 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI2P-Rec: Recognizing Images on Large-scale Point Cloud Maps through Bird's Eye View Projections
Paper and Code
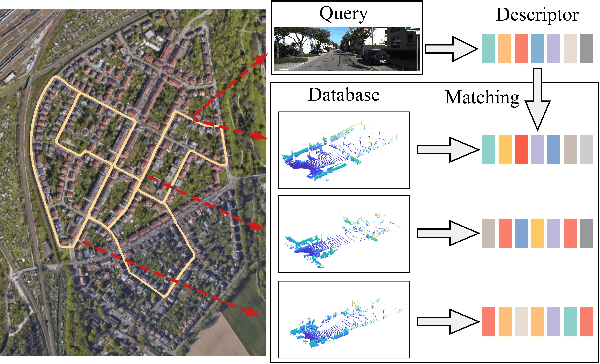
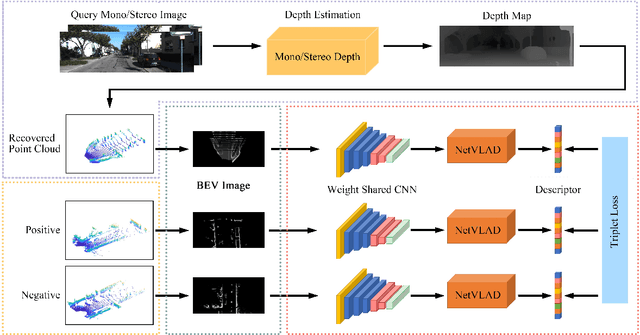
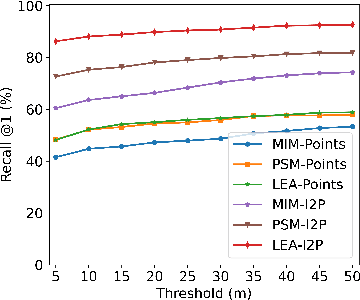

Place recognition is an important technique for autonomous cars to achieve full autonomy since it can provide an initial guess to online localization algorithms. Although current methods based on images or point clouds have achieved satisfactory performance, localizing the images on a large-scale point cloud map remains a fairly unexplored problem. This cross-modal matching task is challenging due to the difficulty in extracting consistent descriptors from images and point clouds. In this paper, we propose the I2P-Rec method to solve the problem by transforming the cross-modal data into the same modality. Specifically, we leverage on the recent success of depth estimation networks to recover point clouds from images. We then project the point clouds into Bird's Eye View (BEV) images. Using the BEV image as an intermediate representation, we extract global features with a Convolutional Neural Network followed by a NetVLAD layer to perform matching. We evaluate our method on the KITTI dataset. The experimental results show that, with only a small set of training data, I2P-Rec can achieve a recall rate at Top-1 over 90\%. Also, it can generalize well to unknown environments, achieving recall rates at Top-1\% over 80\% and 90\%, when localizing monocular images and stereo images on point cloud maps, respectively.