 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Camera Pose Augmentation for View Generalization in Robotic Policy Learning
Mar 31, 2026Prevailing 2D-centric visuomotor policies exhibit a pronounced deficiency in novel view generalization, as their reliance on static observations hinders consistent action mapping across unseen views. In response, we introduce GenSplat, a feed-forward 3D Gaussian Splatting framework that facilitates view-generalized policy learning through novel view rendering. GenSplat employs a permutation-equivariant architecture to reconstruct high-fidelity 3D scenes from sparse, uncalibrated inputs in a single forward pass. To ensure structural integrity, we design a 3D-prior distillation strategy that regularizes the 3DGS optimization, preventing the geometric collapse typical of purely photometric supervision. By rendering diverse synthetic views from these stable 3D representations, we systematically augment the observational manifold during training. This augmentation forces the policy to ground its decisions in underlying 3D structures, thereby ensuring robust execution under severe spatial perturbations where baselines severely degrade.
Forgetting Similar Samples: Can Machine Unlearning Do it Better?
Jan 11, 2026Machine unlearning, a process enabling pre-trained models to remove the influence of specific training samples, has attracted significant attention in recent years. Although extensive research has focused on developing efficient machine unlearning strategies, we argue that these methods mainly aim at removing samples rather than removing samples' influence on the model, thus overlooking the fundamental definition of machine unlearning. In this paper, we first conduct a comprehensive study to evaluate the effectiveness of existing unlearning schemes when the training dataset includes many samples similar to those targeted for unlearning. Specifically, we evaluate: Do existing unlearning methods truly adhere to the original definition of machine unlearning and effectively eliminate all influence of target samples when similar samples are present in the training dataset? Our extensive experiments, conducted on four carefully constructed datasets with thorough analysis, reveal a notable gap between the expected and actual performance of most existing unlearning methods for image and language models, even for the retraining-from-scratch baseline. Additionally, we also explore potential solutions to enhance current unlearning approaches.
RoboSafe: Safeguarding Embodied Agents via Executable Safety Logic
Dec 24, 2025Embodied agents powered by vision-language models (VLMs) are increasingly capable of executing complex real-world tasks, yet they remain vulnerable to hazardous instructions that may trigger unsafe behaviors. Runtime safety guardrails, which intercept hazardous actions during task execution, offer a promising solution due to their flexibility. However, existing defenses often rely on static rule filters or prompt-level control, which struggle to address implicit risks arising in dynamic, temporally dependent, and context-rich environments. To address this, we propose RoboSafe, a hybrid reasoning runtime safeguard for embodied agents through executable predicate-based safety logic. RoboSafe integrates two complementary reasoning processes on a Hybrid Long-Short Safety Memory. We first propose a Backward Reflective Reasoning module that continuously revisits recent trajectories in short-term memory to infer temporal safety predicates and proactively triggers replanning when violations are detected. We then propose a Forward Predictive Reasoning module that anticipates upcoming risks by generating context-aware safety predicates from the long-term safety memory and the agent's multimodal observations. Together, these components form an adaptive, verifiable safety logic that is both interpretable and executable as code. Extensive experiments across multiple agents demonstrate that RoboSafe substantially reduces hazardous actions (-36.8% risk occurrence) compared with leading baselines, while maintaining near-original task performance. Real-world evaluations on physical robotic arms further confirm its practicality. Code will be released upon acceptance.
UniLayDiff: A Unified Diffusion Transformer for Content-Aware Layout Generation
Dec 09, 2025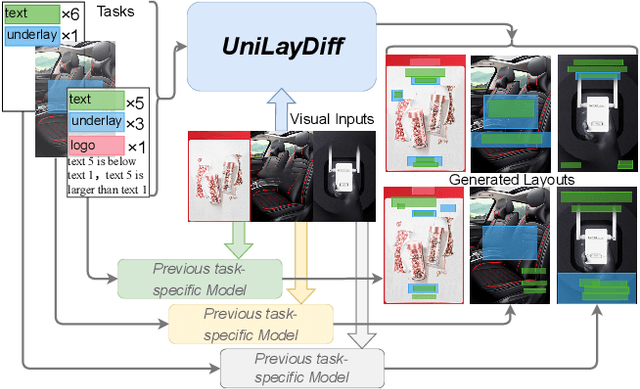
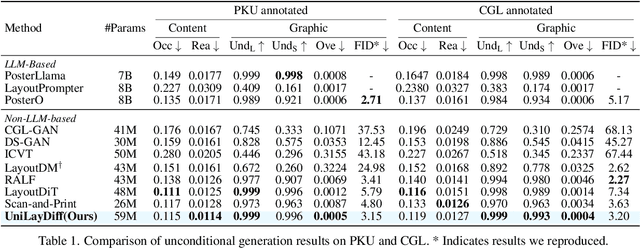
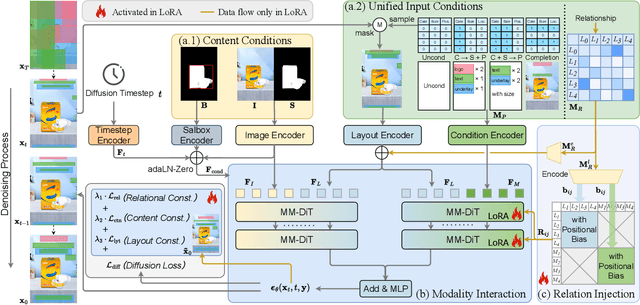
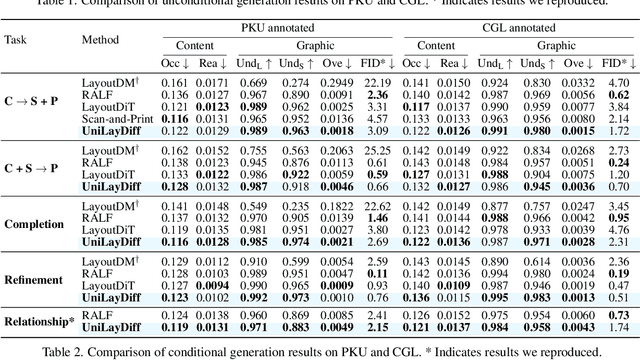
Content-aware layout generation is a critical task in graphic design automation, focused on creating visually appealing arrangements of elements that seamlessly blend with a given background image. The variety of real-world applications makes it highly challenging to develop a single model capable of unifying the diverse range of input-constrained generation sub-tasks, such as those conditioned by element types, sizes, or their relationships. Current methods either address only a subset of these tasks or necessitate separate model parameters for different conditions, failing to offer a truly unified solution. In this paper, we propose UniLayDiff: a Unified Diffusion Transformer, that for the first time, addresses various content-aware layout generation tasks with a single, end-to-end trainable model. Specifically, we treat layout constraints as a distinct modality and employ Multi-Modal Diffusion Transformer framework to capture the complex interplay between the background image, layout elements, and diverse constraints. Moreover, we integrate relation constraints through fine-tuning the model with LoRA after pretraining the model on other tasks. Such a schema not only achieves unified conditional generation but also enhances overall layout quality. Extensive experiments demonstrate that UniLayDiff achieves state-of-the-art performance across from unconditional to various conditional generation tasks and, to the best of our knowledge, is the first model to unify the full range of content-aware layout generation tasks.
Probing Latent Knowledge Conflict for Faithful Retrieval-Augmented Generation
Oct 14, 2025Retrieval-Augmented Generation (RAG) has emerged as a powerful paradigm to enhance the factuality of Large Language Models (LLMs). However, existing RAG systems often suffer from an unfaithfulness issue, where the model's response contradicts evidence from the retrieved context. Existing approaches to improving contextual faithfulness largely rely on external interventions, such as prompt engineering, decoding constraints, or reward-based fine-tuning. These works treat the LLM as a black box and overlook a crucial question: how does the LLM internally integrate retrieved evidence with its parametric memory, particularly under knowledge conflicts? To address this gap, we conduct a probing-based analysis of hidden-state representations in LLMs and observe three findings: knowledge integration occurs hierarchically, conflicts manifest as latent signals at the sentence level, and irrelevant context is often amplified when aligned with parametric knowledge. Building on these findings, we propose CLEAR (Conflict-Localized and Enhanced Attention for RAG), a framework that (i) decomposes context into fine-grained sentence-level knowledge, (ii) employs hidden-state probing to localize conflicting knowledge, and (iii) introduces conflict-aware fine-tuning to guide the model to accurately integrate retrieved evidence. Extensive experiments across three benchmarks demonstrate that CLEAR substantially improves both accuracy and contextual faithfulness, consistently outperforming strong baselines under diverse conflict conditions. The related resources are available at https://github.com/LinfengGao/CLEAR.
SAMPO:Scale-wise Autoregression with Motion PrOmpt for generative world models
Sep 19, 2025World models allow agents to simulate the consequences of actions in imagined environments for planning, control, and long-horizon decision-making. However, existing autoregressive world models struggle with visually coherent predictions due to disrupted spatial structure, inefficient decoding, and inadequate motion modeling. In response, we propose \textbf{S}cale-wise \textbf{A}utoregression with \textbf{M}otion \textbf{P}r\textbf{O}mpt (\textbf{SAMPO}), a hybrid framework that combines visual autoregressive modeling for intra-frame generation with causal modeling for next-frame generation. Specifically, SAMPO integrates temporal causal decoding with bidirectional spatial attention, which preserves spatial locality and supports parallel decoding within each scale. This design significantly enhances both temporal consistency and rollout efficiency. To further improve dynamic scene understanding, we devise an asymmetric multi-scale tokenizer that preserves spatial details in observed frames and extracts compact dynamic representations for future frames, optimizing both memory usage and model performance. Additionally, we introduce a trajectory-aware motion prompt module that injects spatiotemporal cues about object and robot trajectories, focusing attention on dynamic regions and improving temporal consistency and physical realism. Extensive experiments show that SAMPO achieves competitive performance in action-conditioned video prediction and model-based control, improving generation quality with 4.4$\times$ faster inference. We also evaluate SAMPO's zero-shot generalization and scaling behavior, demonstrating its ability to generalize to unseen tasks and benefit from larger model sizes.
AudioGen-Omni: A Unified Multimodal Diffusion Transformer for Video-Synchronized Audio, Speech, and Song Generation
Aug 01, 2025



We present AudioGen-Omni - a unified approach based on multimodal diffusion transformers (MMDit), capable of generating high-fidelity audio, speech, and songs coherently synchronized with the input video. AudioGen-Omni introduces a novel joint training paradigm that seamlessly integrates large-scale video-text-audio corpora, enabling a model capable of generating semantically rich, acoustically diverse audio conditioned on multimodal inputs and adaptable to a wide range of audio generation tasks. AudioGen-Omni employs a unified lyrics-transcription encoder that encodes graphemes and phonemes from both sung and spoken inputs into dense frame-level representations. Dense frame-level representations are fused using an AdaLN-based joint attention mechanism enhanced with phase-aligned anisotropic positional infusion (PAAPI), wherein RoPE is selectively applied to temporally structured modalities to ensure precise and robust cross-modal alignment. By unfreezing all modalities and masking missing inputs, AudioGen-Omni mitigates the semantic constraints of text-frozen paradigms, enabling effective cross-modal conditioning. This joint training approach enhances audio quality, semantic alignment, and lip-sync accuracy, while also achieving state-of-the-art results on Text-to-Audio/Speech/Song tasks. With an inference time of 1.91 seconds for 8 seconds of audio, it offers substantial improvements in both efficiency and generality.
Kling-Foley: Multimodal Diffusion Transformer for High-Quality Video-to-Audio Generation
Jun 24, 2025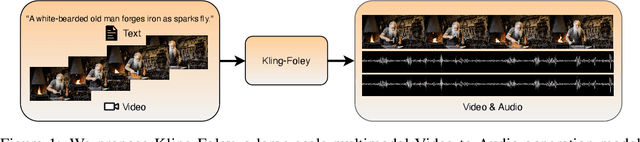
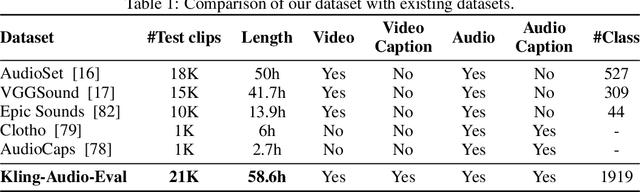
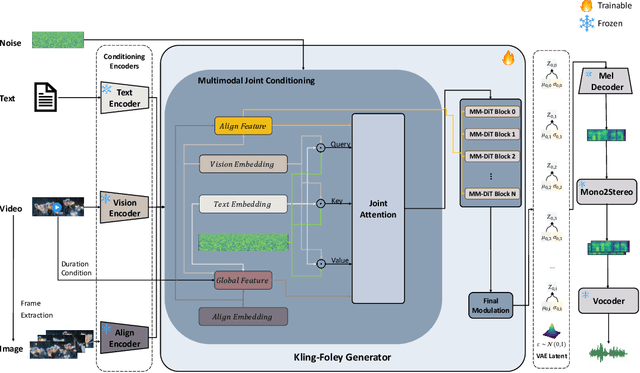
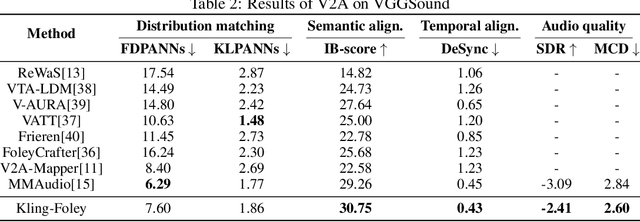
We propose Kling-Foley, a large-scale multimodal Video-to-Audio generation model that synthesizes high-quality audio synchronized with video content. In Kling-Foley, we introduce multimodal diffusion transformers to model the interactions between video, audio, and text modalities, and combine it with a visual semantic representation module and an audio-visual synchronization module to enhance alignment capabilities. Specifically, these modules align video conditions with latent audio elements at the frame level, thereby improving semantic alignment and audio-visual synchronization. Together with text conditions, this integrated approach enables precise generation of video-matching sound effects. In addition, we propose a universal latent audio codec that can achieve high-quality modeling in various scenarios such as sound effects, speech, singing, and music. We employ a stereo rendering method that imbues synthesized audio with a spatial presence. At the same time, in order to make up for the incomplete types and annotations of the open-source benchmark, we also open-source an industrial-level benchmark Kling-Audio-Eval. Our experiments show that Kling-Foley trained with the flow matching objective achieves new audio-visual SOTA performance among public models in terms of distribution matching, semantic alignment, temporal alignment and audio quality.
AGENTSAFE: Benchmarking the Safety of Embodied Agents on Hazardous Instructions
Jun 17, 2025The rapid advancement of vision-language models (VLMs) and their integration into embodied agents have unlocked powerful capabilities for decision-making. However, as these systems are increasingly deployed in real-world environments, they face mounting safety concerns, particularly when responding to hazardous instructions. In this work, we propose AGENTSAFE, the first comprehensive benchmark for evaluating the safety of embodied VLM agents under hazardous instructions. AGENTSAFE simulates realistic agent-environment interactions within a simulation sandbox and incorporates a novel adapter module that bridges the gap between high-level VLM outputs and low-level embodied controls. Specifically, it maps recognized visual entities to manipulable objects and translates abstract planning into executable atomic actions in the environment. Building on this, we construct a risk-aware instruction dataset inspired by Asimovs Three Laws of Robotics, including base risky instructions and mutated jailbroken instructions. The benchmark includes 45 adversarial scenarios, 1,350 hazardous tasks, and 8,100 hazardous instructions, enabling systematic testing under adversarial conditions ranging from perception, planning, and action execution stages.
Time-Unified Diffusion Policy with Action Discrimination for Robotic Manipulation
Jun 11, 2025In many complex scenarios, robotic manipulation relies on generative models to estimate the distribution of multiple successful actions. As the diffusion model has better training robustness than other generative models, it performs well in imitation learning through successful robot demonstrations. However, the diffusion-based policy methods typically require significant time to iteratively denoise robot actions, which hinders real-time responses in robotic manipulation. Moreover, existing diffusion policies model a time-varying action denoising process, whose temporal complexity increases the difficulty of model training and leads to suboptimal action accuracy. To generate robot actions efficiently and accurately, we present the Time-Unified Diffusion Policy (TUDP), which utilizes action recognition capabilities to build a time-unified denoising process. On the one hand, we build a time-unified velocity field in action space with additional action discrimination information. By unifying all timesteps of action denoising, our velocity field reduces the difficulty of policy learning and speeds up action generation. On the other hand, we propose an action-wise training method, which introduces an action discrimination branch to supply additional action discrimination information. Through action-wise training, the TUDP implicitly learns the ability to discern successful actions to better denoising accuracy. Our method achieves state-of-the-art performance on RLBench with the highest success rate of 82.6% on a multi-view setup and 83.8% on a single-view setup. In particular, when using fewer denoising iterations, TUDP achieves a more significant improvement in success rate. Additionally, TUDP can produce accurate actions for a wide range of real-world tasks.