 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMRAG-RFT: Two-stage Reinforcement Fine-tuning for Explainable Multi-modal Retrieval-augmented Generation
Dec 19, 2025Multi-modal Retrieval-Augmented Generation (MMRAG) enables highly credible generation by integrating external multi-modal knowledge, thus demonstrating impressive performance in complex multi-modal scenarios. However, existing MMRAG methods fail to clarify the reasoning logic behind retrieval and response generation, which limits the explainability of the results. To address this gap, we propose to introduce reinforcement learning into multi-modal retrieval-augmented generation, enhancing the reasoning capabilities of multi-modal large language models through a two-stage reinforcement fine-tuning framework to achieve explainable multi-modal retrieval-augmented generation. Specifically, in the first stage, rule-based reinforcement fine-tuning is employed to perform coarse-grained point-wise ranking of multi-modal documents, effectively filtering out those that are significantly irrelevant. In the second stage, reasoning-based reinforcement fine-tuning is utilized to jointly optimize fine-grained list-wise ranking and answer generation, guiding multi-modal large language models to output explainable reasoning logic in the MMRAG process. Our method achieves state-of-the-art results on WebQA and MultimodalQA, two benchmark datasets for multi-modal retrieval-augmented generation, and its effectiveness is validated through comprehensive ablation experiments.
Cog-RAG: Cognitive-Inspired Dual-Hypergraph with Theme Alignment Retrieval-Augmented Generation
Nov 17, 2025Retrieval-Augmented Generation (RAG) enhances the response quality and domain-specific performance of large language models (LLMs) by incorporating external knowledge to combat hallucinations. In recent research, graph structures have been integrated into RAG to enhance the capture of semantic relations between entities. However, it primarily focuses on low-order pairwise entity relations, limiting the high-order associations among multiple entities. Hypergraph-enhanced approaches address this limitation by modeling multi-entity interactions via hyperedges, but they are typically constrained to inter-chunk entity-level representations, overlooking the global thematic organization and alignment across chunks. Drawing inspiration from the top-down cognitive process of human reasoning, we propose a theme-aligned dual-hypergraph RAG framework (Cog-RAG) that uses a theme hypergraph to capture inter-chunk thematic structure and an entity hypergraph to model high-order semantic relations. Furthermore, we design a cognitive-inspired two-stage retrieval strategy that first activates query-relevant thematic content from the theme hypergraph, and then guides fine-grained recall and diffusion in the entity hypergraph, achieving semantic alignment and consistent generation from global themes to local details. Our extensive experiments demonstrate that Cog-RAG significantly outperforms existing state-of-the-art baseline approaches.
* Accepted by AAAI 2026 main conference
SoftHGNN: Soft Hypergraph Neural Networks for General Visual Recognition
May 21, 2025Visual recognition relies on understanding both the semantics of image tokens and the complex interactions among them. Mainstream self-attention methods, while effective at modeling global pair-wise relations, fail to capture high-order associations inherent in real-world scenes and often suffer from redundant computation. Hypergraphs extend conventional graphs by modeling high-order interactions and offer a promising framework for addressing these limitations. However, existing hypergraph neural networks typically rely on static and hard hyperedge assignments, leading to excessive and redundant hyperedges with hard binary vertex memberships that overlook the continuity of visual semantics. To overcome these issues, we present Soft Hypergraph Neural Networks (SoftHGNNs), which extend the methodology of hypergraph computation, to make it truly efficient and versatile in visual recognition tasks. Our framework introduces the concept of soft hyperedges, where each vertex is associated with hyperedges via continuous participation weights rather than hard binary assignments. This dynamic and differentiable association is achieved by using the learnable hyperedge prototype. Through similarity measurements between token features and the prototype, the model generates semantically rich soft hyperedges. SoftHGNN then aggregates messages over soft hyperedges to capture high-order semantics. To further enhance efficiency when scaling up the number of soft hyperedges, we incorporate a sparse hyperedge selection mechanism that activates only the top-k important hyperedges, along with a load-balancing regularizer to ensure balanced hyperedge utilization. Experimental results across three tasks on five datasets demonstrate that SoftHGNN efficiently captures high-order associations in visual scenes, achieving significant performance improvements.
ERetinex: Event Camera Meets Retinex Theory for Low-Light Image Enhancement
Mar 04, 2025Low-light image enhancement aims to restore the under-exposure image captured in dark scenarios. Under such scenarios, traditional frame-based cameras may fail to capture the structure and color information due to the exposure time limitation. Event cameras are bio-inspired vision sensors that respond to pixel-wise brightness changes asynchronously. Event cameras' high dynamic range is pivotal for visual perception in extreme low-light scenarios, surpassing traditional cameras and enabling applications in challenging dark environments. In this paper, inspired by the success of the retinex theory for traditional frame-based low-light image restoration, we introduce the first methods that combine the retinex theory with event cameras and propose a novel retinex-based low-light image restoration framework named ERetinex. Among our contributions, the first is developing a new approach that leverages the high temporal resolution data from event cameras with traditional image information to estimate scene illumination accurately. This method outperforms traditional image-only techniques, especially in low-light environments, by providing more precise lighting information. Additionally, we propose an effective fusion strategy that combines the high dynamic range data from event cameras with the color information of traditional images to enhance image quality. Through this fusion, we can generate clearer and more detail-rich images, maintaining the integrity of visual information even under extreme lighting conditions. The experimental results indicate that our proposed method outperforms state-of-the-art (SOTA) methods, achieving a gain of 1.0613 dB in PSNR while reducing FLOPS by \textbf{84.28}\%.
Hypergraph Foundation Model
Mar 03, 2025



Hypergraph neural networks (HGNNs) effectively model complex high-order relationships in domains like protein interactions and social networks by connecting multiple vertices through hyperedges, enhancing modeling capabilities, and reducing information loss. Developing foundation models for hypergraphs is challenging due to their distinct data, which includes both vertex features and intricate structural information. We present Hyper-FM, a Hypergraph Foundation Model for multi-domain knowledge extraction, featuring Hierarchical High-Order Neighbor Guided Vertex Knowledge Embedding for vertex feature representation and Hierarchical Multi-Hypergraph Guided Structural Knowledge Extraction for structural information. Additionally, we curate 10 text-attributed hypergraph datasets to advance research between HGNNs and LLMs. Experiments on these datasets show that Hyper-FM outperforms baseline methods by approximately 13.3\%, validating our approach. Furthermore, we propose the first scaling law for hypergraph foundation models, demonstrating that increasing domain diversity significantly enhances performance, unlike merely augmenting vertex and hyperedge counts. This underscores the critical role of domain diversity in scaling hypergraph models.
Beyond Graphs: Can Large Language Models Comprehend Hypergraphs?
Oct 14, 2024



Existing benchmarks like NLGraph and GraphQA evaluate LLMs on graphs by focusing mainly on pairwise relationships, overlooking the high-order correlations found in real-world data. Hypergraphs, which can model complex beyond-pairwise relationships, offer a more robust framework but are still underexplored in the context of LLMs. To address this gap, we introduce LLM4Hypergraph, the first comprehensive benchmark comprising 21,500 problems across eight low-order, five high-order, and two isomorphism tasks, utilizing both synthetic and real-world hypergraphs from citation networks and protein structures. We evaluate six prominent LLMs, including GPT-4o, demonstrating our benchmark's effectiveness in identifying model strengths and weaknesses. Our specialized prompting framework incorporates seven hypergraph languages and introduces two novel techniques, Hyper-BAG and Hyper-COT, which enhance high-order reasoning and achieve an average 4% (up to 9%) performance improvement on structure classification tasks. This work establishes a foundational testbed for integrating hypergraph computational capabilities into LLMs, advancing their comprehension.
Hyper-YOLO: When Visual Object Detection Meets Hypergraph Computation
Aug 09, 2024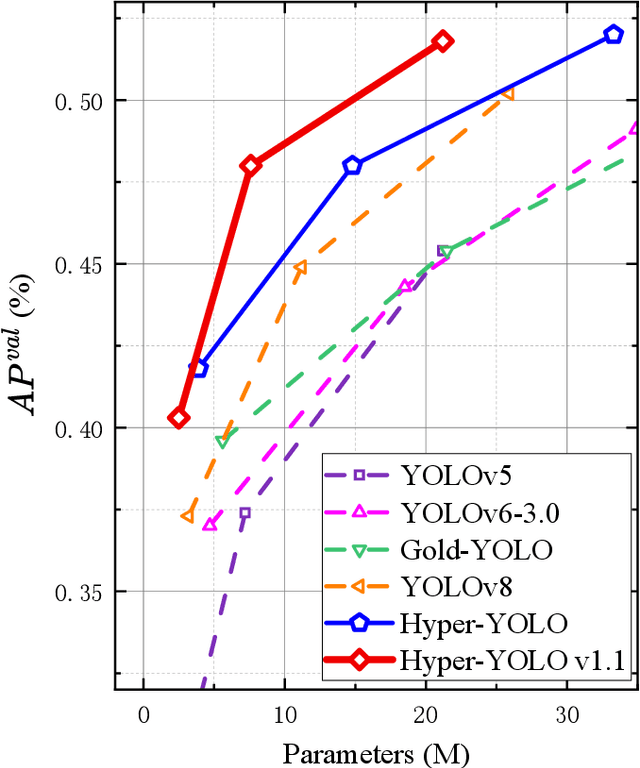
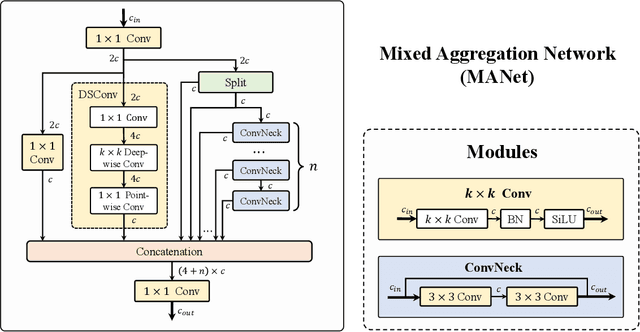
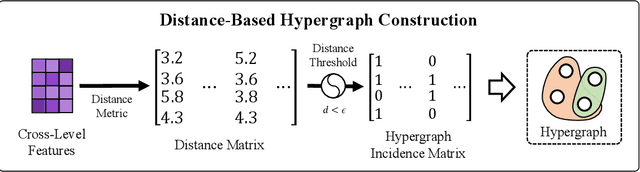
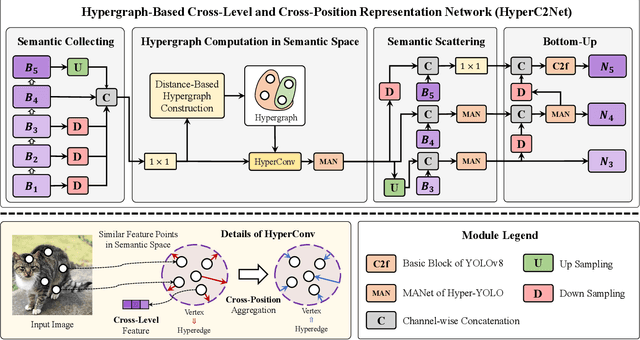
We introduce Hyper-YOLO, a new object detection method that integrates hypergraph computations to capture the complex high-order correlations among visual features. Traditional YOLO models, while powerful, have limitations in their neck designs that restrict the integration of cross-level features and the exploitation of high-order feature interrelationships. To address these challenges, we propose the Hypergraph Computation Empowered Semantic Collecting and Scattering (HGC-SCS) framework, which transposes visual feature maps into a semantic space and constructs a hypergraph for high-order message propagation. This enables the model to acquire both semantic and structural information, advancing beyond conventional feature-focused learning. Hyper-YOLO incorporates the proposed Mixed Aggregation Network (MANet) in its backbone for enhanced feature extraction and introduces the Hypergraph-Based Cross-Level and Cross-Position Representation Network (HyperC2Net) in its neck. HyperC2Net operates across five scales and breaks free from traditional grid structures, allowing for sophisticated high-order interactions across levels and positions. This synergy of components positions Hyper-YOLO as a state-of-the-art architecture in various scale models, as evidenced by its superior performance on the COCO dataset. Specifically, Hyper-YOLO-N significantly outperforms the advanced YOLOv8-N and YOLOv9-T with 12\% $\text{AP}^{val}$ and 9\% $\text{AP}^{val}$ improvements. The source codes are at ttps://github.com/iMoonLab/Hyper-YOLO.
PARE-Net: Position-Aware Rotation-Equivariant Networks for Robust Point Cloud Registration
Jul 14, 2024Learning rotation-invariant distinctive features is a fundamental requirement for point cloud registration. Existing methods often use rotation-sensitive networks to extract features, while employing rotation augmentation to learn an approximate invariant mapping rudely. This makes networks fragile to rotations, overweight, and hinders the distinctiveness of features. To tackle these problems, we propose a novel position-aware rotation-equivariant network, for efficient, light-weighted, and robust registration. The network can provide a strong model inductive bias to learn rotation-equivariant/invariant features, thus addressing the aforementioned limitations. To further improve the distinctiveness of descriptors, we propose a position-aware convolution, which can better learn spatial information of local structures. Moreover, we also propose a feature-based hypothesis proposer. It leverages rotation-equivariant features that encode fine-grained structure orientations to generate reliable model hypotheses. Each correspondence can generate a hypothesis, thus it is more efficient than classic estimators that require multiple reliable correspondences. Accordingly, a contrastive rotation loss is presented to enhance the robustness of rotation-equivariant features against data degradation. Extensive experiments on indoor and outdoor datasets demonstrate that our method significantly outperforms the SOTA methods in terms of registration recall while being lightweight and keeping a fast speed. Moreover, experiments on rotated datasets demonstrate its robustness against rotation variations. Code is available at https://github.com/yaorz97/PARENet.
Multi-Condition Latent Diffusion Network for Scene-Aware Neural Human Motion Prediction
May 30, 2024



Inferring 3D human motion is fundamental in many applications, including understanding human activity and analyzing one's intention. While many fruitful efforts have been made to human motion prediction, most approaches focus on pose-driven prediction and inferring human motion in isolation from the contextual environment, thus leaving the body location movement in the scene behind. However, real-world human movements are goal-directed and highly influenced by the spatial layout of their surrounding scenes. In this paper, instead of planning future human motion in a 'dark' room, we propose a Multi-Condition Latent Diffusion network (MCLD) that reformulates the human motion prediction task as a multi-condition joint inference problem based on the given historical 3D body motion and the current 3D scene contexts. Specifically, instead of directly modeling joint distribution over the raw motion sequences, MCLD performs a conditional diffusion process within the latent embedding space, characterizing the cross-modal mapping from the past body movement and current scene context condition embeddings to the future human motion embedding. Extensive experiments on large-scale human motion prediction datasets demonstrate that our MCLD achieves significant improvements over the state-of-the-art methods on both realistic and diverse predictions.
Learning a Category-level Object Pose Estimator without Pose Annotations
Apr 08, 2024



3D object pose estimation is a challenging task. Previous works always require thousands of object images with annotated poses for learning the 3D pose correspondence, which is laborious and time-consuming for labeling. In this paper, we propose to learn a category-level 3D object pose estimator without pose annotations. Instead of using manually annotated images, we leverage diffusion models (e.g., Zero-1-to-3) to generate a set of images under controlled pose differences and propose to learn our object pose estimator with those images. Directly using the original diffusion model leads to images with noisy poses and artifacts. To tackle this issue, firstly, we exploit an image encoder, which is learned from a specially designed contrastive pose learning, to filter the unreasonable details and extract image feature maps. Additionally, we propose a novel learning strategy that allows the model to learn object poses from those generated image sets without knowing the alignment of their canonical poses. Experimental results show that our method has the capability of category-level object pose estimation from a single shot setting (as pose definition), while significantly outperforming other state-of-the-art methods on the few-shot category-level object pose estimation benchmarks.