 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePARE-Net: Position-Aware Rotation-Equivariant Networks for Robust Point Cloud Registration
Jul 14, 2024Learning rotation-invariant distinctive features is a fundamental requirement for point cloud registration. Existing methods often use rotation-sensitive networks to extract features, while employing rotation augmentation to learn an approximate invariant mapping rudely. This makes networks fragile to rotations, overweight, and hinders the distinctiveness of features. To tackle these problems, we propose a novel position-aware rotation-equivariant network, for efficient, light-weighted, and robust registration. The network can provide a strong model inductive bias to learn rotation-equivariant/invariant features, thus addressing the aforementioned limitations. To further improve the distinctiveness of descriptors, we propose a position-aware convolution, which can better learn spatial information of local structures. Moreover, we also propose a feature-based hypothesis proposer. It leverages rotation-equivariant features that encode fine-grained structure orientations to generate reliable model hypotheses. Each correspondence can generate a hypothesis, thus it is more efficient than classic estimators that require multiple reliable correspondences. Accordingly, a contrastive rotation loss is presented to enhance the robustness of rotation-equivariant features against data degradation. Extensive experiments on indoor and outdoor datasets demonstrate that our method significantly outperforms the SOTA methods in terms of registration recall while being lightweight and keeping a fast speed. Moreover, experiments on rotated datasets demonstrate its robustness against rotation variations. Code is available at https://github.com/yaorz97/PARENet.
Advancing Pre-trained Teacher: Towards Robust Feature Discrepancy for Anomaly Detection
May 03, 2024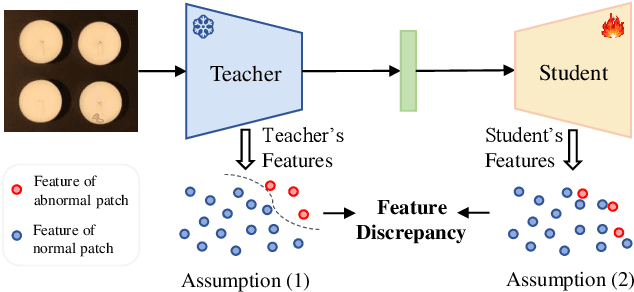
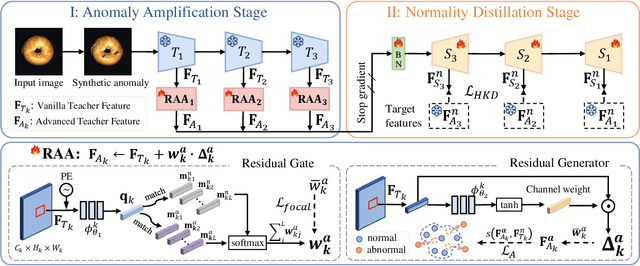
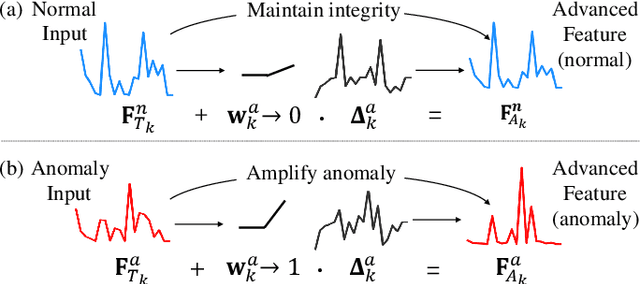
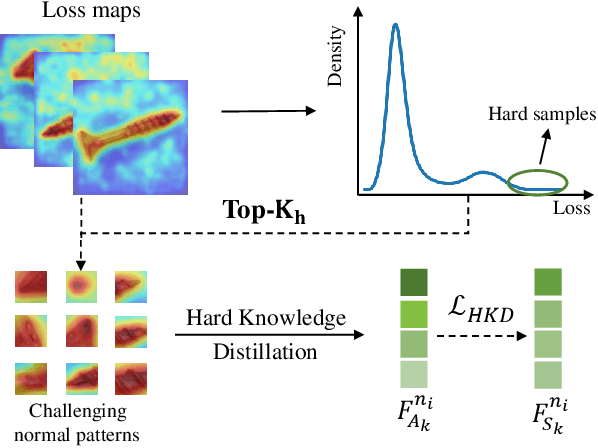
With the wide application of knowledge distillation between an ImageNet pre-trained teacher model and a learnable student model, industrial anomaly detection has witnessed a significant achievement in the past few years. The success of knowledge distillation mainly relies on how to keep the feature discrepancy between the teacher and student model, in which it assumes that: (1) the teacher model can jointly represent two different distributions for the normal and abnormal patterns, while (2) the student model can only reconstruct the normal distribution. However, it still remains a challenging issue to maintain these ideal assumptions in practice. In this paper, we propose a simple yet effective two-stage industrial anomaly detection framework, termed as AAND, which sequentially performs Anomaly Amplification and Normality Distillation to obtain robust feature discrepancy. In the first anomaly amplification stage, we propose a novel Residual Anomaly Amplification (RAA) module to advance the pre-trained teacher encoder. With the exposure of synthetic anomalies, it amplifies anomalies via residual generation while maintaining the integrity of pre-trained model. It mainly comprises a Matching-guided Residual Gate and an Attribute-scaling Residual Generator, which can determine the residuals' proportion and characteristic, respectively. In the second normality distillation stage, we further employ a reverse distillation paradigm to train a student decoder, in which a novel Hard Knowledge Distillation (HKD) loss is built to better facilitate the reconstruction of normal patterns. Comprehensive experiments on the MvTecAD, VisA, and MvTec3D-RGB datasets show that our method achieves state-of-the-art performance.
HD2Reg: Hierarchical Descriptors and Detectors for Point Cloud Registration
May 05, 2023



Feature Descriptors and Detectors are two main components of feature-based point cloud registration. However, little attention has been drawn to the explicit representation of local and global semantics in the learning of descriptors and detectors. In this paper, we present a framework that explicitly extracts dual-level descriptors and detectors and performs coarse-to-fine matching with them. First, to explicitly learn local and global semantics, we propose a hierarchical contrastive learning strategy, training the robust matching ability of high-level descriptors, and refining the local feature space using low-level descriptors. Furthermore, we propose to learn dual-level saliency maps that extract two groups of keypoints in two different senses. To overcome the weak supervision of binary matchability labels, we propose a ranking strategy to label the significance ranking of keypoints, and thus provide more fine-grained supervision signals. Finally, we propose a global-to-local matching scheme to obtain robust and accurate correspondences by leveraging the complementary dual-level features.Quantitative experiments on 3DMatch and KITTI odometry datasets show that our method achieves robust and accurate point cloud registration and outperforms recent keypoint-based methods.
HybridPoint: Point Cloud Registration Based on Hybrid Point Sampling and Matching
Apr 23, 2023



Patch-to-point matching has become a robust way of point cloud registration. However, previous patch-matching methods employ superpoints with poor localization precision as nodes, which may lead to ambiguous patch partitions. In this paper, we propose a HybridPoint-based network to find more robust and accurate correspondences. Firstly, we propose to use salient points with prominent local features as nodes to increase patch repeatability, and introduce some uniformly distributed points to complete the point cloud, thus constituting hybrid points. Hybrid points not only have better localization precision but also give a complete picture of the whole point cloud. Furthermore, based on the characteristic of hybrid points, we propose a dual-classes patch matching module, which leverages the matching results of salient points and filters the matching noise of non-salient points. Experiments show that our model achieves state-of-the-art performance on 3DMatch, 3DLoMatch, and KITTI odometry, especially with 93.0% Registration Recall on the 3DMatch dataset. Our code and models are available at https://github.com/liyih/HybridPoint.