 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reprogramming Distillation for Medical Foundation Models
May 06, 2026Medical foundation models pre-trained on large-scale datasets have shown powerful versatile performance. However, when adapting medical foundation models for specific medical scenarios, it remains the inevitable challenge due to the gap induced by the discrepancy between pre-training and downstream tasks, the real-world computation, and speed constraints. Relevant techniques that probably handle this challenge more or less suffer from some intrinsic limitations. For example, knowledge distillation (KD) assumes that teacher and student models share the same task, training strategy, and model structure family, while prevalent parameter-efficient fine-tuning (PEFT) fails to achieve personalized and lightweight deployment. Even the combination of PEFT and KD still struggles to resolve model structures and training strategies inconsistencies between teacher and student models, leading to inefficient knowledge transfer. In this study, we propose a novel framework called Deep Reprogramming Distillation (DRD) to combat the general adaptation challenge. Specifically, DRD introduces the novel reprogramming module that on the one side overcomes the domain and task discrepancy between pretraining and downstream scenarios, and on the other side builds the student-friendly efficient distillation from foundation models to lightweight downstream models. Furthermore, to mitigate variability under different training conditions, we design a centered kernel alignment (CKA) distillation method to promote robust knowledge transfer. Empirical results show that DRD surpasses previous PEFT and KD methods across 18 medical downstream tasks under different foundation models, covering various scenarios including 2D/3D classification and 2D/3D segmentation.
Eliciting Medical Reasoning with Knowledge-enhanced Data Synthesis: A Semi-Supervised Reinforcement Learning Approach
Apr 13, 2026While large language models hold promise for complex medical applications, their development is hindered by the scarcity of high-quality reasoning data. To address this issue, existing approaches typically distill chain-of-thought reasoning traces from large proprietary models via supervised fine-tuning, then conduct reinforcement learning (RL). These methods exhibit limited improvement on underrepresented domains like rare diseases while incurring substantial costs from generating complex reasoning chains. To efficiently enhance medical reasoning, we propose MedSSR, a Medical Knowledge-enhanced data Synthesis and Semi-supervised Reinforcement learning framework. Our framework first employs rare disease knowledge to synthesize distribution-controllable reasoning questions. We then utilize the policy model itself to generate high-quality pseudo-labels. This enables a two-stage, intrinsic-to-extrinsic training paradigm: self-supervised RL on the pseudo-labeled synthetic data, followed by supervised RL on the human-annotated real data. MedSSR scales model training efficiently without relying on costly trace distillation. Extensive experiments on Qwen and Llama demonstrate that our method outperforms existing methods across ten medical benchmarks, achieving up to +5.93% gain on rare-disease tasks. Our code is available at https://github.com/tdlhl/MedSSR.
Predicting Neuromodulation Outcome for Parkinson's Disease with Generative Virtual Brain Model
Mar 31, 2026Parkinson's disease (PD) affects over ten million people worldwide. Although temporal interference (TI) and deep brain stimulation (DBS) are promising therapies, inter-individual variability limits empirical treatment selection, increasing non-negligible surgical risk and cost. Previous explorations either resort to limited statistical biomarkers that are insufficient to characterize variability, or employ AI-driven methods which is prone to overfitting and opacity. We bridge this gap with a pretraining-finetuning framework to predict outcomes directly from resting-state fMRI. Critically, a generative virtual brain foundation model, pretrained on a collective dataset (2707 subjects, 5621 sessions) to capture universal disorder patterns, was finetuned on PD cohorts receiving TI (n=51) or DBS (n=55) to yield individualized virtual brains with high fidelity to empirical functional connectivity (r=0.935). By constructing counterfactual estimations between pathological and healthy neural states within these personalized models, we predicted clinical responses (TI: AUPR=0.853; DBS: AUPR=0.915), substantially outperforming baselines. External and prospective validations (n=14, n=11) highlight the feasibility of clinical translation. Moreover, our framework provides state-dependent regional patterns linked to response, offering hypothesis-generating mechanistic insights.
Semantic Routing: Exploring Multi-Layer LLM Feature Weighting for Diffusion Transformers
Feb 03, 2026Recent DiT-based text-to-image models increasingly adopt LLMs as text encoders, yet text conditioning remains largely static and often utilizes only a single LLM layer, despite pronounced semantic hierarchy across LLM layers and non-stationary denoising dynamics over both diffusion time and network depth. To better match the dynamic process of DiT generation and thereby enhance the diffusion model's generative capability, we introduce a unified normalized convex fusion framework equipped with lightweight gates to systematically organize multi-layer LLM hidden states via time-wise, depth-wise, and joint fusion. Experiments establish Depth-wise Semantic Routing as the superior conditioning strategy, consistently improving text-image alignment and compositional generation (e.g., +9.97 on the GenAI-Bench Counting task). Conversely, we find that purely time-wise fusion can paradoxically degrade visual generation fidelity. We attribute this to a train-inference trajectory mismatch: under classifier-free guidance, nominal timesteps fail to track the effective SNR, causing semantically mistimed feature injection during inference. Overall, our results position depth-wise routing as a strong and effective baseline and highlight the critical need for trajectory-aware signals to enable robust time-dependent conditioning.
Learning the Mechanism of Catastrophic Forgetting: A Perspective from Gradient Similarity
Jan 29, 2026Catastrophic forgetting during knowledge injection severely undermines the continual learning capability of large language models (LLMs). Although existing methods attempt to mitigate this issue, they often lack a foundational theoretical explanation. We establish a gradient-based theoretical framework to explain catastrophic forgetting. We first prove that strongly negative gradient similarity is a fundamental cause of forgetting. We then use gradient similarity to identify two types of neurons: conflicting neurons that induce forgetting and account for 50%-75% of neurons, and collaborative neurons that mitigate forgetting and account for 25%-50%. Based on this analysis, we propose a knowledge injection method, Collaborative Neural Learning (CNL). By freezing conflicting neurons and updating only collaborative neurons, CNL theoretically eliminates catastrophic forgetting under an infinitesimal learning rate eta and an exactly known mastered set. Experiments on five LLMs, four datasets, and four optimizers show that CNL achieves zero forgetting in in-set settings and reduces forgetting by 59.1%-81.7% in out-of-set settings.
Discrete Solution Operator Learning for Geometry-Dependent PDEs
Jan 15, 2026Neural operator learning accelerates PDE solution by approximating operators as mappings between continuous function spaces. Yet in many engineering settings, varying geometry induces discrete structural changes, including topological changes, abrupt changes in boundary conditions or boundary types, and changes in the computational domain, which break the smooth-variation premise. Here we introduce Discrete Solution Operator Learning (DiSOL), a complementary paradigm that learns discrete solution procedures rather than continuous function-space operators. DiSOL factorizes the solver into learnable stages that mirror classical discretizations: local contribution encoding, multiscale assembly, and implicit solution reconstruction on an embedded grid, thereby preserving procedure-level consistency while adapting to geometry-dependent discrete structures. Across geometry-dependent Poisson, advection-diffusion, linear elasticity, as well as spatiotemporal heat conduction problems, DiSOL produces stable and accurate predictions under both in-distribution and strongly out-of-distribution geometries, including discontinuous boundaries and topological changes. These results highlight the need for procedural operator representations in geometry-dominated problems and position discrete solution operator learning as a distinct, complementary direction in scientific machine learning.
Exploring Semantic-constrained Adversarial Example with Instruction Uncertainty Reduction
Oct 27, 2025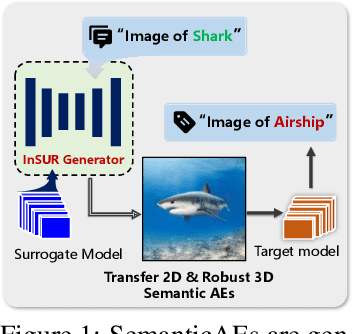
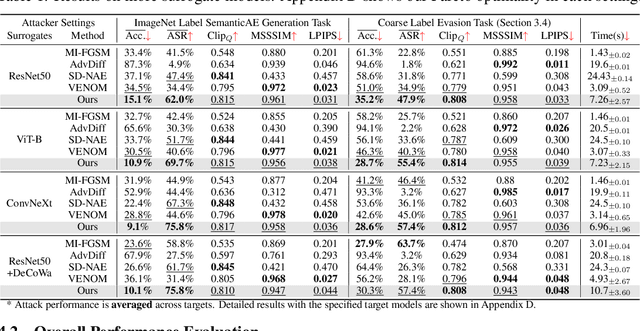
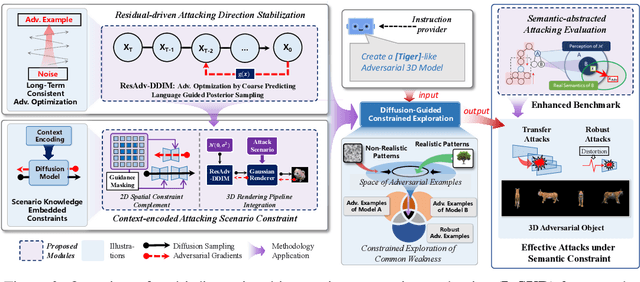

Recently, semantically constrained adversarial examples (SemanticAE), which are directly generated from natural language instructions, have become a promising avenue for future research due to their flexible attacking forms. To generate SemanticAEs, current methods fall short of satisfactory attacking ability as the key underlying factors of semantic uncertainty in human instructions, such as referring diversity, descriptive incompleteness, and boundary ambiguity, have not been fully investigated. To tackle the issues, this paper develops a multi-dimensional instruction uncertainty reduction (InSUR) framework to generate more satisfactory SemanticAE, i.e., transferable, adaptive, and effective. Specifically, in the dimension of the sampling method, we propose the residual-driven attacking direction stabilization to alleviate the unstable adversarial optimization caused by the diversity of language references. By coarsely predicting the language-guided sampling process, the optimization process will be stabilized by the designed ResAdv-DDIM sampler, therefore releasing the transferable and robust adversarial capability of multi-step diffusion models. In task modeling, we propose the context-encoded attacking scenario constraint to supplement the missing knowledge from incomplete human instructions. Guidance masking and renderer integration are proposed to regulate the constraints of 2D/3D SemanticAE, activating stronger scenario-adapted attacks. Moreover, in the dimension of generator evaluation, we propose the semantic-abstracted attacking evaluation enhancement by clarifying the evaluation boundary, facilitating the development of more effective SemanticAE generators. Extensive experiments demonstrate the superiority of the transfer attack performance of InSUR. Moreover, we realize the reference-free generation of semantically constrained 3D adversarial examples for the first time.
LiRA: Linguistic Robust Anchoring for Cross-lingual Large Language Models
Oct 16, 2025As large language models (LLMs) rapidly advance, performance on high-resource languages (e.g., English, Chinese) is nearing saturation, yet remains substantially lower for low-resource languages (e.g., Urdu, Thai) due to limited training data, machine-translation noise, and unstable cross-lingual alignment. We introduce LiRA (Linguistic Robust Anchoring for Large Language Models), a training framework that robustly improves cross-lingual representations under low-resource conditions while jointly strengthening retrieval and reasoning. LiRA comprises two modules: (i) Arca (Anchored Representation Composition Architecture), which anchors low-resource languages to an English semantic space via anchor-based alignment and multi-agent collaborative encoding, preserving geometric stability in a shared embedding space; and (ii) LaSR (Language-coupled Semantic Reasoner), which adds a language-aware lightweight reasoning head with consistency regularization on top of Arca's multilingual representations, unifying the training objective to enhance cross-lingual understanding, retrieval, and reasoning robustness. We further construct and release a multilingual product retrieval dataset covering five Southeast Asian and two South Asian languages. Experiments across low-resource benchmarks (cross-lingual retrieval, semantic similarity, and reasoning) show consistent gains and robustness under few-shot and noise-amplified settings; ablations validate the contribution of both Arca and LaSR. Code will be released on GitHub and the dataset on Hugging Face.
Physics-informed Neural Network Predictive Control for Quadruped Locomotion
Mar 10, 2025This study introduces a unified control framework that addresses the challenge of precise quadruped locomotion with unknown payloads, named as online payload identification-based physics-informed neural network predictive control (OPI-PINNPC). By integrating online payload identification with physics-informed neural networks (PINNs), our approach embeds identified mass parameters directly into the neural network's loss function, ensuring physical consistency while adapting to changing load conditions. The physics-constrained neural representation serves as an efficient surrogate model within our nonlinear model predictive controller, enabling real-time optimization despite the complex dynamics of legged locomotion. Experimental validation on our quadruped robot platform demonstrates 35% improvement in position and orientation tracking accuracy across diverse payload conditions (25-100 kg), with substantially faster convergence compared to previous adaptive control methods. Our framework provides a adaptive solution for maintaining locomotion performance under variable payload conditions without sacrificing computational efficiency.
Finite-PINN: A Physics-Informed Neural Network Architecture for Solving Solid Mechanics Problems with General Geometries
Dec 12, 2024



PINN models have demonstrated impressive capabilities in addressing fluid PDE problems, and their potential in solid mechanics is beginning to emerge. This study identifies two key challenges when using PINN to solve general solid mechanics problems. These challenges become evident when comparing the limitations of PINN with the well-established numerical methods commonly used in solid mechanics, such as the finite element method (FEM). Specifically: a) PINN models generate solutions over an infinite domain, which conflicts with the finite boundaries typical of most solid structures; and b) the solution space utilised by PINN is Euclidean, which is inadequate for addressing the complex geometries often present in solid structures. This work proposes a PINN architecture used for general solid mechanics problems, termed the Finite-PINN model. The proposed model aims to effectively address these two challenges while preserving as much of the original implementation of PINN as possible. The unique architecture of the Finite-PINN model addresses these challenges by separating the approximation of stress and displacement fields, and by transforming the solution space from the traditional Euclidean space to a Euclidean-topological joint space. Several case studies presented in this paper demonstrate that the Finite-PINN model provides satisfactory results for a variety of problem types, including both forward and inverse problems, in both 2D and 3D contexts. The developed Finite-PINN model offers a promising tool for addressing general solid mechanics problems, particularly those not yet well-explored in current research.