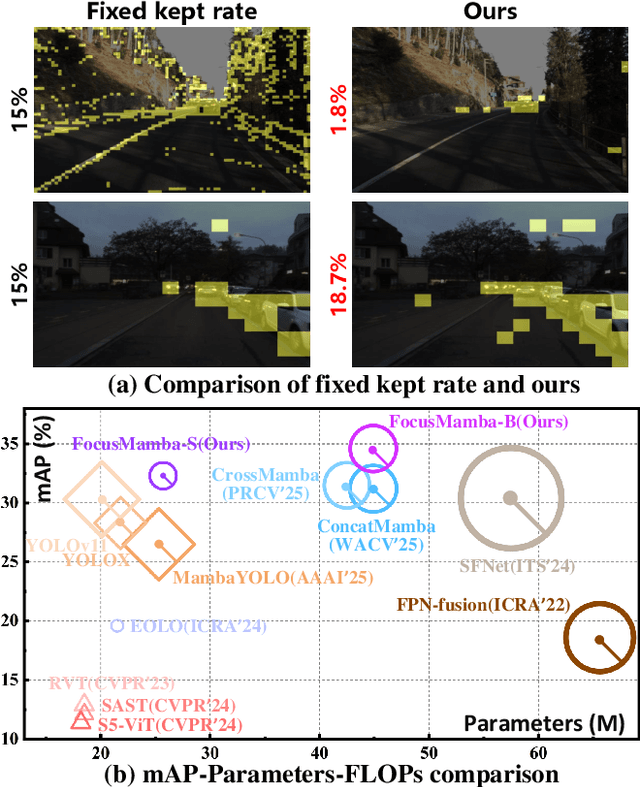
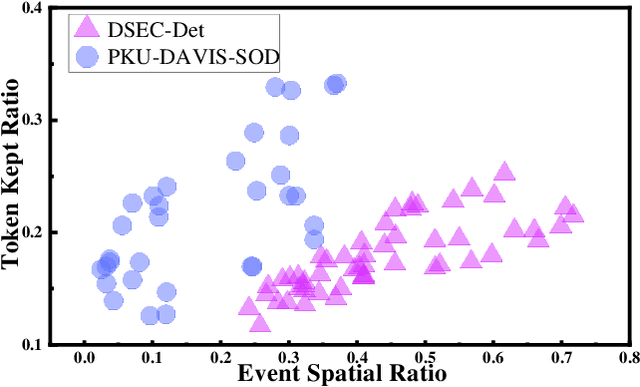
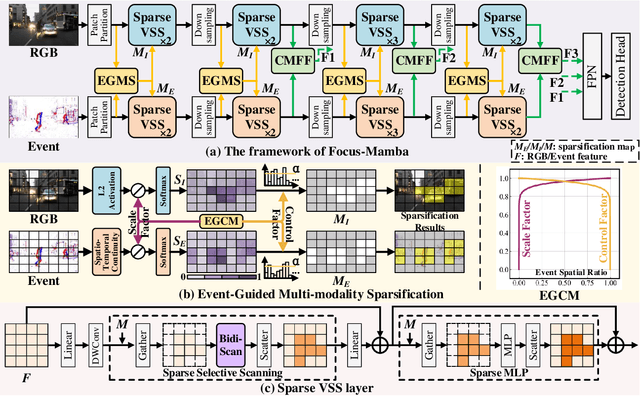
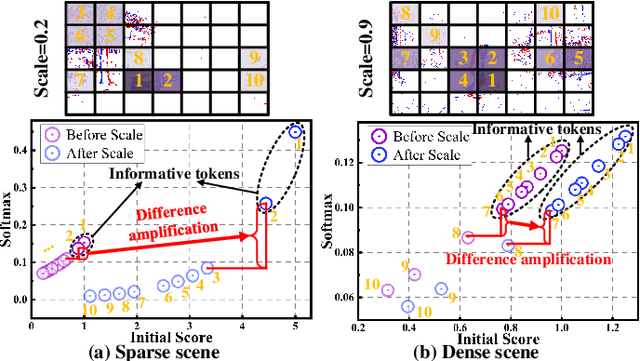
Existing RGB-Event detection methods process the low-information regions of both modalities (background in images and non-event regions in event data) uniformly during feature extraction and fusion, resulting in high computational costs and suboptimal performance. To mitigate the computational redundancy during feature extraction, researchers have respectively proposed token sparsification methods for the image and event modalities. However, these methods employ a fixed number or threshold for token selection, hindering the retention of informative tokens for samples with varying complexity. To achieve a better balance between accuracy and efficiency, we propose FocusMamba, which performs adaptive collaborative sparsification of multimodal features and efficiently integrates complementary information. Specifically, an Event-Guided Multimodal Sparsification (EGMS) strategy is designed to identify and adaptively discard low-information regions within each modality by leveraging scene content changes perceived by the event camera. Based on the sparsification results, a Cross-Modality Focus Fusion (CMFF) module is proposed to effectively capture and integrate complementary features from both modalities. Experiments on the DSEC-Det and PKU-DAVIS-SOD datasets demonstrate that the proposed method achieves superior performance in both accuracy and efficiency compared to existing methods. The code will be available at https://github.com/Zizzzzzzz/FocusMamba.
Bidirectional Image-Event Guided Low-Light Image Enhancement
Jun 06, 2025Under extreme low-light conditions, traditional frame-based cameras, due to their limited dynamic range and temporal resolution, face detail loss and motion blur in captured images. To overcome this bottleneck, researchers have introduced event cameras and proposed event-guided low-light image enhancement algorithms. However, these methods neglect the influence of global low-frequency noise caused by dynamic lighting conditions and local structural discontinuities in sparse event data. To address these issues, we propose an innovative Bidirectional guided Low-light Image Enhancement framework (BiLIE). Specifically, to mitigate the significant low-frequency noise introduced by global illumination step changes, we introduce the frequency high-pass filtering-based Event Feature Enhancement (EFE) module at the event representation level to suppress the interference of low-frequency information, and preserve and highlight the high-frequency edges.Furthermore, we design a Bidirectional Cross Attention Fusion (BCAF) mechanism to acquire high-frequency structures and edges while suppressing structural discontinuities and local noise introduced by sparse event guidance, thereby generating smoother fused representations.Additionally, considering the poor visual quality and color bias in existing datasets, we provide a new dataset (RELIE), with high-quality ground truth through a reliable enhancement scheme. Extensive experimental results demonstrate that our proposed BiLIE outperforms state-of-the-art methods by 0.96dB in PSNR and 0.03 in LPIPS.
DriveAgent: Multi-Agent Structured Reasoning with LLM and Multimodal Sensor Fusion for Autonomous Driving
May 04, 2025
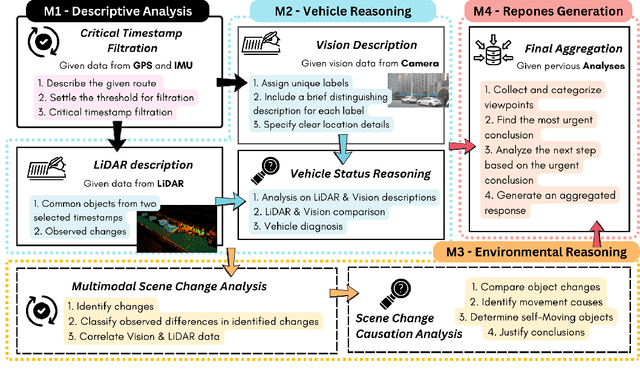
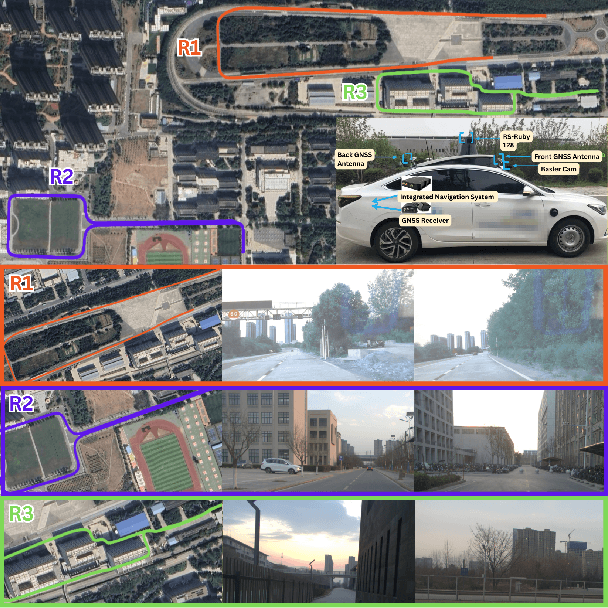
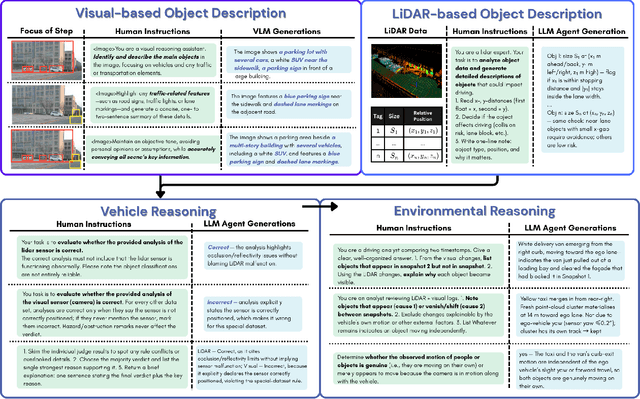
We introduce DriveAgent, a novel multi-agent autonomous driving framework that leverages large language model (LLM) reasoning combined with multimodal sensor fusion to enhance situational understanding and decision-making. DriveAgent uniquely integrates diverse sensor modalities-including camera, LiDAR, GPS, and IMU-with LLM-driven analytical processes structured across specialized agents. The framework operates through a modular agent-based pipeline comprising four principal modules: (i) a descriptive analysis agent identifying critical sensor data events based on filtered timestamps, (ii) dedicated vehicle-level analysis conducted by LiDAR and vision agents that collaboratively assess vehicle conditions and movements, (iii) environmental reasoning and causal analysis agents explaining contextual changes and their underlying mechanisms, and (iv) an urgency-aware decision-generation agent prioritizing insights and proposing timely maneuvers. This modular design empowers the LLM to effectively coordinate specialized perception and reasoning agents, delivering cohesive, interpretable insights into complex autonomous driving scenarios. Extensive experiments on challenging autonomous driving datasets demonstrate that DriveAgent is achieving superior performance on multiple metrics against baseline methods. These results validate the efficacy of the proposed LLM-driven multi-agent sensor fusion framework, underscoring its potential to substantially enhance the robustness and reliability of autonomous driving systems.
DPMambaIR:All-in-One Image Restoration via Degradation-Aware Prompt State Space Model
Apr 24, 2025All-in-One image restoration aims to address multiple image degradation problems using a single model, significantly reducing training costs and deployment complexity compared to traditional methods that design dedicated models for each degradation type. Existing approaches typically rely on Degradation-specific models or coarse-grained degradation prompts to guide image restoration. However, they lack fine-grained modeling of degradation information and face limitations in balancing multi-task conflicts. To overcome these limitations, we propose DPMambaIR, a novel All-in-One image restoration framework. By integrating a Degradation-Aware Prompt State Space Model (DP-SSM) and a High-Frequency Enhancement Block (HEB), DPMambaIR enables fine-grained modeling of complex degradation information and efficient global integration, while mitigating the loss of high-frequency details caused by task competition. Specifically, the DP-SSM utilizes a pre-trained degradation extractor to capture fine-grained degradation features and dynamically incorporates them into the state space modeling process, enhancing the model's adaptability to diverse degradation types. Concurrently, the HEB supplements high-frequency information, effectively addressing the loss of critical details, such as edges and textures, in multi-task image restoration scenarios. Extensive experiments on a mixed dataset containing seven degradation types show that DPMambaIR achieves the best performance, with 27.69dB and 0.893 in PSNR and SSIM, respectively. These results highlight the potential and superiority of DPMambaIR as a unified solution for All-in-One image restoration.
SMamba: Sparse Mamba for Event-based Object Detection
Jan 21, 2025



Transformer-based methods have achieved remarkable performance in event-based object detection, owing to the global modeling ability. However, they neglect the influence of non-event and noisy regions and process them uniformly, leading to high computational overhead. To mitigate computation cost, some researchers propose window attention based sparsification strategies to discard unimportant regions, which sacrifices the global modeling ability and results in suboptimal performance. To achieve better trade-off between accuracy and efficiency, we propose Sparse Mamba (SMamba), which performs adaptive sparsification to reduce computational effort while maintaining global modeling capability. Specifically, a Spatio-Temporal Continuity Assessment module is proposed to measure the information content of tokens and discard uninformative ones by leveraging the spatiotemporal distribution differences between activity and noise events. Based on the assessment results, an Information-Prioritized Local Scan strategy is designed to shorten the scan distance between high-information tokens, facilitating interactions among them in the spatial dimension. Furthermore, to extend the global interaction from 2D space to 3D representations, a Global Channel Interaction module is proposed to aggregate channel information from a global spatial perspective. Results on three datasets (Gen1, 1Mpx, and eTram) demonstrate that our model outperforms other methods in both performance and efficiency.
Multi-scale Temporal Fusion Transformer for Incomplete Vehicle Trajectory Prediction
Sep 02, 2024
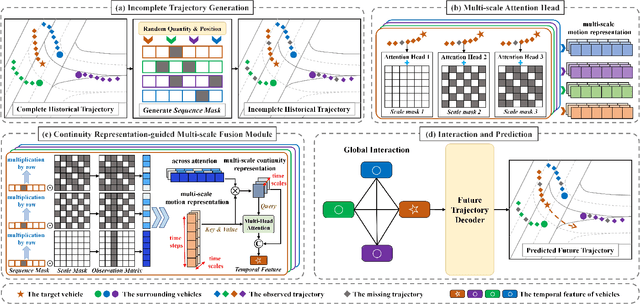

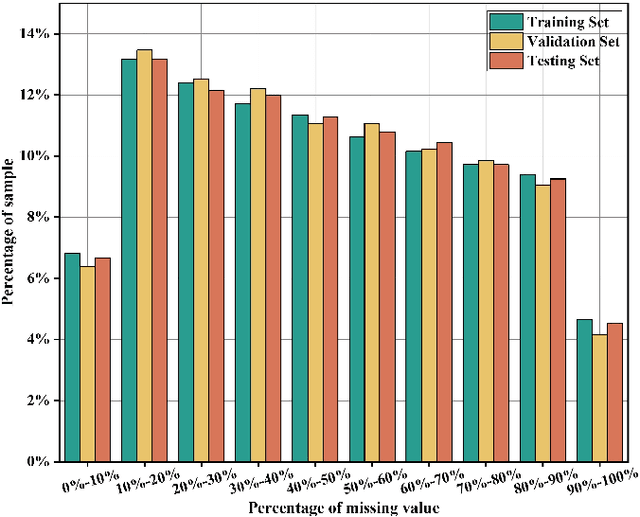
Motion prediction plays an essential role in autonomous driving systems, enabling autonomous vehicles to achieve more accurate local-path planning and driving decisions based on predictions of the surrounding vehicles. However, existing methods neglect the potential missing values caused by object occlusion, perception failures, etc., which inevitably degrades the trajectory prediction performance in real traffic scenarios. To address this limitation, we propose a novel end-to-end framework for incomplete vehicle trajectory prediction, named Multi-scale Temporal Fusion Transformer (MTFT), which consists of the Multi-scale Attention Head (MAH) and the Continuity Representation-guided Multi-scale Fusion (CRMF) module. Specifically, the MAH leverages the multi-head attention mechanism to parallelly capture multi-scale motion representation of trajectory from different temporal granularities, thus mitigating the adverse effect of missing values on prediction. Furthermore, the multi-scale motion representation is input into the CRMF module for multi-scale fusion to obtain the robust temporal feature of the vehicle. During the fusion process, the continuity representation of vehicle motion is first extracted across time steps to guide the fusion, ensuring that the resulting temporal feature incorporates both detailed information and the overall trend of vehicle motion, which facilitates the accurate decoding of future trajectory that is consistent with the vehicle's motion trend. We evaluate the proposed model on four datasets derived from highway and urban traffic scenarios. The experimental results demonstrate its superior performance in the incomplete vehicle trajectory prediction task compared with state-of-the-art models, e.g., a comprehensive performance improvement of more than 39% on the HighD dataset.
MSTF: Multiscale Transformer for Incomplete Trajectory Prediction
Jul 08, 2024Motion forecasting plays a pivotal role in autonomous driving systems, enabling vehicles to execute collision warnings and rational local-path planning based on predictions of the surrounding vehicles. However, prevalent methods often assume complete observed trajectories, neglecting the potential impact of missing values induced by object occlusion, scope limitation, and sensor failures. Such oversights inevitably compromise the accuracy of trajectory predictions. To tackle this challenge, we propose an end-to-end framework, termed Multiscale Transformer (MSTF), meticulously crafted for incomplete trajectory prediction. MSTF integrates a Multiscale Attention Head (MAH) and an Information Increment-based Pattern Adaptive (IIPA) module. Specifically, the MAH component concurrently captures multiscale motion representation of trajectory sequence from various temporal granularities, utilizing a multi-head attention mechanism. This approach facilitates the modeling of global dependencies in motion across different scales, thereby mitigating the adverse effects of missing values. Additionally, the IIPA module adaptively extracts continuity representation of motion across time steps by analyzing missing patterns in the data. The continuity representation delineates motion trend at a higher level, guiding MSTF to generate predictions consistent with motion continuity. We evaluate our proposed MSTF model using two large-scale real-world datasets. Experimental results demonstrate that MSTF surpasses state-of-the-art (SOTA) models in the task of incomplete trajectory prediction, showcasing its efficacy in addressing the challenges posed by missing values in motion forecasting for autonomous driving systems.
Boosting Visual Recognition for Autonomous Driving in Real-world Degradations with Deep Channel Prior
Apr 02, 2024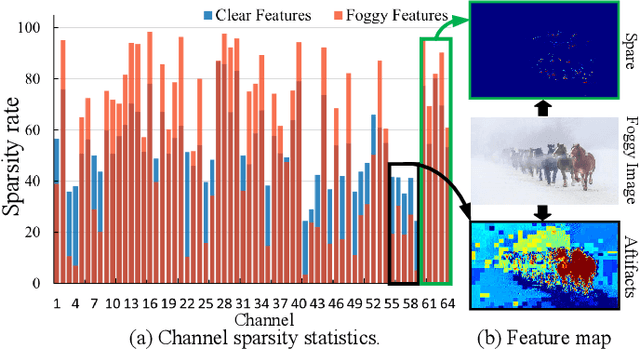
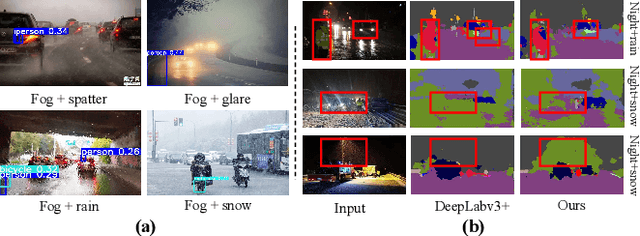
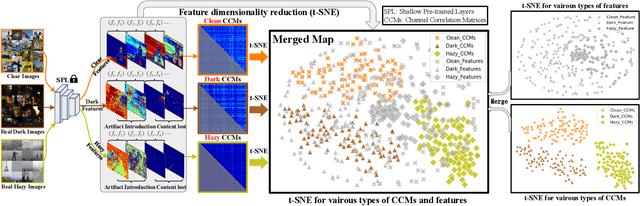
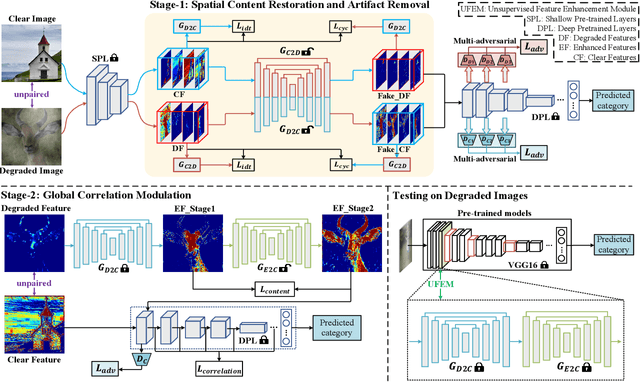
The environmental perception of autonomous vehicles in normal conditions have achieved considerable success in the past decade. However, various unfavourable conditions such as fog, low-light, and motion blur will degrade image quality and pose tremendous threats to the safety of autonomous driving. That is, when applied to degraded images, state-of-the-art visual models often suffer performance decline due to the feature content loss and artifact interference caused by statistical and structural properties disruption of captured images. To address this problem, this work proposes a novel Deep Channel Prior (DCP) for degraded visual recognition. Specifically, we observe that, in the deep representation space of pre-trained models, the channel correlations of degraded features with the same degradation type have uniform distribution even if they have different content and semantics, which can facilitate the mapping relationship learning between degraded and clear representations in high-sparsity feature space. Based on this, a novel plug-and-play Unsupervised Feature Enhancement Module (UFEM) is proposed to achieve unsupervised feature correction, where the multi-adversarial mechanism is introduced in the first stage of UFEM to achieve the latent content restoration and artifact removal in high-sparsity feature space. Then, the generated features are transferred to the second stage for global correlation modulation under the guidance of DCP to obtain high-quality and recognition-friendly features. Evaluations of three tasks and eight benchmark datasets demonstrate that our proposed method can comprehensively improve the performance of pre-trained models in real degradation conditions. The source code is available at https://github.com/liyuhang166/Deep_Channel_Prior