 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reprogramming Distillation for Medical Foundation Models
May 06, 2026Medical foundation models pre-trained on large-scale datasets have shown powerful versatile performance. However, when adapting medical foundation models for specific medical scenarios, it remains the inevitable challenge due to the gap induced by the discrepancy between pre-training and downstream tasks, the real-world computation, and speed constraints. Relevant techniques that probably handle this challenge more or less suffer from some intrinsic limitations. For example, knowledge distillation (KD) assumes that teacher and student models share the same task, training strategy, and model structure family, while prevalent parameter-efficient fine-tuning (PEFT) fails to achieve personalized and lightweight deployment. Even the combination of PEFT and KD still struggles to resolve model structures and training strategies inconsistencies between teacher and student models, leading to inefficient knowledge transfer. In this study, we propose a novel framework called Deep Reprogramming Distillation (DRD) to combat the general adaptation challenge. Specifically, DRD introduces the novel reprogramming module that on the one side overcomes the domain and task discrepancy between pretraining and downstream scenarios, and on the other side builds the student-friendly efficient distillation from foundation models to lightweight downstream models. Furthermore, to mitigate variability under different training conditions, we design a centered kernel alignment (CKA) distillation method to promote robust knowledge transfer. Empirical results show that DRD surpasses previous PEFT and KD methods across 18 medical downstream tasks under different foundation models, covering various scenarios including 2D/3D classification and 2D/3D segmentation.
Predicting Neuromodulation Outcome for Parkinson's Disease with Generative Virtual Brain Model
Mar 31, 2026Parkinson's disease (PD) affects over ten million people worldwide. Although temporal interference (TI) and deep brain stimulation (DBS) are promising therapies, inter-individual variability limits empirical treatment selection, increasing non-negligible surgical risk and cost. Previous explorations either resort to limited statistical biomarkers that are insufficient to characterize variability, or employ AI-driven methods which is prone to overfitting and opacity. We bridge this gap with a pretraining-finetuning framework to predict outcomes directly from resting-state fMRI. Critically, a generative virtual brain foundation model, pretrained on a collective dataset (2707 subjects, 5621 sessions) to capture universal disorder patterns, was finetuned on PD cohorts receiving TI (n=51) or DBS (n=55) to yield individualized virtual brains with high fidelity to empirical functional connectivity (r=0.935). By constructing counterfactual estimations between pathological and healthy neural states within these personalized models, we predicted clinical responses (TI: AUPR=0.853; DBS: AUPR=0.915), substantially outperforming baselines. External and prospective validations (n=14, n=11) highlight the feasibility of clinical translation. Moreover, our framework provides state-dependent regional patterns linked to response, offering hypothesis-generating mechanistic insights.
Combatting Dimensional Collapse in LLM Pre-Training Data via Diversified File Selection
Apr 29, 2025Selecting high-quality pre-training data for large language models (LLMs) is crucial for enhancing their overall performance under limited computation budget, improving both training and sample efficiency. Recent advancements in file selection primarily rely on using an existing or trained proxy model to assess the similarity of samples to a target domain, such as high quality sources BookCorpus and Wikipedia. However, upon revisiting these methods, the domain-similarity selection criteria demonstrates a diversity dilemma, i.e.dimensional collapse in the feature space, improving performance on the domain-related tasks but causing severe degradation on generic performance. To prevent collapse and enhance diversity, we propose a DiverSified File selection algorithm (DiSF), which selects the most decorrelated text files in the feature space. We approach this with a classical greedy algorithm to achieve more uniform eigenvalues in the feature covariance matrix of the selected texts, analyzing its approximation to the optimal solution under a formulation of $\gamma$-weakly submodular optimization problem. Empirically, we establish a benchmark and conduct extensive experiments on the TinyLlama architecture with models from 120M to 1.1B parameters. Evaluating across nine tasks from the Harness framework, DiSF demonstrates a significant improvement on overall performance. Specifically, DiSF saves 98.5% of 590M training files in SlimPajama, outperforming the full-data pre-training within a 50B training budget, and achieving about 1.5x training efficiency and 5x data efficiency.
LoRKD: Low-Rank Knowledge Decomposition for Medical Foundation Models
Sep 29, 2024



The widespread adoption of large-scale pre-training techniques has significantly advanced the development of medical foundation models, enabling them to serve as versatile tools across a broad range of medical tasks. However, despite their strong generalization capabilities, medical foundation models pre-trained on large-scale datasets tend to suffer from domain gaps between heterogeneous data, leading to suboptimal performance on specific tasks compared to specialist models, as evidenced by previous studies. In this paper, we explore a new perspective called "Knowledge Decomposition" to improve the performance on specific medical tasks, which deconstructs the foundation model into multiple lightweight expert models, each dedicated to a particular anatomical region, with the aim of enhancing specialization and simultaneously reducing resource consumption. To accomplish the above objective, we propose a novel framework named Low-Rank Knowledge Decomposition (LoRKD), which explicitly separates gradients from different tasks by incorporating low-rank expert modules and efficient knowledge separation convolution. The low-rank expert modules resolve gradient conflicts between heterogeneous data from different anatomical regions, providing strong specialization at lower costs. The efficient knowledge separation convolution significantly improves algorithm efficiency by achieving knowledge separation within a single forward propagation. Extensive experimental results on segmentation and classification tasks demonstrate that our decomposed models not only achieve state-of-the-art performance but also exhibit superior transferability on downstream tasks, even surpassing the original foundation models in task-specific evaluations. The code is available at here.
Reprogramming Distillation for Medical Foundation Models
Jul 09, 2024Medical foundation models pre-trained on large-scale datasets have demonstrated powerful versatile capabilities for various tasks. However, due to the gap between pre-training tasks (or modalities) and downstream tasks (or modalities), the real-world computation and speed constraints, it might not be straightforward to apply medical foundation models in the downstream scenarios. Previous methods, such as parameter efficient fine-tuning (PEFT) methods and knowledge distillation (KD) methods, are unable to simultaneously address the task (or modality) inconsistency and achieve personalized lightweight deployment under diverse real-world demands. To address the above issues, we propose a novel framework called Reprogramming Distillation (RD). On one hand, RD reprograms the original feature space of the foundation model so that it is more relevant to downstream scenarios, aligning tasks and modalities. On the other hand, through a co-training mechanism and a shared classifier, connections are established between the reprogrammed knowledge and the knowledge of student models, ensuring that the reprogrammed feature space can be smoothly mimic by the student model of different structures. Further, to reduce the randomness under different training conditions, we design a Centered Kernel Alignment (CKA) distillation to promote robust knowledge transfer. Empirically, we show that on extensive datasets, RD consistently achieve superior performance compared with previous PEFT and KD methods.
Exploring Training on Heterogeneous Data with Mixture of Low-rank Adapters
Jun 14, 2024Training a unified model to take multiple targets into account is a trend towards artificial general intelligence. However, how to efficiently mitigate the training conflicts among heterogeneous data collected from different domains or tasks remains under-explored. In this study, we explore to leverage Mixture of Low-rank Adapters (MoLA) to mitigate conflicts in heterogeneous data training, which requires to jointly train the multiple low-rank adapters and their shared backbone. Specifically, we introduce two variants of MoLA, namely, MoLA-Grad and MoLA-Router, to respectively handle the target-aware and target-agnostic scenarios during inference. The former uses task identifiers to assign personalized low-rank adapters to each task, disentangling task-specific knowledge towards their adapters, thereby mitigating heterogeneity conflicts. The latter uses a novel Task-wise Decorrelation (TwD) loss to intervene the router to learn oriented weight combinations of adapters to homogeneous tasks, achieving similar effects. We conduct comprehensive experiments to verify the superiority of MoLA over previous state-of-the-art methods and present in-depth analysis on its working mechanism. Source code is available at: https://github.com/MediaBrain-SJTU/MoLA
Low-Rank Knowledge Decomposition for Medical Foundation Models
Apr 26, 2024
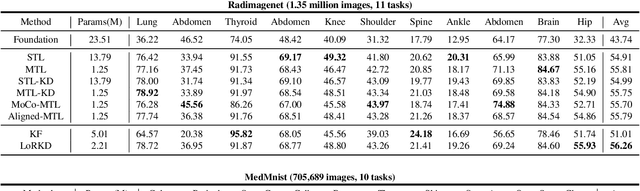
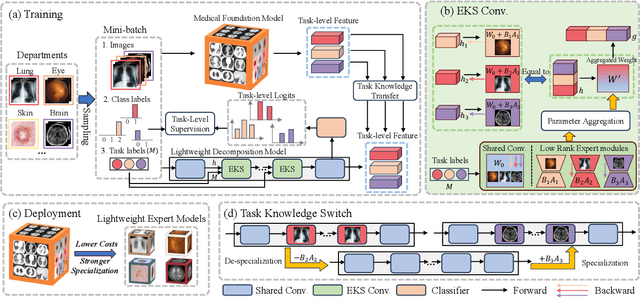
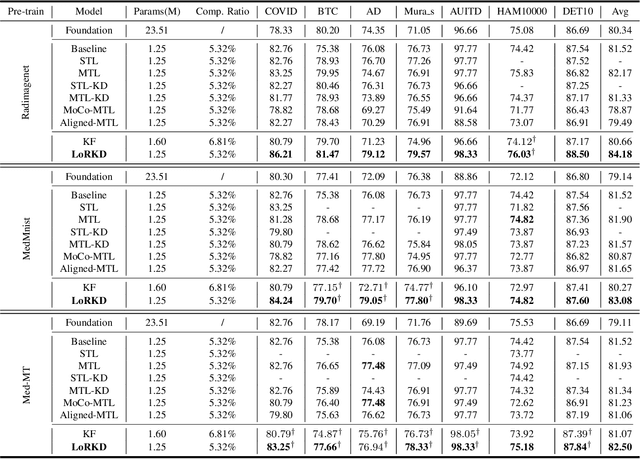
The popularity of large-scale pre-training has promoted the development of medical foundation models. However, some studies have shown that although foundation models exhibit strong general feature extraction capabilities, their performance on specific tasks is still inferior to task-specific methods. In this paper, we explore a new perspective called ``Knowledge Decomposition'' to improve the performance on specific medical tasks, which deconstruct the foundation model into multiple lightweight expert models, each dedicated to a particular task, with the goal of improving specialization while concurrently mitigating resource expenditure. To accomplish the above objective, we design a novel framework named Low-Rank Knowledge Decomposition (LoRKD), which explicitly separates graidents by incorporating low-rank expert modules and the efficient knowledge separation convolution. Extensive experimental results demonstrate that the decomposed models perform well in terms of performance and transferability, even surpassing the original foundation models.
Fraud Detection with Binding Global and Local Relational Interaction
Feb 27, 2024Graph Neural Network has been proved to be effective for fraud detection for its capability to encode node interaction and aggregate features in a holistic view. Recently, Transformer network with great sequence encoding ability, has also outperformed other GNN-based methods in literatures. However, both GNN-based and Transformer-based networks only encode one perspective of the whole graph, while GNN encodes global features and Transformer network encodes local ones. Furthermore, previous works ignored encoding global interaction features of the heterogeneous graph with separate networks, thus leading to suboptimal performance. In this work, we present a novel framework called Relation-Aware GNN with transFormer (RAGFormer) which simultaneously embeds local and global features into a target node. The simple yet effective network applies a modified GAGA module where each transformer layer is followed by a cross-relation aggregation layer, to encode local embeddings and node interactions across different relations. Apart from the Transformer-based network, we further introduce a Relation-Aware GNN module to learn global embeddings, which is later merged into the local embeddings by an attention fusion module and a skip connection. Extensive experiments on two popular public datasets and an industrial dataset demonstrate that RAGFormer achieves the state-of-the-art performance. Substantial analysis experiments validate the effectiveness of each submodule of RAGFormer and its high efficiency in utilizing small-scale data and low hyper-parameter sensitivity.