 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS-BEVLoc: BEV-based Self-supervised Framework for Large-scale LiDAR Global Localization
Sep 11, 2025LiDAR-based global localization is an essential component of simultaneous localization and mapping (SLAM), which helps loop closure and re-localization. Current approaches rely on ground-truth poses obtained from GPS or SLAM odometry to supervise network training. Despite the great success of these supervised approaches, substantial cost and effort are required for high-precision ground-truth pose acquisition. In this work, we propose S-BEVLoc, a novel self-supervised framework based on bird's-eye view (BEV) for LiDAR global localization, which eliminates the need for ground-truth poses and is highly scalable. We construct training triplets from single BEV images by leveraging the known geographic distances between keypoint-centered BEV patches. Convolutional neural network (CNN) is used to extract local features, and NetVLAD is employed to aggregate global descriptors. Moreover, we introduce SoftCos loss to enhance learning from the generated triplets. Experimental results on the large-scale KITTI and NCLT datasets show that S-BEVLoc achieves state-of-the-art performance in place recognition, loop closure, and global localization tasks, while offering scalability that would require extra effort for supervised approaches.
Image-Goal Navigation Using Refined Feature Guidance and Scene Graph Enhancement
Mar 14, 2025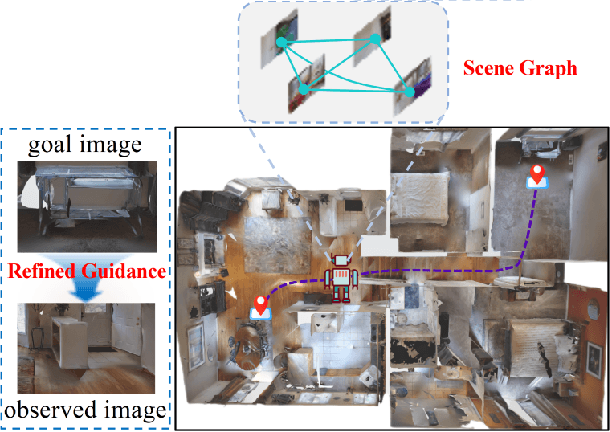
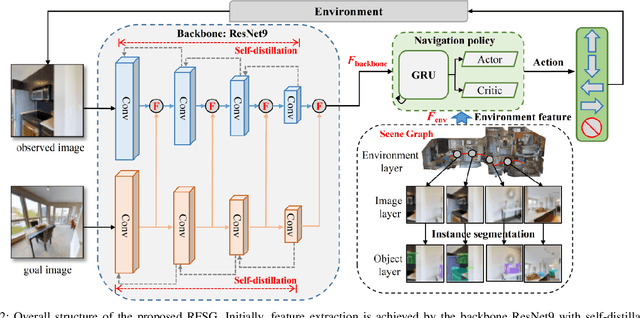
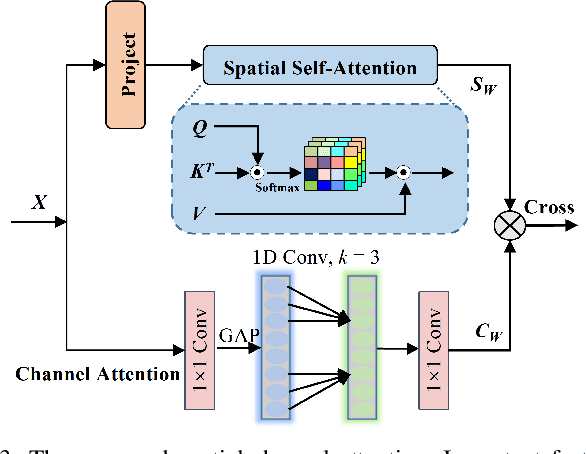
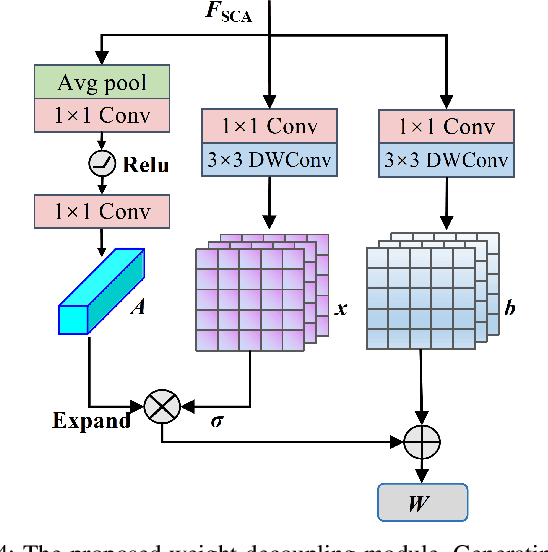
In this paper, we introduce a novel image-goal navigation approach, named RFSG. Our focus lies in leveraging the fine-grained connections between goals, observations, and the environment within limited image data, all the while keeping the navigation architecture simple and lightweight. To this end, we propose the spatial-channel attention mechanism, enabling the network to learn the importance of multi-dimensional features to fuse the goal and observation features. In addition, a selfdistillation mechanism is incorporated to further enhance the feature representation capabilities. Given that the navigation task needs surrounding environmental information for more efficient navigation, we propose an image scene graph to establish feature associations at both the image and object levels, effectively encoding the surrounding scene information. Crossscene performance validation was conducted on the Gibson and HM3D datasets, and the proposed method achieved stateof-the-art results among mainstream methods, with a speed of up to 53.5 frames per second on an RTX3080. This contributes to the realization of end-to-end image-goal navigation in realworld scenarios. The implementation and model of our method have been released at: https://github.com/nubot-nudt/RFSG.
Dust to Tower: Coarse-to-Fine Photo-Realistic Scene Reconstruction from Sparse Uncalibrated Images
Dec 27, 2024



Photo-realistic scene reconstruction from sparse-view, uncalibrated images is highly required in practice. Although some successes have been made, existing methods are either Sparse-View but require accurate camera parameters (i.e., intrinsic and extrinsic), or SfM-free but need densely captured images. To combine the advantages of both methods while addressing their respective weaknesses, we propose Dust to Tower (D2T), an accurate and efficient coarse-to-fine framework to optimize 3DGS and image poses simultaneously from sparse and uncalibrated images. Our key idea is to first construct a coarse model efficiently and subsequently refine it using warped and inpainted images at novel viewpoints. To do this, we first introduce a Coarse Construction Module (CCM) which exploits a fast Multi-View Stereo model to initialize a 3D Gaussian Splatting (3DGS) and recover initial camera poses. To refine the 3D model at novel viewpoints, we propose a Confidence Aware Depth Alignment (CADA) module to refine the coarse depth maps by aligning their confident parts with estimated depths by a Mono-depth model. Then, a Warped Image-Guided Inpainting (WIGI) module is proposed to warp the training images to novel viewpoints by the refined depth maps, and inpainting is applied to fulfill the ``holes" in the warped images caused by view-direction changes, providing high-quality supervision to further optimize the 3D model and the camera poses. Extensive experiments and ablation studies demonstrate the validity of D2T and its design choices, achieving state-of-the-art performance in both tasks of novel view synthesis and pose estimation while keeping high efficiency. Codes will be publicly available.
Autonomous Driving in Unstructured Environments: How Far Have We Come?
Oct 10, 2024

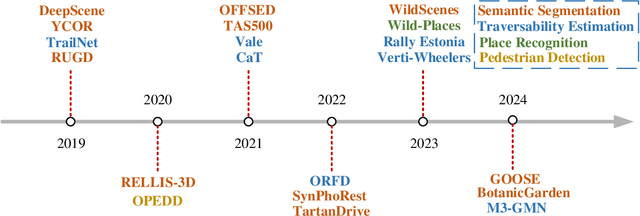

Research on autonomous driving in unstructured outdoor environments is less advanced than in structured urban settings due to challenges like environmental diversities and scene complexity. These environments-such as rural areas and rugged terrains-pose unique obstacles that are not common in structured urban areas. Despite these difficulties, autonomous driving in unstructured outdoor environments is crucial for applications in agriculture, mining, and military operations. Our survey reviews over 250 papers for autonomous driving in unstructured outdoor environments, covering offline mapping, pose estimation, environmental perception, path planning, end-to-end autonomous driving, datasets, and relevant challenges. We also discuss emerging trends and future research directions. This review aims to consolidate knowledge and encourage further research for autonomous driving in unstructured environments. To support ongoing work, we maintain an active repository with up-to-date literature and open-source projects at: https://github.com/chaytonmin/Survey-Autonomous-Driving-in-Unstructured-Environments.
PRISM: PRogressive dependency maxImization for Scale-invariant image Matching
Aug 07, 2024

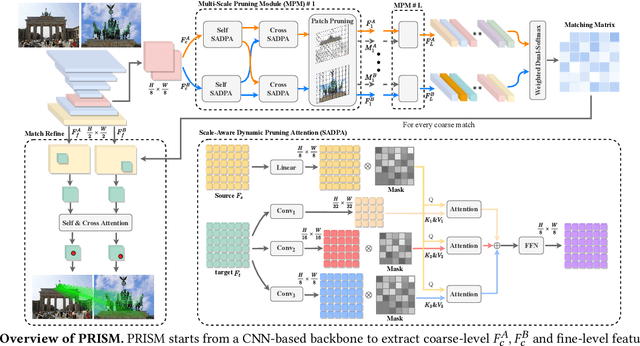

Image matching aims at identifying corresponding points between a pair of images. Currently, detector-free methods have shown impressive performance in challenging scenarios, thanks to their capability of generating dense matches and global receptive field. However, performing feature interaction and proposing matches across the entire image is unnecessary, because not all image regions contribute to the matching process. Interacting and matching in unmatchable areas can introduce errors, reducing matching accuracy and efficiency. Meanwhile, the scale discrepancy issue still troubles existing methods. To address above issues, we propose PRogressive dependency maxImization for Scale-invariant image Matching (PRISM), which jointly prunes irrelevant patch features and tackles the scale discrepancy. To do this, we firstly present a Multi-scale Pruning Module (MPM) to adaptively prune irrelevant features by maximizing the dependency between the two feature sets. Moreover, we design the Scale-Aware Dynamic Pruning Attention (SADPA) to aggregate information from different scales via a hierarchical design. Our method's superior matching performance and generalization capability are confirmed by leading accuracy across various evaluation benchmarks and downstream tasks. The code is publicly available at https://github.com/Master-cai/PRISM.
BEVPlace++: Fast, Robust, and Lightweight LiDAR Global Localization for Unmanned Ground Vehicles
Aug 03, 2024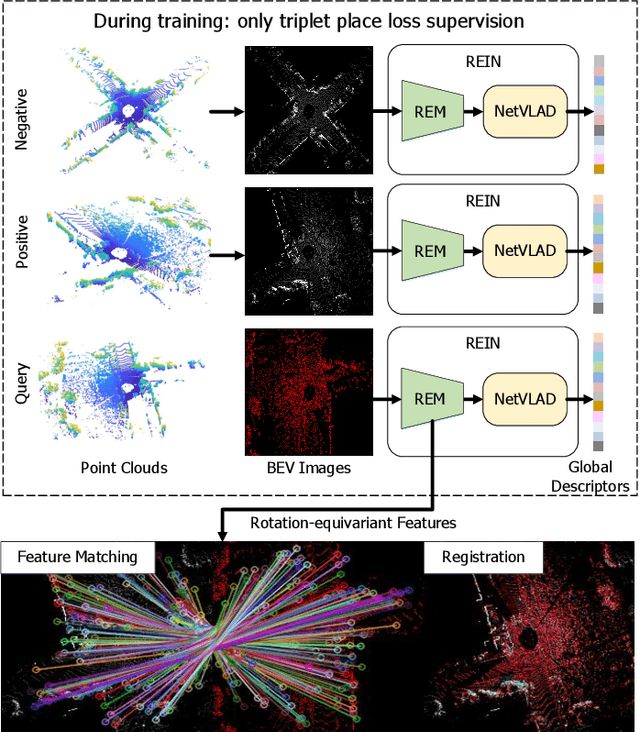
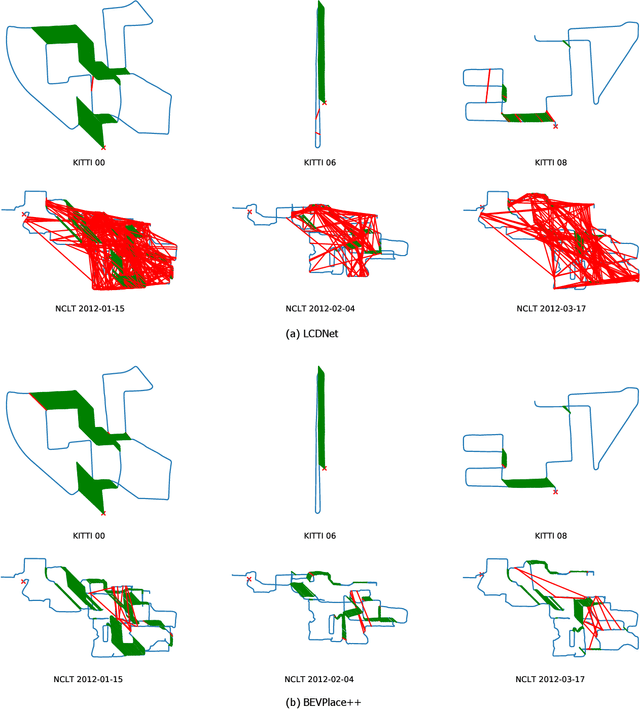
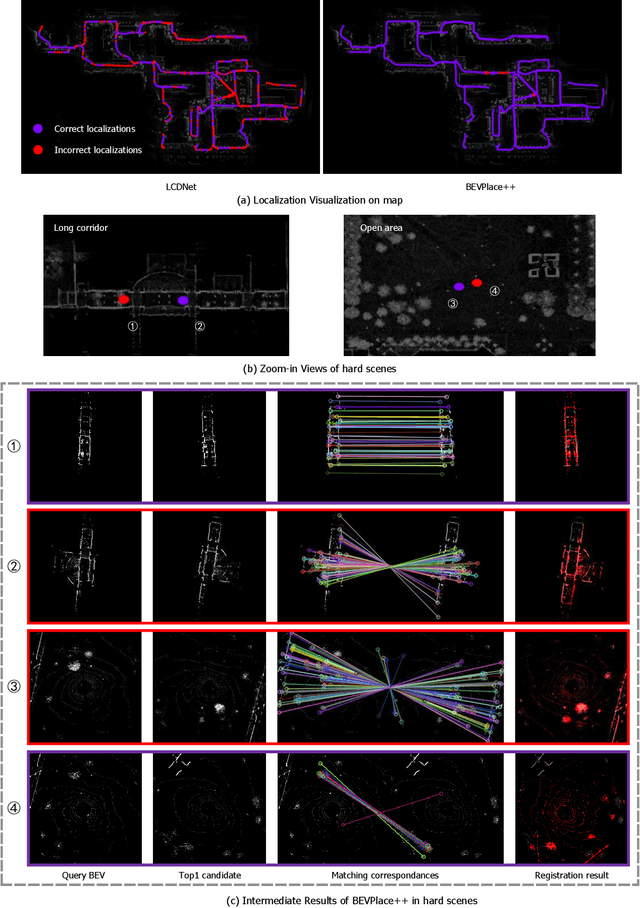
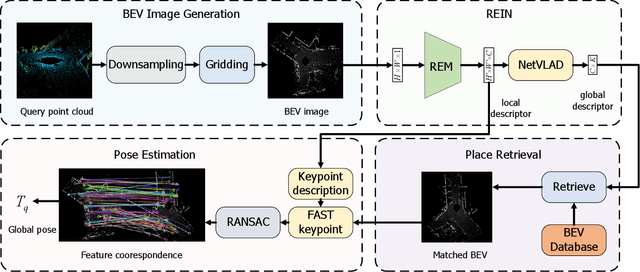
This article introduces BEVPlace++, a novel, fast, and robust LiDAR global localization method for unmanned ground vehicles. It uses lightweight convolutional neural networks (CNNs) on Bird's Eye View (BEV) image-like representations of LiDAR data to achieve accurate global localization through place recognition followed by 3-DoF pose estimation. Our detailed analyses reveal an interesting fact that CNNs are inherently effective at extracting distinctive features from LiDAR BEV images. Remarkably, keypoints of two BEV images with large translations can be effectively matched using CNN-extracted features. Building on this insight, we design a rotation equivariant module (REM) to obtain distinctive features while enhancing robustness to rotational changes. A Rotation Equivariant and Invariant Network (REIN) is then developed by cascading REM and a descriptor generator, NetVLAD, to sequentially generate rotation equivariant local features and rotation invariant global descriptors. The global descriptors are used first to achieve robust place recognition, and the local features are used for accurate pose estimation. Experimental results on multiple public datasets demonstrate that BEVPlace++, even when trained on a small dataset (3000 frames of KITTI) only with place labels, generalizes well to unseen environments, performs consistently across different days and years, and adapts to various types of LiDAR scanners. BEVPlace++ achieves state-of-the-art performance in subtasks of global localization including place recognition, loop closure detection, and global localization. Additionally, BEVPlace++ is lightweight, runs in real-time, and does not require accurate pose supervision, making it highly convenient for deployment. The source codes are publicly available at \href{https://github.com/zjuluolun/BEVPlace}{https://github.com/zjuluolun/BEVPlace}.
SCPNet: Unsupervised Cross-modal Homography Estimation via Intra-modal Self-supervised Learning
Jul 11, 2024



We propose a novel unsupervised cross-modal homography estimation framework based on intra-modal Self-supervised learning, Correlation, and consistent feature map Projection, namely SCPNet. The concept of intra-modal self-supervised learning is first presented to facilitate the unsupervised cross-modal homography estimation. The correlation-based homography estimation network and the consistent feature map projection are combined to form the learnable architecture of SCPNet, boosting the unsupervised learning framework. SCPNet is the first to achieve effective unsupervised homography estimation on the satellite-map image pair cross-modal dataset, GoogleMap, under [-32,+32] offset on a 128x128 image, leading the supervised approach MHN by 14.0% of mean average corner error (MACE). We further conduct extensive experiments on several cross-modal/spectral and manually-made inconsistent datasets, on which SCPNet achieves the state-of-the-art (SOTA) performance among unsupervised approaches, and owns 49.0%, 25.2%, 36.4%, and 10.7% lower MACEs than the supervised approach MHN. Source code is available at https://github.com/RM-Zhang/SCPNet.
Context and Geometry Aware Voxel Transformer for Semantic Scene Completion
May 22, 2024



Vision-based Semantic Scene Completion (SSC) has gained much attention due to its widespread applications in various 3D perception tasks. Existing sparse-to-dense approaches typically employ shared context-independent queries across various input images, which fails to capture distinctions among them as the focal regions of different inputs vary and may result in undirected feature aggregation of cross-attention. Additionally, the absence of depth information may lead to points projected onto the image plane sharing the same 2D position or similar sampling points in the feature map, resulting in depth ambiguity. In this paper, we present a novel context and geometry aware voxel transformer. It utilizes a context aware query generator to initialize context-dependent queries tailored to individual input images, effectively capturing their unique characteristics and aggregating information within the region of interest. Furthermore, it extend deformable cross-attention from 2D to 3D pixel space, enabling the differentiation of points with similar image coordinates based on their depth coordinates. Building upon this module, we introduce a neural network named CGFormer to achieve semantic scene completion. Simultaneously, CGFormer leverages multiple 3D representations (i.e., voxel and TPV) to boost the semantic and geometric representation abilities of the transformed 3D volume from both local and global perspectives. Experimental results demonstrate that CGFormer achieves state-of-the-art performance on the SemanticKITTI and SSCBench-KITTI-360 benchmarks, attaining a mIoU of 16.87 and 20.05, as well as an IoU of 45.99 and 48.07, respectively. Remarkably, CGFormer even outperforms approaches employing temporal images as inputs or much larger image backbone networks. Code for the proposed method is available at https://github.com/pkqbajng/CGFormer.
The RoboDrive Challenge: Drive Anytime Anywhere in Any Condition
May 14, 2024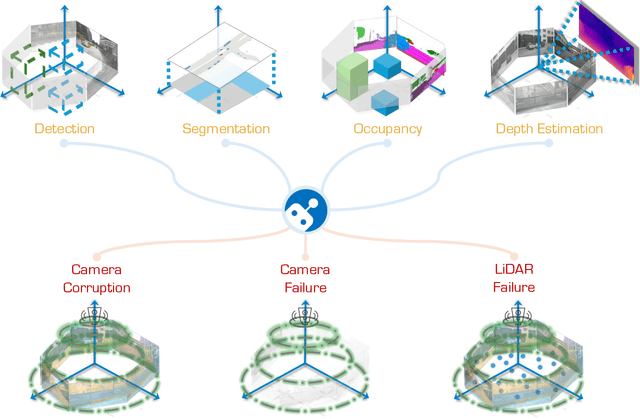


In the realm of autonomous driving, robust perception under out-of-distribution conditions is paramount for the safe deployment of vehicles. Challenges such as adverse weather, sensor malfunctions, and environmental unpredictability can severely impact the performance of autonomous systems. The 2024 RoboDrive Challenge was crafted to propel the development of driving perception technologies that can withstand and adapt to these real-world variabilities. Focusing on four pivotal tasks -- BEV detection, map segmentation, semantic occupancy prediction, and multi-view depth estimation -- the competition laid down a gauntlet to innovate and enhance system resilience against typical and atypical disturbances. This year's challenge consisted of five distinct tracks and attracted 140 registered teams from 93 institutes across 11 countries, resulting in nearly one thousand submissions evaluated through our servers. The competition culminated in 15 top-performing solutions, which introduced a range of innovative approaches including advanced data augmentation, multi-sensor fusion, self-supervised learning for error correction, and new algorithmic strategies to enhance sensor robustness. These contributions significantly advanced the state of the art, particularly in handling sensor inconsistencies and environmental variability. Participants, through collaborative efforts, pushed the boundaries of current technologies, showcasing their potential in real-world scenarios. Extensive evaluations and analyses provided insights into the effectiveness of these solutions, highlighting key trends and successful strategies for improving the resilience of driving perception systems. This challenge has set a new benchmark in the field, providing a rich repository of techniques expected to guide future research in this field.
ModaLink: Unifying Modalities for Efficient Image-to-PointCloud Place Recognition
Mar 27, 2024



Place recognition is an important task for robots and autonomous cars to localize themselves and close loops in pre-built maps. While single-modal sensor-based methods have shown satisfactory performance, cross-modal place recognition that retrieving images from a point-cloud database remains a challenging problem. Current cross-modal methods transform images into 3D points using depth estimation for modality conversion, which are usually computationally intensive and need expensive labeled data for depth supervision. In this work, we introduce a fast and lightweight framework to encode images and point clouds into place-distinctive descriptors. We propose an effective Field of View (FoV) transformation module to convert point clouds into an analogous modality as images. This module eliminates the necessity for depth estimation and helps subsequent modules achieve real-time performance. We further design a non-negative factorization-based encoder to extract mutually consistent semantic features between point clouds and images. This encoder yields more distinctive global descriptors for retrieval. Experimental results on the KITTI dataset show that our proposed methods achieve state-of-the-art performance while running in real time. Additional evaluation on the HAOMO dataset covering a 17 km trajectory further shows the practical generalization capabilities. We have released the implementation of our methods as open source at: https://github.com/haomo-ai/ModaLink.git.