 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Training-free Multimodal Hate Localisation with Large Language Models
Feb 10, 2026The proliferation of hateful content in online videos poses severe threats to individual well-being and societal harmony. However, existing solutions for video hate detection either rely heavily on large-scale human annotations or lack fine-grained temporal precision. In this work, we propose LELA, the first training-free Large Language Model (LLM) based framework for hate video localization. Distinct from state-of-the-art models that depend on supervised pipelines, LELA leverages LLMs and modality-specific captioning to detect and temporally localize hateful content in a training-free manner. Our method decomposes a video into five modalities, including image, speech, OCR, music, and video context, and uses a multi-stage prompting scheme to compute fine-grained hateful scores for each frame. We further introduce a composition matching mechanism to enhance cross-modal reasoning. Experiments on two challenging benchmarks, HateMM and MultiHateClip, demonstrate that LELA outperforms all existing training-free baselines by a large margin. We also provide extensive ablations and qualitative visualizations, establishing LELA as a strong foundation for scalable and interpretable hate video localization.
GeoPredict: Leveraging Predictive Kinematics and 3D Gaussian Geometry for Precise VLA Manipulation
Dec 18, 2025Vision-Language-Action (VLA) models achieve strong generalization in robotic manipulation but remain largely reactive and 2D-centric, making them unreliable in tasks that require precise 3D reasoning. We propose GeoPredict, a geometry-aware VLA framework that augments a continuous-action policy with predictive kinematic and geometric priors. GeoPredict introduces a trajectory-level module that encodes motion history and predicts multi-step 3D keypoint trajectories of robot arms, and a predictive 3D Gaussian geometry module that forecasts workspace geometry with track-guided refinement along future keypoint trajectories. These predictive modules serve exclusively as training-time supervision through depth-based rendering, while inference requires only lightweight additional query tokens without invoking any 3D decoding. Experiments on RoboCasa Human-50, LIBERO, and real-world manipulation tasks show that GeoPredict consistently outperforms strong VLA baselines, especially in geometry-intensive and spatially demanding scenarios.
UniTac2Pose: A Unified Approach Learned in Simulation for Category-level Visuotactile In-hand Pose Estimation
Sep 19, 2025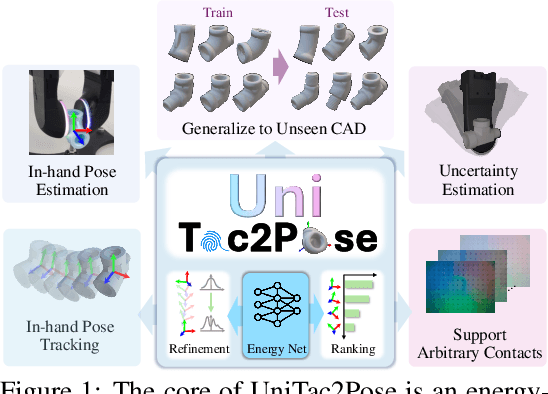
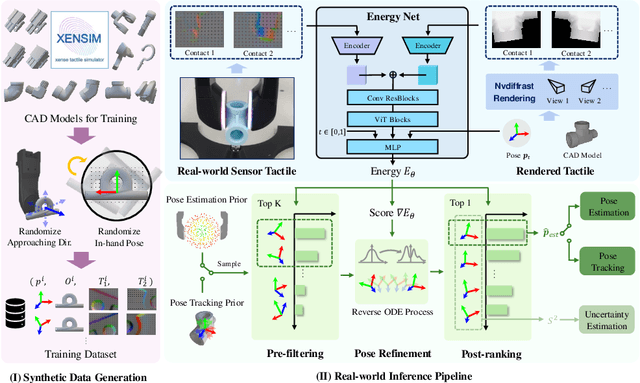

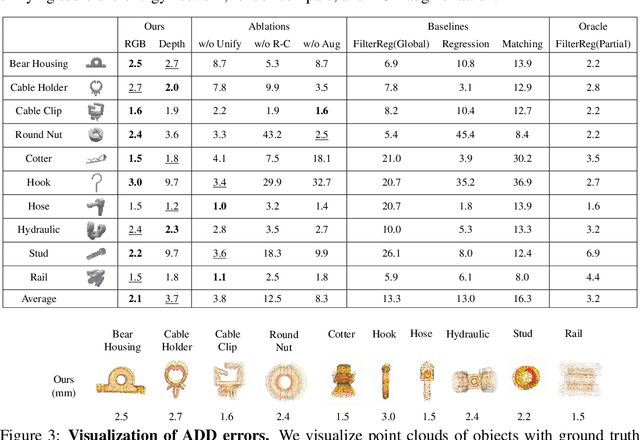
Accurate estimation of the in-hand pose of an object based on its CAD model is crucial in both industrial applications and everyday tasks, ranging from positioning workpieces and assembling components to seamlessly inserting devices like USB connectors. While existing methods often rely on regression, feature matching, or registration techniques, achieving high precision and generalizability to unseen CAD models remains a significant challenge. In this paper, we propose a novel three-stage framework for in-hand pose estimation. The first stage involves sampling and pre-ranking pose candidates, followed by iterative refinement of these candidates in the second stage. In the final stage, post-ranking is applied to identify the most likely pose candidates. These stages are governed by a unified energy-based diffusion model, which is trained solely on simulated data. This energy model simultaneously generates gradients to refine pose estimates and produces an energy scalar that quantifies the quality of the pose estimates. Additionally, borrowing the idea from the computer vision domain, we incorporate a render-compare architecture within the energy-based score network to significantly enhance sim-to-real performance, as demonstrated by our ablation studies. We conduct comprehensive experiments to show that our method outperforms conventional baselines based on regression, matching, and registration techniques, while also exhibiting strong intra-category generalization to previously unseen CAD models. Moreover, our approach integrates tactile object pose estimation, pose tracking, and uncertainty estimation into a unified framework, enabling robust performance across a variety of real-world conditions.
DriveAgent: Multi-Agent Structured Reasoning with LLM and Multimodal Sensor Fusion for Autonomous Driving
May 04, 2025
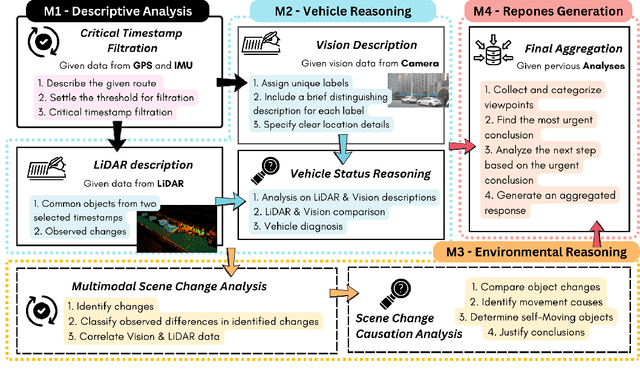
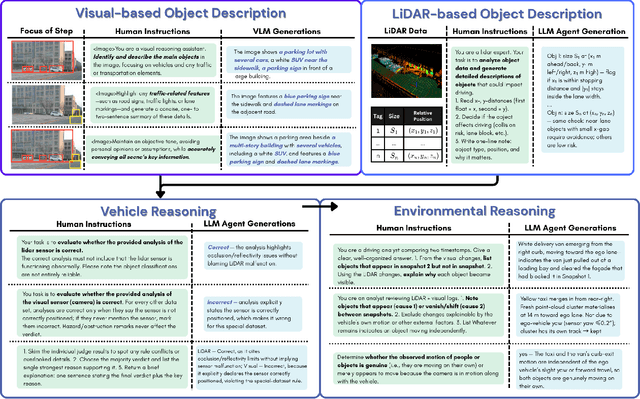
We introduce DriveAgent, a novel multi-agent autonomous driving framework that leverages large language model (LLM) reasoning combined with multimodal sensor fusion to enhance situational understanding and decision-making. DriveAgent uniquely integrates diverse sensor modalities-including camera, LiDAR, GPS, and IMU-with LLM-driven analytical processes structured across specialized agents. The framework operates through a modular agent-based pipeline comprising four principal modules: (i) a descriptive analysis agent identifying critical sensor data events based on filtered timestamps, (ii) dedicated vehicle-level analysis conducted by LiDAR and vision agents that collaboratively assess vehicle conditions and movements, (iii) environmental reasoning and causal analysis agents explaining contextual changes and their underlying mechanisms, and (iv) an urgency-aware decision-generation agent prioritizing insights and proposing timely maneuvers. This modular design empowers the LLM to effectively coordinate specialized perception and reasoning agents, delivering cohesive, interpretable insights into complex autonomous driving scenarios. Extensive experiments on challenging autonomous driving datasets demonstrate that DriveAgent is achieving superior performance on multiple metrics against baseline methods. These results validate the efficacy of the proposed LLM-driven multi-agent sensor fusion framework, underscoring its potential to substantially enhance the robustness and reliability of autonomous driving systems.
Doracamom: Joint 3D Detection and Occupancy Prediction with Multi-view 4D Radars and Cameras for Omnidirectional Perception
Jan 26, 2025



3D object detection and occupancy prediction are critical tasks in autonomous driving, attracting significant attention. Despite the potential of recent vision-based methods, they encounter challenges under adverse conditions. Thus, integrating cameras with next-generation 4D imaging radar to achieve unified multi-task perception is highly significant, though research in this domain remains limited. In this paper, we propose Doracamom, the first framework that fuses multi-view cameras and 4D radar for joint 3D object detection and semantic occupancy prediction, enabling comprehensive environmental perception. Specifically, we introduce a novel Coarse Voxel Queries Generator that integrates geometric priors from 4D radar with semantic features from images to initialize voxel queries, establishing a robust foundation for subsequent Transformer-based refinement. To leverage temporal information, we design a Dual-Branch Temporal Encoder that processes multi-modal temporal features in parallel across BEV and voxel spaces, enabling comprehensive spatio-temporal representation learning. Furthermore, we propose a Cross-Modal BEV-Voxel Fusion module that adaptively fuses complementary features through attention mechanisms while employing auxiliary tasks to enhance feature quality. Extensive experiments on the OmniHD-Scenes, View-of-Delft (VoD), and TJ4DRadSet datasets demonstrate that Doracamom achieves state-of-the-art performance in both tasks, establishing new benchmarks for multi-modal 3D perception. Code and models will be publicly available.
MetaOcc: Surround-View 4D Radar and Camera Fusion Framework for 3D Occupancy Prediction with Dual Training Strategies
Jan 26, 2025



3D occupancy prediction is crucial for autonomous driving perception. Fusion of 4D radar and camera provides a potential solution of robust occupancy prediction on serve weather with least cost. How to achieve effective multi-modal feature fusion and reduce annotation costs remains significant challenges. In this work, we propose MetaOcc, a novel multi-modal occupancy prediction framework that fuses surround-view cameras and 4D radar for comprehensive environmental perception. We first design a height self-attention module for effective 3D feature extraction from sparse radar points. Then, a local-global fusion mechanism is proposed to adaptively capture modality contributions while handling spatio-temporal misalignments. Temporal alignment and fusion module is employed to further aggregate historical feature. Furthermore, we develop a semi-supervised training procedure leveraging open-set segmentor and geometric constraints for pseudo-label generation, enabling robust perception with limited annotations. Extensive experiments on OmniHD-Scenes dataset demonstrate that MetaOcc achieves state-of-the-art performance, surpassing previous methods by significant margins. Notably, as the first semi-supervised 4D radar and camera fusion-based occupancy prediction approach, MetaOcc maintains 92.5% of the fully-supervised performance while using only 50% of ground truth annotations, establishing a new benchmark for multi-modal 3D occupancy prediction. Code and data are available at https://github.com/LucasYang567/MetaOcc.
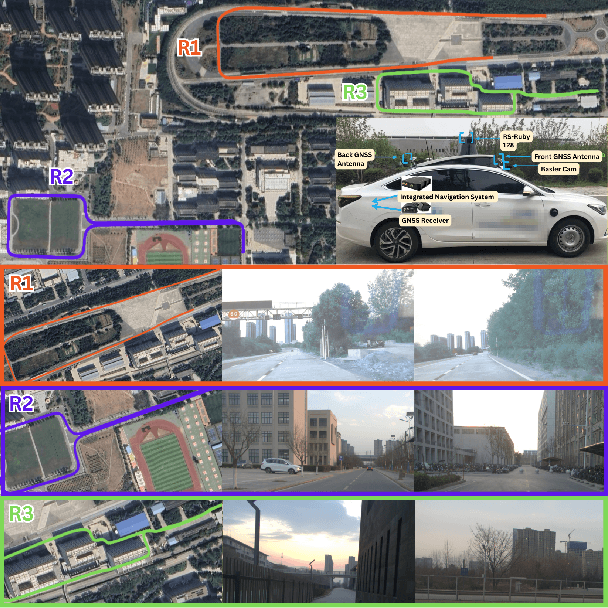
OmniHD-Scenes: A Next-Generation Multimodal Dataset for Autonomous Driving
Dec 14, 2024

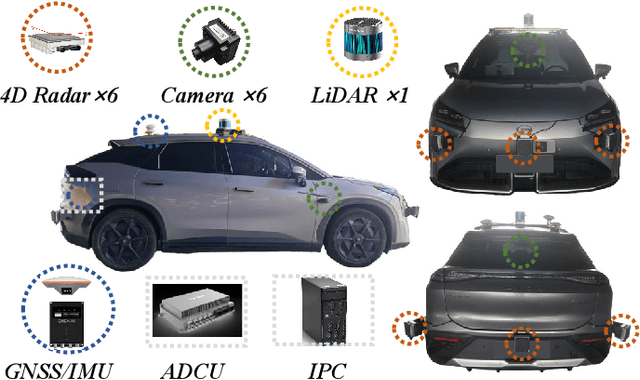

The rapid advancement of deep learning has intensified the need for comprehensive data for use by autonomous driving algorithms. High-quality datasets are crucial for the development of effective data-driven autonomous driving solutions. Next-generation autonomous driving datasets must be multimodal, incorporating data from advanced sensors that feature extensive data coverage, detailed annotations, and diverse scene representation. To address this need, we present OmniHD-Scenes, a large-scale multimodal dataset that provides comprehensive omnidirectional high-definition data. The OmniHD-Scenes dataset combines data from 128-beam LiDAR, six cameras, and six 4D imaging radar systems to achieve full environmental perception. The dataset comprises 1501 clips, each approximately 30-s long, totaling more than 450K synchronized frames and more than 5.85 million synchronized sensor data points. We also propose a novel 4D annotation pipeline. To date, we have annotated 200 clips with more than 514K precise 3D bounding boxes. These clips also include semantic segmentation annotations for static scene elements. Additionally, we introduce a novel automated pipeline for generation of the dense occupancy ground truth, which effectively leverages information from non-key frames. Alongside the proposed dataset, we establish comprehensive evaluation metrics, baseline models, and benchmarks for 3D detection and semantic occupancy prediction. These benchmarks utilize surround-view cameras and 4D imaging radar to explore cost-effective sensor solutions for autonomous driving applications. Extensive experiments demonstrate the effectiveness of our low-cost sensor configuration and its robustness under adverse conditions. Data will be released at https://www.2077ai.com/OmniHD-Scenes.
TARGO: Benchmarking Target-driven Object Grasping under Occlusions
Jul 08, 2024Recent advances in predicting 6D grasp poses from a single depth image have led to promising performance in robotic grasping. However, previous grasping models face challenges in cluttered environments where nearby objects impact the target object's grasp. In this paper, we first establish a new benchmark dataset for TARget-driven Grasping under Occlusions, named TARGO. We make the following contributions: 1) We are the first to study the occlusion level of grasping. 2) We set up an evaluation benchmark consisting of large-scale synthetic data and part of real-world data, and we evaluated five grasp models and found that even the current SOTA model suffers when the occlusion level increases, leaving grasping under occlusion still a challenge. 3) We also generate a large-scale training dataset via a scalable pipeline, which can be used to boost the performance of grasping under occlusion and generalized to the real world. 4) We further propose a transformer-based grasping model involving a shape completion module, termed TARGO-Net, which performs most robustly as occlusion increases. Our benchmark dataset can be found at https://TARGO-benchmark.github.io/.
Off-OAB: Off-Policy Policy Gradient Method with Optimal Action-Dependent Baseline
May 04, 2024



Policy-based methods have achieved remarkable success in solving challenging reinforcement learning problems. Among these methods, off-policy policy gradient methods are particularly important due to that they can benefit from off-policy data. However, these methods suffer from the high variance of the off-policy policy gradient (OPPG) estimator, which results in poor sample efficiency during training. In this paper, we propose an off-policy policy gradient method with the optimal action-dependent baseline (Off-OAB) to mitigate this variance issue. Specifically, this baseline maintains the OPPG estimator's unbiasedness while theoretically minimizing its variance. To enhance practical computational efficiency, we design an approximated version of this optimal baseline. Utilizing this approximation, our method (Off-OAB) aims to decrease the OPPG estimator's variance during policy optimization. We evaluate the proposed Off-OAB method on six representative tasks from OpenAI Gym and MuJoCo, where it demonstrably surpasses state-of-the-art methods on the majority of these tasks.
FlagVNE: A Flexible and Generalizable Reinforcement Learning Framework for Network Resource Allocation
Apr 19, 2024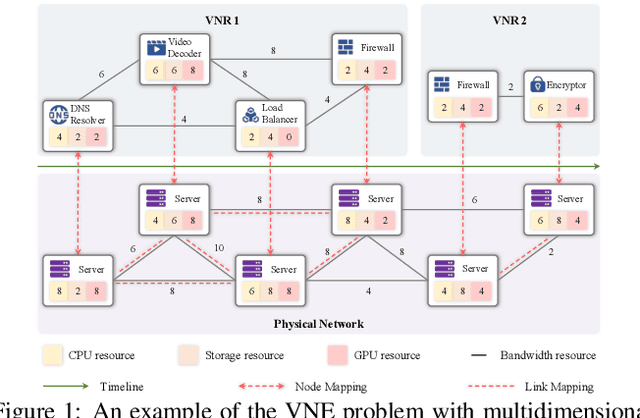
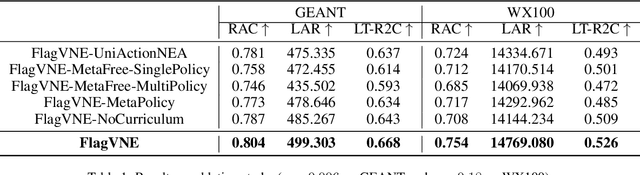
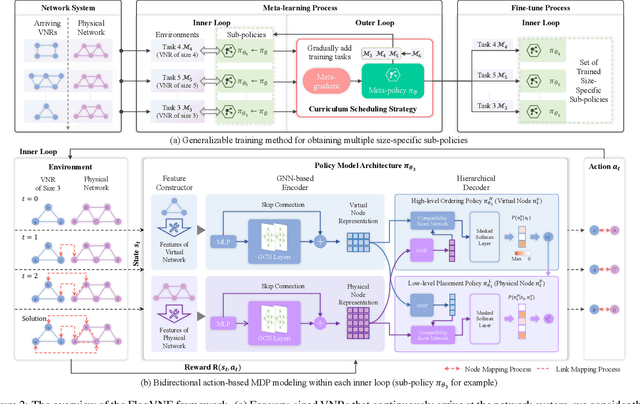
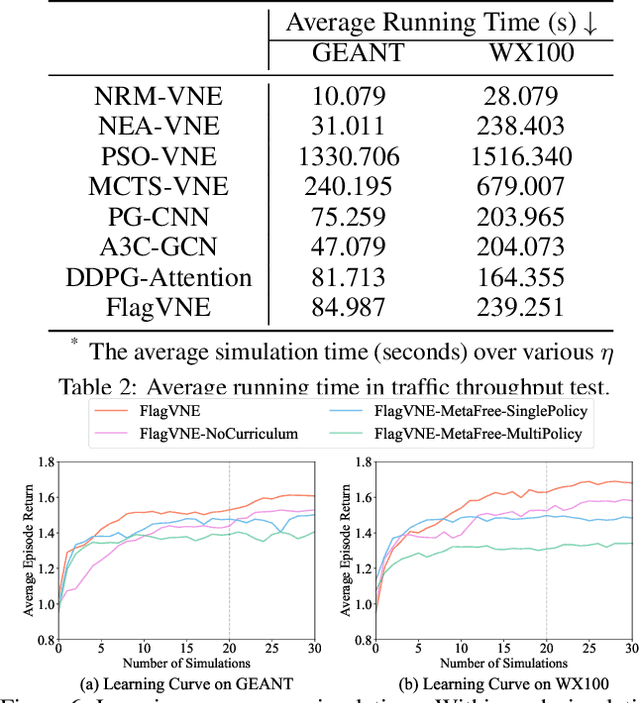
Virtual network embedding (VNE) is an essential resource allocation task in network virtualization, aiming to map virtual network requests (VNRs) onto physical infrastructure. Reinforcement learning (RL) has recently emerged as a promising solution to this problem. However, existing RL-based VNE methods are limited by the unidirectional action design and one-size-fits-all training strategy, resulting in restricted searchability and generalizability. In this paper, we propose a FLexible And Generalizable RL framework for VNE, named FlagVNE. Specifically, we design a bidirectional action-based Markov decision process model that enables the joint selection of virtual and physical nodes, thus improving the exploration flexibility of solution space. To tackle the expansive and dynamic action space, we design a hierarchical decoder to generate adaptive action probability distributions and ensure high training efficiency. Furthermore, to overcome the generalization issue for varying VNR sizes, we propose a meta-RL-based training method with a curriculum scheduling strategy, facilitating specialized policy training for each VNR size. Finally, extensive experimental results show the effectiveness of FlagVNE across multiple key metrics. Our code is available at GitHub (https://github.com/GeminiLight/flag-vne).