 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamPPG: Low-Latency rPPG Estimation via Consistent Privileged Learning
Jun 22, 2026Remote photoplethysmography (rPPG) estimates the blood volume pulse (BVP) signal from facial videos, enabling contact-free health monitoring. Conventional clip-wise approaches, which use video clips as input, require capturing over one hundred frames before inference, thus introducing several seconds of delay and hindering real-time use. Meanwhile, frame-wise approaches struggle to capture long-range temporal and periodic features of physiological rhythms, and therefore lead to reduced estimation accuracy. To overcome these issues, we propose StreamPPG, a unified architecture that enables low-latency frame-wise physiological signal estimation while achieving competitive accuracy compared with clip-wise approaches. StreamPPG is trained under a consistent privileged learning (CPL) strategy, which leverages ground-truth rPPG signals as privileged information to enhance the model's representation capability. Extensive experiments demonstrate that StreamPPG achieves state-of-the-art accuracy across multiple datasets while maintaining real-time throughput on edge devices.
Towards Consistent Video Geometry Estimation
May 28, 2026This work presents ViGeo, a feed-forward foundation model for recovering spatially dense and temporally consistent geometry from video sequences. Built upon a plain transformer architecture without task-specific architectural modifications, ViGeo supports streaming, full-sequence, and long-video inference within a unified model. The key design is dynamic chunking attention, which exposes the model to both bidirectional and causal temporal contexts during training and allows it to adapt its attention pattern at test time without retraining. To improve supervision quality, we further introduce a completion-based data refinement framework. This framework trains a video depth completion teacher that conditions on sparse and noisy annotations and exploits video/multi-view context to produce dense, temporally coherent, and geometrically reliable training targets. Beyond depth and point maps, ViGeo also predicts surface normals within the same framework. Trained solely on public datasets, ViGeo achieves state-of-the-art performance across online, offline, and long-video depth estimation, surface normal estimation, and video point map estimation.
Large Depth Completion Model from Sparse Observations
May 28, 2026This work presents the Large Depth Completion Model (LDCM), a simple, effective, and robust framework for single-view metric depth estimation with sparse observations. Without relying on complex architectural designs, LDCM generates metric-accurate dense depth maps using a transformer. It outperforms existing approaches across diverse datasets and sparse observations. We achieve this from two key perspectives: (1) leveraging existing monocular foundation models to improve the quality of sparse depth inputs, and (2) reformulating training objectives to better capture geometric structure and metric consistency. Specifically, a Poisson-based depth initialization strategy is first introduced to generate a uniform coarse dense depth map from diverse sparse observations, providing a strong structural prior for the network. Regarding the training objective, we replace the conventional depth head with a point map head that regresses per-pixel 3D coordinates in camera space, enabling the model to directly learn the underlying 3D scene structure instead of performing pixel-wise depth map restoration. Moreover, this design eliminates the need for camera intrinsic parameters, allowing LDCM to naturally produce metric-scaled 3D point maps. Extensive experiments demonstrate that LDCM consistently outperforms state-of-the-art methods across multiple benchmarks and varying sparsity levels in both depth completion and point map estimation, showcasing its effectiveness and strong generalization to unseen data distributions.
SD4R: Sparse-to-Dense Learning for 3D Object Detection with 4D Radar
Feb 24, 20264D radar measurements offer an affordable and weather-robust solution for 3D perception. However, the inherent sparsity and noise of radar point clouds present significant challenges for accurate 3D object detection, underscoring the need for effective and robust point clouds densification. Despite recent progress, existing densification methods often fail to address the extreme sparsity of 4D radar point clouds and exhibit limited robustness when processing scenes with a small number of points. In this paper, we propose SD4R, a novel framework that transforms sparse radar point clouds into dense representations. SD4R begins by utilizing a foreground point generator (FPG) to mitigate noise propagation and produce densified point clouds. Subsequently, a logit-query encoder (LQE) enhances conventional pillarization, resulting in robust feature representations. Through these innovations, our SD4R demonstrates strong capability in both noise reduction and foreground point densification. Extensive experiments conducted on the publicly available View-of-Delft dataset demonstrate that SD4R achieves state-of-the-art performance. Source code is available at https://github.com/lancelot0805/SD4R.
Boosting Instance Awareness via Cross-View Correlation with 4D Radar and Camera for 3D Object Detection
Feb 24, 20264D millimeter-wave radar has emerged as a promising sensing modality for autonomous driving due to its robustness and affordability. However, its sparse and weak geometric cues make reliable instance activation difficult, limiting the effectiveness of existing radar-camera fusion paradigms. BEV-level fusion offers global scene understanding but suffers from weak instance focus, while perspective-level fusion captures instance details but lacks holistic context. To address these limitations, we propose SIFormer, a scene-instance aware transformer for 3D object detection using 4D radar and camera. SIFormer first suppresses background noise during view transformation through segmentation- and depth-guided localization. It then introduces a cross-view activation mechanism that injects 2D instance cues into BEV space, enabling reliable instance awareness under weak radar geometry. Finally, a transformer-based fusion module aggregates complementary image semantics and radar geometry for robust perception. As a result, with the aim of enhancing instance awareness, SIFormer bridges the gap between the two paradigms, combining their complementary strengths to address inherent sparse nature of radar and improve detection accuracy. Experiments demonstrate that SIFormer achieves state-of-the-art performance on View-of-Delft, TJ4DRadSet and NuScenes datasets. Source code is available at github.com/shawnnnkb/SIFormer.
S-BEVLoc: BEV-based Self-supervised Framework for Large-scale LiDAR Global Localization
Sep 11, 2025LiDAR-based global localization is an essential component of simultaneous localization and mapping (SLAM), which helps loop closure and re-localization. Current approaches rely on ground-truth poses obtained from GPS or SLAM odometry to supervise network training. Despite the great success of these supervised approaches, substantial cost and effort are required for high-precision ground-truth pose acquisition. In this work, we propose S-BEVLoc, a novel self-supervised framework based on bird's-eye view (BEV) for LiDAR global localization, which eliminates the need for ground-truth poses and is highly scalable. We construct training triplets from single BEV images by leveraging the known geographic distances between keypoint-centered BEV patches. Convolutional neural network (CNN) is used to extract local features, and NetVLAD is employed to aggregate global descriptors. Moreover, we introduce SoftCos loss to enhance learning from the generated triplets. Experimental results on the large-scale KITTI and NCLT datasets show that S-BEVLoc achieves state-of-the-art performance in place recognition, loop closure, and global localization tasks, while offering scalability that would require extra effort for supervised approaches.
EDFFDNet: Towards Accurate and Efficient Unsupervised Multi-Grid Image Registration
Sep 09, 2025Previous deep image registration methods that employ single homography, multi-grid homography, or thin-plate spline often struggle with real scenes containing depth disparities due to their inherent limitations. To address this, we propose an Exponential-Decay Free-Form Deformation Network (EDFFDNet), which employs free-form deformation with an exponential-decay basis function. This design achieves higher efficiency and performs well in scenes with depth disparities, benefiting from its inherent locality. We also introduce an Adaptive Sparse Motion Aggregator (ASMA), which replaces the MLP motion aggregator used in previous methods. By transforming dense interactions into sparse ones, ASMA reduces parameters and improves accuracy. Additionally, we propose a progressive correlation refinement strategy that leverages global-local correlation patterns for coarse-to-fine motion estimation, further enhancing efficiency and accuracy. Experiments demonstrate that EDFFDNet reduces parameters, memory, and total runtime by 70.5%, 32.6%, and 33.7%, respectively, while achieving a 0.5 dB PSNR gain over the state-of-the-art method. With an additional local refinement stage,EDFFDNet-2 further improves PSNR by 1.06 dB while maintaining lower computational costs. Our method also demonstrates strong generalization ability across datasets, outperforming previous deep learning methods.
Structure-Aware Radar-Camera Depth Estimation
Jun 05, 2025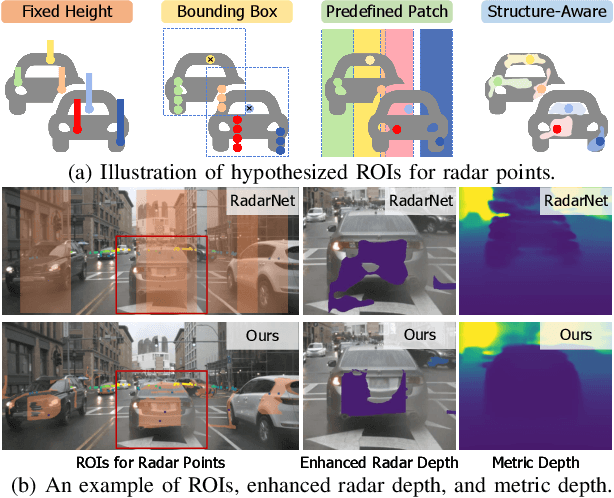
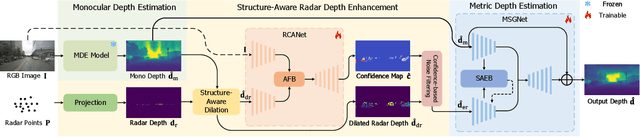
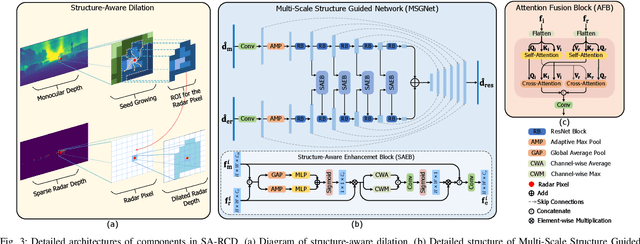
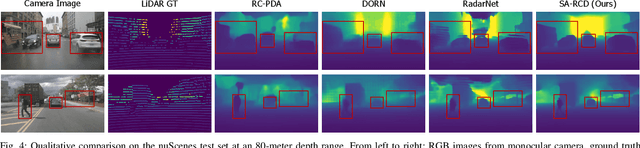
Monocular depth estimation aims to determine the depth of each pixel from an RGB image captured by a monocular camera. The development of deep learning has significantly advanced this field by facilitating the learning of depth features from some well-annotated datasets \cite{Geiger_Lenz_Stiller_Urtasun_2013,silberman2012indoor}. Eigen \textit{et al.} \cite{eigen2014depth} first introduce a multi-scale fusion network for depth regression. Following this, subsequent improvements have come from reinterpreting the regression task as a classification problem \cite{bhat2021adabins,Li_Wang_Liu_Jiang_2022}, incorporating additional priors \cite{shao2023nddepth,yang2023gedepth}, and developing more effective objective function \cite{xian2020structure,Yin_Liu_Shen_Yan_2019}. Despite these advances, generalizing to unseen domains remains a challenge. Recently, several methods have employed affine-invariant loss to enable multi-dataset joint training \cite{MiDaS,ZeroDepth,guizilini2023towards,Dany}. Among them, Depth Anything \cite{Dany} has shown leading performance in zero-shot monocular depth estimation. While it struggles to estimate accurate metric depth due to the lack of explicit depth cues, it excels at extracting structural information from unseen images, producing structure-detailed monocular depth.
CDFormer: Cross-Domain Few-Shot Object Detection Transformer Against Feature Confusion
May 02, 2025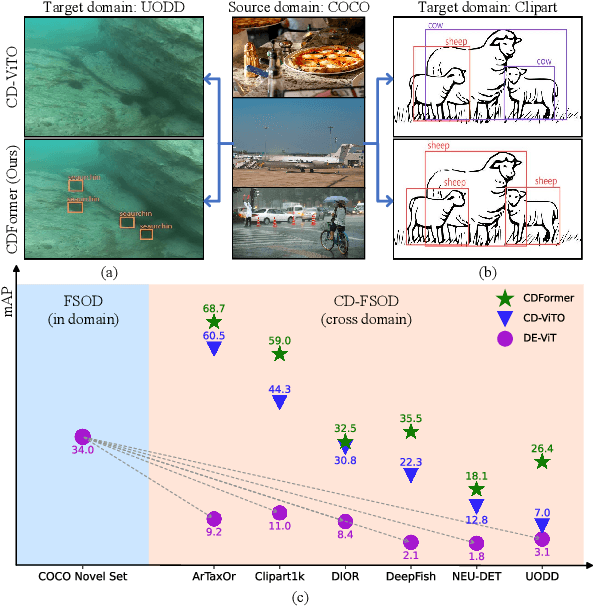
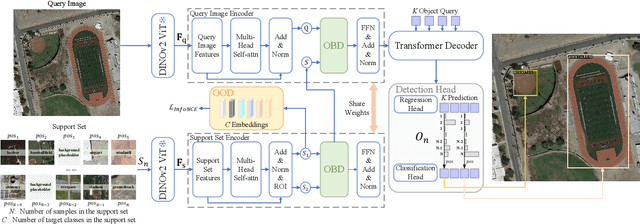

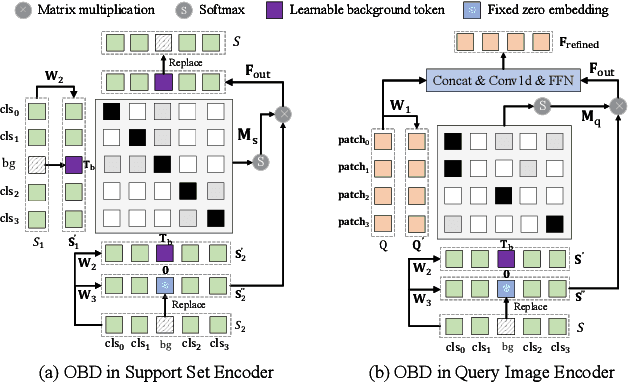
Cross-domain few-shot object detection (CD-FSOD) aims to detect novel objects across different domains with limited class instances. Feature confusion, including object-background confusion and object-object confusion, presents significant challenges in both cross-domain and few-shot settings. In this work, we introduce CDFormer, a cross-domain few-shot object detection transformer against feature confusion, to address these challenges. The method specifically tackles feature confusion through two key modules: object-background distinguishing (OBD) and object-object distinguishing (OOD). The OBD module leverages a learnable background token to differentiate between objects and background, while the OOD module enhances the distinction between objects of different classes. Experimental results demonstrate that CDFormer outperforms previous state-of-the-art approaches, achieving 12.9% mAP, 11.0% mAP, and 10.4% mAP improvements under the 1/5/10 shot settings, respectively, when fine-tuned.
Doracamom: Joint 3D Detection and Occupancy Prediction with Multi-view 4D Radars and Cameras for Omnidirectional Perception
Jan 26, 2025



3D object detection and occupancy prediction are critical tasks in autonomous driving, attracting significant attention. Despite the potential of recent vision-based methods, they encounter challenges under adverse conditions. Thus, integrating cameras with next-generation 4D imaging radar to achieve unified multi-task perception is highly significant, though research in this domain remains limited. In this paper, we propose Doracamom, the first framework that fuses multi-view cameras and 4D radar for joint 3D object detection and semantic occupancy prediction, enabling comprehensive environmental perception. Specifically, we introduce a novel Coarse Voxel Queries Generator that integrates geometric priors from 4D radar with semantic features from images to initialize voxel queries, establishing a robust foundation for subsequent Transformer-based refinement. To leverage temporal information, we design a Dual-Branch Temporal Encoder that processes multi-modal temporal features in parallel across BEV and voxel spaces, enabling comprehensive spatio-temporal representation learning. Furthermore, we propose a Cross-Modal BEV-Voxel Fusion module that adaptively fuses complementary features through attention mechanisms while employing auxiliary tasks to enhance feature quality. Extensive experiments on the OmniHD-Scenes, View-of-Delft (VoD), and TJ4DRadSet datasets demonstrate that Doracamom achieves state-of-the-art performance in both tasks, establishing new benchmarks for multi-modal 3D perception. Code and models will be publicly available.