 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDINORANKCLIP: DINOv3 Distillation and Injection for Vision-Language Pretraining with High-Order Ranking Consistency
May 07, 2026Contrastive language-image pretraining (CLIP) suffers from two structural weaknesses: the symmetric InfoNCE loss discards the relative ordering among unmatched in-batch pairs, and global pooling collapses the visual representation into a semantic bottleneck that is poorly sensitive to fine-grained local structure. RANKCLIP partially addresses the first issue with a list-wise Plackett-Luce ranking-consistency loss, but its model is strictly first-order and inherits the second weakness untouched. We propose DINORANKCLIP, a pretraining framework that addresses both jointly. Our principal contribution is injecting a frozen DINOv3 teacher into the contrastive trunk through a dual-branch lightweight student and a multi-scale fusion module with channel-spatial attention, a self-attention refiner, and a conflict-aware gate that preserves the cross-modal alignment up to first order. Complementarily, we introduce a high-order Plackett-Luce ranking model in which the per-position utility is augmented with attention-parameterised pairwise and tuple-wise transition terms; the family contains CLIP and RANKCLIP as nested zero-order and first-order special cases, and the optimal order on every benchmark is $R^*=3$. The full empirical study -- order sweep, Fine-grained Probe on five datasets, four-node Modality-Gap analysis, six-variant Fusion ablation -- fits in 72 hours on a single eight-GPU H100 node and trains entirely on Conceptual Captions 3M. DINORANKCLIP consistently outperforms CLIP, CyCLIP, ALIP, and RANKCLIP under matched compute, with the largest relative gains on the fine-grained and out-of-distribution evaluations that most directly stress local structural reasoning.
Eliciting Medical Reasoning with Knowledge-enhanced Data Synthesis: A Semi-Supervised Reinforcement Learning Approach
Apr 13, 2026While large language models hold promise for complex medical applications, their development is hindered by the scarcity of high-quality reasoning data. To address this issue, existing approaches typically distill chain-of-thought reasoning traces from large proprietary models via supervised fine-tuning, then conduct reinforcement learning (RL). These methods exhibit limited improvement on underrepresented domains like rare diseases while incurring substantial costs from generating complex reasoning chains. To efficiently enhance medical reasoning, we propose MedSSR, a Medical Knowledge-enhanced data Synthesis and Semi-supervised Reinforcement learning framework. Our framework first employs rare disease knowledge to synthesize distribution-controllable reasoning questions. We then utilize the policy model itself to generate high-quality pseudo-labels. This enables a two-stage, intrinsic-to-extrinsic training paradigm: self-supervised RL on the pseudo-labeled synthetic data, followed by supervised RL on the human-annotated real data. MedSSR scales model training efficiently without relying on costly trace distillation. Extensive experiments on Qwen and Llama demonstrate that our method outperforms existing methods across ten medical benchmarks, achieving up to +5.93% gain on rare-disease tasks. Our code is available at https://github.com/tdlhl/MedSSR.
Miner:Mining Intrinsic Mastery for Data-Efficient RL in Large Reasoning Models
Jan 08, 2026Current critic-free RL methods for large reasoning models suffer from severe inefficiency when training on positive homogeneous prompts (where all rollouts are correct), resulting in waste of rollouts due to zero advantage estimates. We introduce a radically simple yet powerful solution to \uline{M}ine \uline{in}trinsic mast\uline{er}y (Miner), that repurposes the policy's intrinsic uncertainty as a self-supervised reward signal, with no external supervision, auxiliary models, or additional inference cost. Our method pioneers two key innovations: (1) a token-level focal credit assignment mechanism that dynamically amplifies gradients on critical uncertain tokens while suppressing overconfident ones, and (2) adaptive advantage calibration to seamlessly integrate intrinsic and verifiable rewards. Evaluated across six reasoning benchmarks on Qwen3-4B and Qwen3-8B base models, Miner achieves state-of-the-art performance among the other four algorithms, yielding up to \textbf{4.58} absolute gains in Pass@1 and \textbf{6.66} gains in Pass@K compared to GRPO. Comparison with other methods targeted at exploration enhancement further discloses the superiority of the two newly proposed innovations. This demonstrates that latent uncertainty exploitation is both necessary and sufficient for efficient and scalable RL training of reasoning models.
MedS$^3$: Towards Medical Small Language Models with Self-Evolved Slow Thinking
Jan 21, 2025



Medical language models (MLMs) have become pivotal in advancing medical natural language processing. However, prior models that rely on pre-training or supervised fine-tuning often exhibit low data efficiency and limited practicality in real-world clinical applications. While OpenAIs O1 highlights test-time scaling in mathematics, attempts to replicate this approach in medicine typically distill responses from GPT-series models to open-source models, focusing primarily on multiple-choice tasks. This strategy, though straightforward, neglects critical concerns like data privacy and realistic deployment in clinical settings. In this work, we present a deployable, small-scale medical language model, \mone, designed for long-chain reasoning in clinical tasks using a self-evolution paradigm. Starting with a seed dataset of around 8,000 instances spanning five domains and 16 datasets, we prompt a base policy model to perform Monte Carlo Tree Search (MCTS) to construct verifiable reasoning chains. Each reasoning step is assigned an evolution rollout value, allowing verified trajectories to train the policy model and the reward model. During inference, the policy model generates multiple responses, and the reward model selects the one with the highest reward score. Experiments on eleven evaluation datasets demonstrate that \mone outperforms prior open-source models by 2 points, with the addition of the reward model further boosting performance ($\sim$13 points), surpassing GPT-4o-mini. Code and data are available at \url{https://github.com/pixas/MedSSS}.
Towards Omni-RAG: Comprehensive Retrieval-Augmented Generation for Large Language Models in Medical Applications
Jan 05, 2025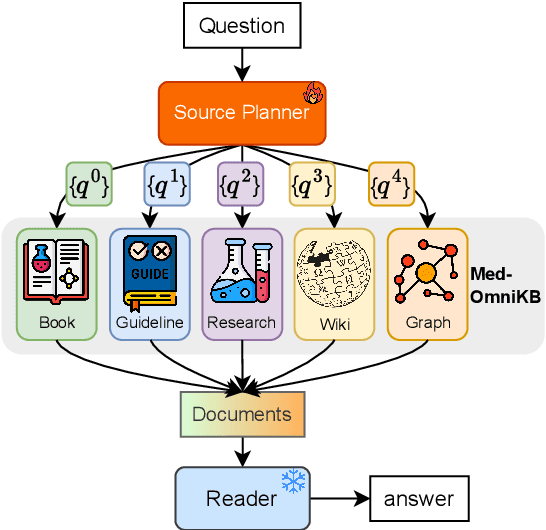
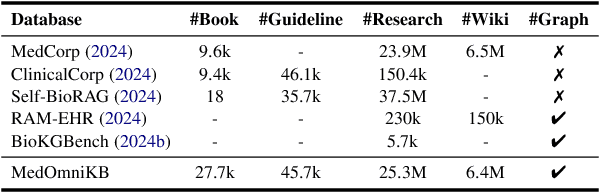
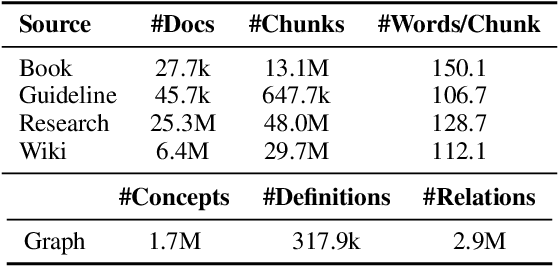
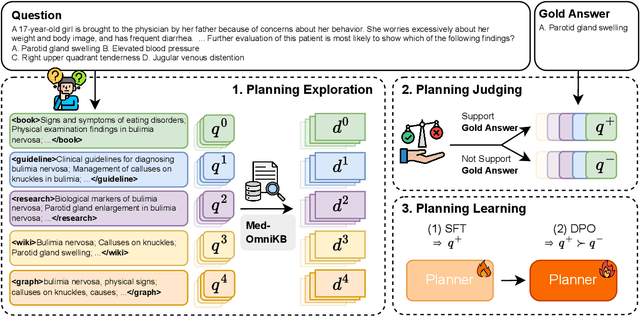
Large language models (LLMs) hold promise for addressing healthcare challenges but often generate hallucinations due to limited integration of medical knowledge. Incorporating external medical knowledge is therefore critical, especially considering the breadth and complexity of medical content, which necessitates effective multi-source knowledge acquisition. We address this challenge by framing it as a source planning problem, where the task is to formulate context-appropriate queries tailored to the attributes of diverse knowledge sources. Existing approaches either overlook source planning or fail to achieve it effectively due to misalignment between the model's expectation of the sources and their actual content. To bridge this gap, we present MedOmniKB, a comprehensive repository comprising multigenre and multi-structured medical knowledge sources. Leveraging these sources, we propose the Source Planning Optimisation (SPO) method, which enhances multi-source utilisation through explicit planning optimisation. Our approach involves enabling an expert model to explore and evaluate potential plans while training a smaller model to learn source alignment using positive and negative planning samples. Experimental results demonstrate that our method substantially improves multi-source planning performance, enabling the optimised small model to achieve state-of-the-art results in leveraging diverse medical knowledge sources.
ReflecTool: Towards Reflection-Aware Tool-Augmented Clinical Agents
Oct 23, 2024Large Language Models (LLMs) have shown promising potential in the medical domain, assisting with tasks like clinical note generation and patient communication. However, current LLMs are limited to text-based communication, hindering their ability to interact with diverse forms of information in clinical environments. Despite clinical agents succeeding in diverse signal interaction, they are oriented to a single clinical scenario and hence fail for broader applications. To evaluate clinical agents holistically, we propose ClinicalAgent Bench~(CAB), a comprehensive medical agent benchmark consisting of 18 tasks across five key realistic clinical dimensions. Building on this, we introduce ReflecTool, a novel framework that excels at utilizing domain-specific tools within two stages. The first optimization stage progressively enlarges a long-term memory by saving successful solving processes and tool-wise experience of agents in a tiny pre-defined training set. In the following inference stage, ReflecTool can search for supportive successful demonstrations from already built long-term memory to guide the tool selection strategy, and a verifier improves the tool usage according to the tool-wise experience with two verification methods--iterative refinement and candidate selection. Extensive experiments on ClinicalAgent Benchmark demonstrate that ReflecTool surpasses the pure LLMs with more than 10 points and the well-established agent-based methods with 3 points, highlighting its adaptability and effectiveness in solving complex clinical tasks.
MedCare: Advancing Medical LLMs through Decoupling Clinical Alignment and Knowledge Aggregation
Jun 25, 2024Large language models (LLMs) have shown substantial progress in natural language understanding and generation, proving valuable especially in the medical field. Despite advancements, challenges persist due to the complexity and diversity inherent in medical tasks, which can be categorized as knowledge-intensive tasks and alignment-required tasks. Previous approaches either ignore the latter task or focus on a minority of tasks and hence lose generalization. To address these drawbacks, we propose a progressive fine-tuning pipeline. This pipeline employs a Knowledge Aggregator and a Noise aggregator to encode diverse knowledge in the first stage and filter out detrimental information. In the second stage, we drop the Noise Aggregator to avoid the interference of suboptimal representation and leverage an additional alignment module optimized towards an orthogonal direction to the knowledge space to mitigate knowledge forgetting. Based on this two-stage paradigm, we proposed a Medical LLM through decoupling Clinical Alignment and Knowledge Aggregation (MedCare), which is designed to achieve state-of-the-art (SOTA) performance on over 20 medical tasks, as well as SOTA results on specific medical alignment tasks. Various model sizes of MedCare (1.8B, 7B, 14B) all demonstrate significant improvements over existing models with similar model sizes.
TAIA: Large Language Models are Out-of-Distribution Data Learners
May 30, 2024



Fine-tuning on task-specific question-answer pairs is a predominant method for enhancing the performance of instruction-tuned large language models (LLMs) on downstream tasks. However, in certain specialized domains, such as healthcare or harmless content generation, it is nearly impossible to obtain a large volume of high-quality data that matches the downstream distribution. To improve the performance of LLMs in data-scarce domains with domain-mismatched data, we re-evaluated the Transformer architecture and discovered that not all parameter updates during fine-tuning contribute positively to downstream performance. Our analysis reveals that within the self-attention and feed-forward networks, only the fine-tuned attention parameters are particularly beneficial when the training set's distribution does not fully align with the test set. Based on this insight, we propose an effective inference-time intervention method: \uline{T}raining \uline{A}ll parameters but \uline{I}nferring with only \uline{A}ttention (\trainallInfAttn). We empirically validate \trainallInfAttn using two general instruction-tuning datasets and evaluate it on seven downstream tasks involving math, reasoning, and knowledge understanding across LLMs of different parameter sizes and fine-tuning techniques. Our comprehensive experiments demonstrate that \trainallInfAttn achieves superior improvements compared to both the fully fine-tuned model and the base model in most scenarios, with significant performance gains. The high tolerance of \trainallInfAttn to data mismatches makes it resistant to jailbreaking tuning and enhances specialized tasks using general data.
MING-MOE: Enhancing Medical Multi-Task Learning in Large Language Models with Sparse Mixture of Low-Rank Adapter Experts
Apr 13, 2024



Large language models like ChatGPT have shown substantial progress in natural language understanding and generation, proving valuable across various disciplines, including the medical field. Despite advancements, challenges persist due to the complexity and diversity inherent in medical tasks which often require multi-task learning capabilities. Previous approaches, although beneficial, fall short in real-world applications because they necessitate task-specific annotations at inference time, limiting broader generalization. This paper introduces MING-MOE, a novel Mixture-of-Expert~(MOE)-based medical large language model designed to manage diverse and complex medical tasks without requiring task-specific annotations, thus enhancing its usability across extensive datasets. MING-MOE employs a Mixture of Low-Rank Adaptation (MoLoRA) technique, allowing for efficient parameter usage by maintaining base model parameters static while adapting through a minimal set of trainable parameters. We demonstrate that MING-MOE achieves state-of-the-art (SOTA) performance on over 20 medical tasks, illustrating a significant improvement over existing models. This approach not only extends the capabilities of medical language models but also improves inference efficiency.
Fraud Detection with Binding Global and Local Relational Interaction
Feb 27, 2024Graph Neural Network has been proved to be effective for fraud detection for its capability to encode node interaction and aggregate features in a holistic view. Recently, Transformer network with great sequence encoding ability, has also outperformed other GNN-based methods in literatures. However, both GNN-based and Transformer-based networks only encode one perspective of the whole graph, while GNN encodes global features and Transformer network encodes local ones. Furthermore, previous works ignored encoding global interaction features of the heterogeneous graph with separate networks, thus leading to suboptimal performance. In this work, we present a novel framework called Relation-Aware GNN with transFormer (RAGFormer) which simultaneously embeds local and global features into a target node. The simple yet effective network applies a modified GAGA module where each transformer layer is followed by a cross-relation aggregation layer, to encode local embeddings and node interactions across different relations. Apart from the Transformer-based network, we further introduce a Relation-Aware GNN module to learn global embeddings, which is later merged into the local embeddings by an attention fusion module and a skip connection. Extensive experiments on two popular public datasets and an industrial dataset demonstrate that RAGFormer achieves the state-of-the-art performance. Substantial analysis experiments validate the effectiveness of each submodule of RAGFormer and its high efficiency in utilizing small-scale data and low hyper-parameter sensitivity.