 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Semantic-constrained Adversarial Example with Instruction Uncertainty Reduction
Oct 27, 2025
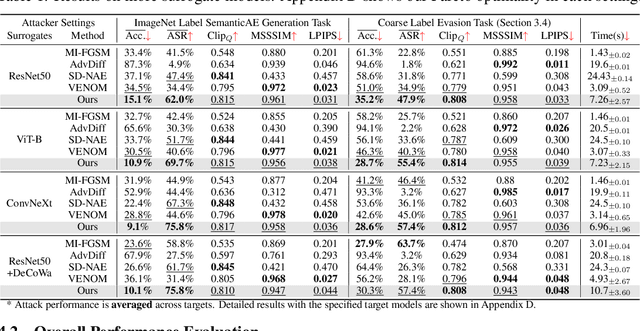
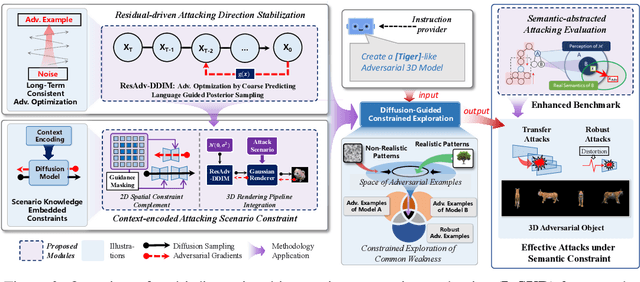

Recently, semantically constrained adversarial examples (SemanticAE), which are directly generated from natural language instructions, have become a promising avenue for future research due to their flexible attacking forms. To generate SemanticAEs, current methods fall short of satisfactory attacking ability as the key underlying factors of semantic uncertainty in human instructions, such as referring diversity, descriptive incompleteness, and boundary ambiguity, have not been fully investigated. To tackle the issues, this paper develops a multi-dimensional instruction uncertainty reduction (InSUR) framework to generate more satisfactory SemanticAE, i.e., transferable, adaptive, and effective. Specifically, in the dimension of the sampling method, we propose the residual-driven attacking direction stabilization to alleviate the unstable adversarial optimization caused by the diversity of language references. By coarsely predicting the language-guided sampling process, the optimization process will be stabilized by the designed ResAdv-DDIM sampler, therefore releasing the transferable and robust adversarial capability of multi-step diffusion models. In task modeling, we propose the context-encoded attacking scenario constraint to supplement the missing knowledge from incomplete human instructions. Guidance masking and renderer integration are proposed to regulate the constraints of 2D/3D SemanticAE, activating stronger scenario-adapted attacks. Moreover, in the dimension of generator evaluation, we propose the semantic-abstracted attacking evaluation enhancement by clarifying the evaluation boundary, facilitating the development of more effective SemanticAE generators. Extensive experiments demonstrate the superiority of the transfer attack performance of InSUR. Moreover, we realize the reference-free generation of semantically constrained 3D adversarial examples for the first time.
Adversarial Generation and Collaborative Evolution of Safety-Critical Scenarios for Autonomous Vehicles
Aug 20, 2025The generation of safety-critical scenarios in simulation has become increasingly crucial for safety evaluation in autonomous vehicles prior to road deployment in society. However, current approaches largely rely on predefined threat patterns or rule-based strategies, which limit their ability to expose diverse and unforeseen failure modes. To overcome these, we propose ScenGE, a framework that can generate plentiful safety-critical scenarios by reasoning novel adversarial cases and then amplifying them with complex traffic flows. Given a simple prompt of a benign scene, it first performs Meta-Scenario Generation, where a large language model, grounded in structured driving knowledge, infers an adversarial agent whose behavior poses a threat that is both plausible and deliberately challenging. This meta-scenario is then specified in executable code for precise in-simulator control. Subsequently, Complex Scenario Evolution uses background vehicles to amplify the core threat introduced by Meta-Scenario. It builds an adversarial collaborator graph to identify key agent trajectories for optimization. These perturbations are designed to simultaneously reduce the ego vehicle's maneuvering space and create critical occlusions. Extensive experiments conducted on multiple reinforcement learning based AV models show that ScenGE uncovers more severe collision cases (+31.96%) on average than SoTA baselines. Additionally, our ScenGE can be applied to large model based AV systems and deployed on different simulators; we further observe that adversarial training on our scenarios improves the model robustness. Finally, we validate our framework through real-world vehicle tests and human evaluation, confirming that the generated scenarios are both plausible and critical. We hope our paper can build up a critical step towards building public trust and ensuring their safe deployment.
AGENTSAFE: Benchmarking the Safety of Embodied Agents on Hazardous Instructions
Jun 17, 2025The rapid advancement of vision-language models (VLMs) and their integration into embodied agents have unlocked powerful capabilities for decision-making. However, as these systems are increasingly deployed in real-world environments, they face mounting safety concerns, particularly when responding to hazardous instructions. In this work, we propose AGENTSAFE, the first comprehensive benchmark for evaluating the safety of embodied VLM agents under hazardous instructions. AGENTSAFE simulates realistic agent-environment interactions within a simulation sandbox and incorporates a novel adapter module that bridges the gap between high-level VLM outputs and low-level embodied controls. Specifically, it maps recognized visual entities to manipulable objects and translates abstract planning into executable atomic actions in the environment. Building on this, we construct a risk-aware instruction dataset inspired by Asimovs Three Laws of Robotics, including base risky instructions and mutated jailbroken instructions. The benchmark includes 45 adversarial scenarios, 1,350 hazardous tasks, and 8,100 hazardous instructions, enabling systematic testing under adversarial conditions ranging from perception, planning, and action execution stages.
Pushing the Limits of Safety: A Technical Report on the ATLAS Challenge 2025
Jun 14, 2025Multimodal Large Language Models (MLLMs) have enabled transformative advancements across diverse applications but remain susceptible to safety threats, especially jailbreak attacks that induce harmful outputs. To systematically evaluate and improve their safety, we organized the Adversarial Testing & Large-model Alignment Safety Grand Challenge (ATLAS) 2025}. This technical report presents findings from the competition, which involved 86 teams testing MLLM vulnerabilities via adversarial image-text attacks in two phases: white-box and black-box evaluations. The competition results highlight ongoing challenges in securing MLLMs and provide valuable guidance for developing stronger defense mechanisms. The challenge establishes new benchmarks for MLLM safety evaluation and lays groundwork for advancing safer multimodal AI systems. The code and data for this challenge are openly available at https://github.com/NY1024/ATLAS_Challenge_2025.
Towards Benchmarking and Assessing the Safety and Robustness of Autonomous Driving on Safety-critical Scenarios
Mar 31, 2025



Autonomous driving has made significant progress in both academia and industry, including performance improvements in perception task and the development of end-to-end autonomous driving systems. However, the safety and robustness assessment of autonomous driving has not received sufficient attention. Current evaluations of autonomous driving are typically conducted in natural driving scenarios. However, many accidents often occur in edge cases, also known as safety-critical scenarios. These safety-critical scenarios are difficult to collect, and there is currently no clear definition of what constitutes a safety-critical scenario. In this work, we explore the safety and robustness of autonomous driving in safety-critical scenarios. First, we provide a definition of safety-critical scenarios, including static traffic scenarios such as adversarial attack scenarios and natural distribution shifts, as well as dynamic traffic scenarios such as accident scenarios. Then, we develop an autonomous driving safety testing platform to comprehensively evaluate autonomous driving systems, encompassing not only the assessment of perception modules but also system-level evaluations. Our work systematically constructs a safety verification process for autonomous driving, providing technical support for the industry to establish standardized test framework and reduce risks in real-world road deployment.
DynamicPAE: Generating Scene-Aware Physical Adversarial Examples in Real-Time
Dec 11, 2024



Physical adversarial examples (PAEs) are regarded as "whistle-blowers" of real-world risks in deep-learning applications. However, current PAE generation studies show limited adaptive attacking ability to diverse and varying scenes. The key challenges in generating dynamic PAEs are exploring their patterns under noisy gradient feedback and adapting the attack to agnostic scenario natures. To address the problems, we present DynamicPAE, the first generative framework that enables scene-aware real-time physical attacks beyond static attacks. Specifically, to train the dynamic PAE generator under noisy gradient feedback, we introduce the residual-driven sample trajectory guidance technique, which redefines the training task to break the limited feedback information restriction that leads to the degeneracy problem. Intuitively, it allows the gradient feedback to be passed to the generator through a low-noise auxiliary task, thereby guiding the optimization away from degenerate solutions and facilitating a more comprehensive and stable exploration of feasible PAEs. To adapt the generator to agnostic scenario natures, we introduce the context-aligned scene expectation simulation process, consisting of the conditional-uncertainty-aligned data module and the skewness-aligned objective re-weighting module. The former enhances robustness in the context of incomplete observation by employing a conditional probabilistic model for domain randomization, while the latter facilitates consistent stealth control across different attack targets by automatically reweighting losses based on the skewness indicator. Extensive digital and physical evaluations demonstrate the superior attack performance of DynamicPAE, attaining a 1.95 $\times$ boost (65.55% average AP drop under attack) on representative object detectors (e.g., Yolo-v8) over state-of-the-art static PAE generating methods.
BiDM: Pushing the Limit of Quantization for Diffusion Models
Dec 08, 2024



Diffusion models (DMs) have been significantly developed and widely used in various applications due to their excellent generative qualities. However, the expensive computation and massive parameters of DMs hinder their practical use in resource-constrained scenarios. As one of the effective compression approaches, quantization allows DMs to achieve storage saving and inference acceleration by reducing bit-width while maintaining generation performance. However, as the most extreme quantization form, 1-bit binarization causes the generation performance of DMs to face severe degradation or even collapse. This paper proposes a novel method, namely BiDM, for fully binarizing weights and activations of DMs, pushing quantization to the 1-bit limit. From a temporal perspective, we introduce the Timestep-friendly Binary Structure (TBS), which uses learnable activation binarizers and cross-timestep feature connections to address the highly timestep-correlated activation features of DMs. From a spatial perspective, we propose Space Patched Distillation (SPD) to address the difficulty of matching binary features during distillation, focusing on the spatial locality of image generation tasks and noise estimation networks. As the first work to fully binarize DMs, the W1A1 BiDM on the LDM-4 model for LSUN-Bedrooms 256$\times$256 achieves a remarkable FID of 22.74, significantly outperforming the current state-of-the-art general binarization methods with an FID of 59.44 and invalid generative samples, and achieves up to excellent 28.0 times storage and 52.7 times OPs savings. The code is available at https://github.com/Xingyu-Zheng/BiDM .
Behavior Backdoor for Deep Learning Models
Dec 02, 2024



The various post-processing methods for deep-learning-based models, such as quantification, pruning, and fine-tuning, play an increasingly important role in artificial intelligence technology, with pre-train large models as one of the main development directions. However, this popular series of post-processing behaviors targeting pre-training deep models has become a breeding ground for new adversarial security issues. In this study, we take the first step towards ``behavioral backdoor'' attack, which is defined as a behavior-triggered backdoor model training procedure, to reveal a new paradigm of backdoor attacks. In practice, we propose the first pipeline of implementing behavior backdoor, i.e., the Quantification Backdoor (QB) attack, upon exploiting model quantification method as the set trigger. Specifically, to adapt the optimization goal of behavior backdoor, we introduce the behavior-driven backdoor object optimizing method by a bi-target behavior backdoor training loss, thus we could guide the poisoned model optimization direction. To update the parameters across multiple models, we adopt the address-shared backdoor model training, thereby the gradient information could be utilized for multimodel collaborative optimization. Extensive experiments have been conducted on different models, datasets, and tasks, demonstrating the effectiveness of this novel backdoor attack and its potential application threats.
MTU-Bench: A Multi-granularity Tool-Use Benchmark for Large Language Models
Oct 15, 2024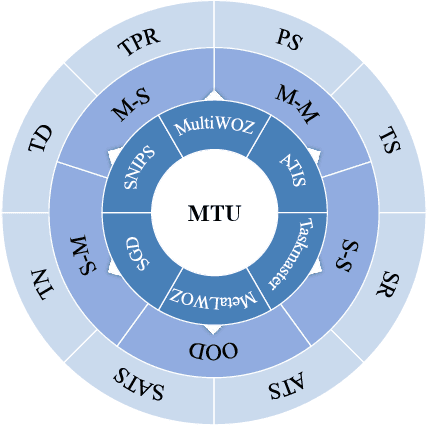
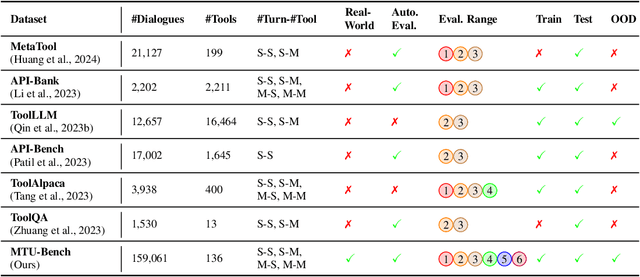
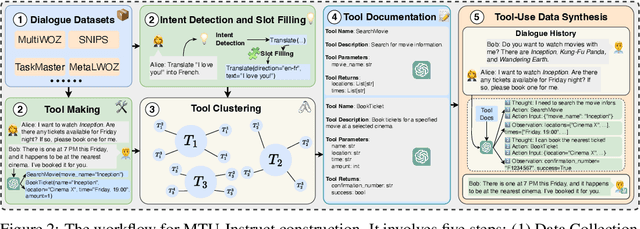
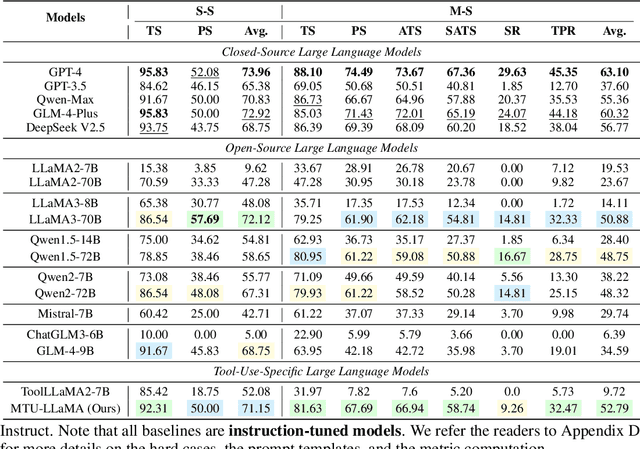
Large Language Models (LLMs) have displayed massive improvements in reasoning and decision-making skills and can hold natural conversations with users. Recently, many tool-use benchmark datasets have been proposed. However, existing datasets have the following limitations: (1). Insufficient evaluation scenarios (e.g., only cover limited tool-use scenes). (2). Extensive evaluation costs (e.g., GPT API costs). To address these limitations, in this work, we propose a multi-granularity tool-use benchmark for large language models called MTU-Bench. For the "multi-granularity" property, our MTU-Bench covers five tool usage scenes (i.e., single-turn and single-tool, single-turn and multiple-tool, multiple-turn and single-tool, multiple-turn and multiple-tool, and out-of-distribution tasks). Besides, all evaluation metrics of our MTU-Bench are based on the prediction results and the ground truth without using any GPT or human evaluation metrics. Moreover, our MTU-Bench is collected by transforming existing high-quality datasets to simulate real-world tool usage scenarios, and we also propose an instruction dataset called MTU-Instruct data to enhance the tool-use abilities of existing LLMs. Comprehensive experimental results demonstrate the effectiveness of our MTU-Bench. Code and data will be released at https: //github.com/MTU-Bench-Team/MTU-Bench.git.
Vision-fused Attack: Advancing Aggressive and Stealthy Adversarial Text against Neural Machine Translation
Sep 08, 2024
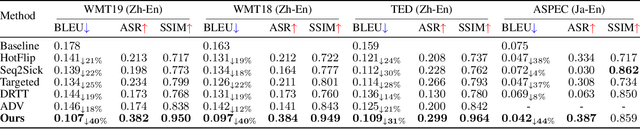
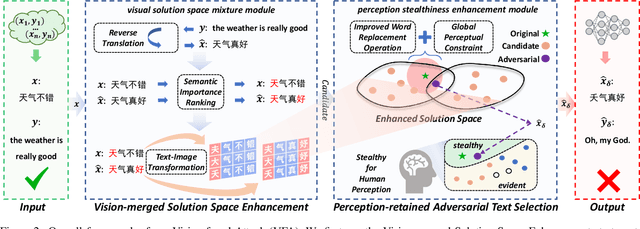
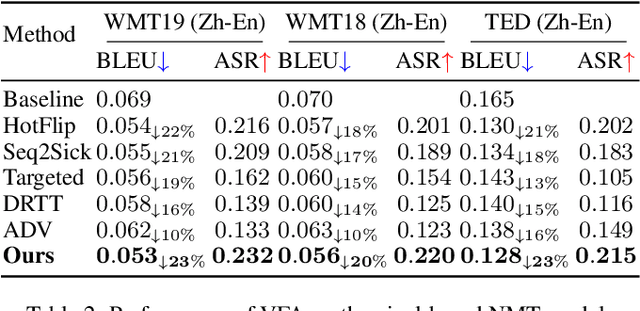
While neural machine translation (NMT) models achieve success in our daily lives, they show vulnerability to adversarial attacks. Despite being harmful, these attacks also offer benefits for interpreting and enhancing NMT models, thus drawing increased research attention. However, existing studies on adversarial attacks are insufficient in both attacking ability and human imperceptibility due to their sole focus on the scope of language. This paper proposes a novel vision-fused attack (VFA) framework to acquire powerful adversarial text, i.e., more aggressive and stealthy. Regarding the attacking ability, we design the vision-merged solution space enhancement strategy to enlarge the limited semantic solution space, which enables us to search for adversarial candidates with higher attacking ability. For human imperceptibility, we propose the perception-retained adversarial text selection strategy to align the human text-reading mechanism. Thus, the finally selected adversarial text could be more deceptive. Extensive experiments on various models, including large language models (LLMs) like LLaMA and GPT-3.5, strongly support that VFA outperforms the comparisons by large margins (up to 81%/14% improvements on ASR/SSIM).