 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent
Jul 03, 2025

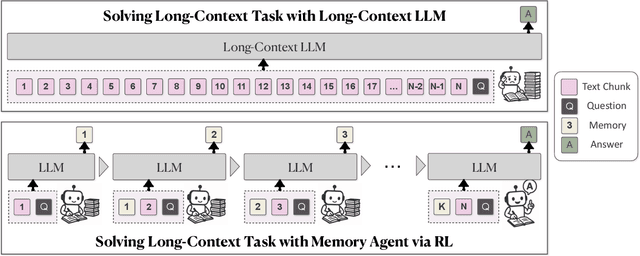
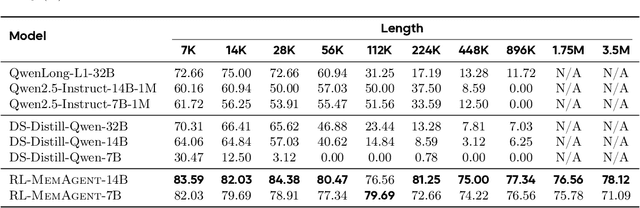
Despite improvements by length extrapolation, efficient attention and memory modules, handling infinitely long documents with linear complexity without performance degradation during extrapolation remains the ultimate challenge in long-text processing. We directly optimize for long-text tasks in an end-to-end fashion and introduce a novel agent workflow, MemAgent, which reads text in segments and updates the memory using an overwrite strategy. We extend the DAPO algorithm to facilitate training via independent-context multi-conversation generation. MemAgent has demonstrated superb long-context capabilities, being able to extrapolate from an 8K context trained on 32K text to a 3.5M QA task with performance loss < 5% and achieves 95%+ in 512K RULER test.
BjTT: A Large-scale Multimodal Dataset for Traffic Prediction
Mar 14, 2024Traffic prediction is one of the most significant foundations in Intelligent Transportation Systems (ITS). Traditional traffic prediction methods rely only on historical traffic data to predict traffic trends and face two main challenges. 1) insensitivity to unusual events. 2) limited performance in long-term prediction. In this work, we explore how generative models combined with text describing the traffic system can be applied for traffic generation, and name the task Text-to-Traffic Generation (TTG). The key challenge of the TTG task is how to associate text with the spatial structure of the road network and traffic data for generating traffic situations. To this end, we propose ChatTraffic, the first diffusion model for text-to-traffic generation. To guarantee the consistency between synthetic and real data, we augment a diffusion model with the Graph Convolutional Network (GCN) to extract spatial correlations of traffic data. In addition, we construct a large dataset containing text-traffic pairs for the TTG task. We benchmarked our model qualitatively and quantitatively on the released dataset. The experimental results indicate that ChatTraffic can generate realistic traffic situations from the text. Our code and dataset are available at https://github.com/ChyaZhang/ChatTraffic.
Linear Attention via Orthogonal Memory
Dec 18, 2023Efficient attentions have greatly improved the computational efficiency of Transformers. However, most existing linear attention mechanisms suffer from an \emph{efficiency degradation} problem, leading to inefficiencies in causal language modeling and hindering their application in long-range language models. This problem is more pronounced under language modeling with unbounded contexts. In this paper, we propose \textbf{L}inear \textbf{A}ttention \textbf{V}ia \textbf{O}rthogonal memory~(\shortname) to address these limitations, achieving strong performance while maintaining linear complexity. \shortname employs orthogonal decomposition to compress a context into a fixed-size orthogonal memory while effectively minimizing redundancy within the context. Given that orthogonal memory compresses global information, we further dissect the context to amplify fine-grained local information. Additionally, we embed the relative position encoding into \shortname to improve the extrapolation ability. Experimental results show that \shortname greatly improves the efficiency of the causal language model with the best extrapolation performance and outperforms other efficient baselines. Further, we endeavor to employ \shortname for unbounded language modeling and successfully scale the context length to 128K.
DiffuSeq-v2: Bridging Discrete and Continuous Text Spaces for Accelerated Seq2Seq Diffusion Models
Oct 16, 2023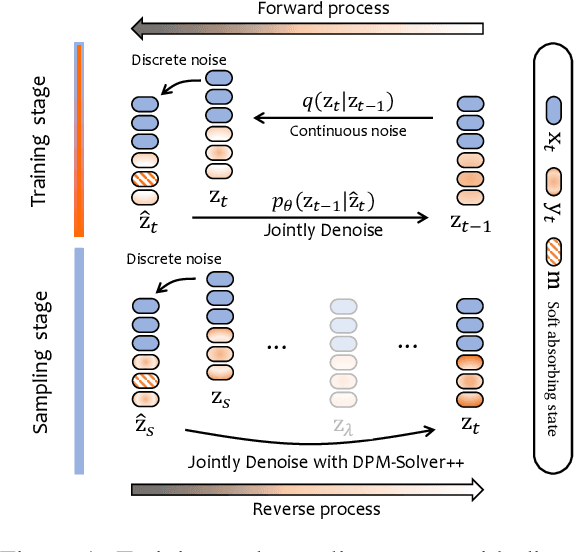
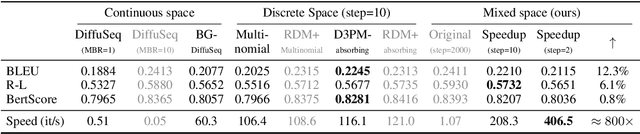
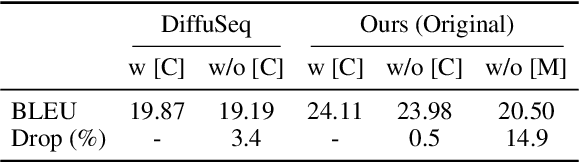
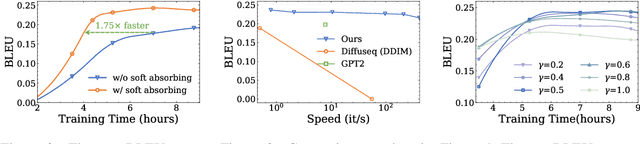
Diffusion models have gained prominence in generating high-quality sequences of text. Nevertheless, current approaches predominantly represent discrete text within a continuous diffusion space, which incurs substantial computational overhead during training and results in slower sampling speeds. In this paper, we introduce a soft absorbing state that facilitates the diffusion model in learning to reconstruct discrete mutations based on the underlying Gaussian space, thereby enhancing its capacity to recover conditional signals. During the sampling phase, we employ state-of-the-art ODE solvers within the continuous space to expedite the sampling process. Comprehensive experimental evaluations reveal that our proposed method effectively accelerates the training convergence by 4x and generates samples of similar quality 800x faster, rendering it significantly closer to practical application. \footnote{The code is released at \url{https://github.com/Shark-NLP/DiffuSeq}
Attentive Multi-Layer Perceptron for Non-autoregressive Generation
Oct 14, 2023Autoregressive~(AR) generation almost dominates sequence generation for its efficacy. Recently, non-autoregressive~(NAR) generation gains increasing popularity for its efficiency and growing efficacy. However, its efficiency is still bottlenecked by quadratic complexity in sequence lengths, which is prohibitive for scaling to long sequence generation and few works have been done to mitigate this problem. In this paper, we propose a novel MLP variant, \textbf{A}ttentive \textbf{M}ulti-\textbf{L}ayer \textbf{P}erceptron~(AMLP), to produce a generation model with linear time and space complexity. Different from classic MLP with static and learnable projection matrices, AMLP leverages adaptive projections computed from inputs in an attentive mode. The sample-aware adaptive projections enable communications among tokens in a sequence, and model the measurement between the query and key space. Furthermore, we marry AMLP with popular NAR models, deriving a highly efficient NAR-AMLP architecture with linear time and space complexity. Empirical results show that such marriage architecture surpasses competitive efficient NAR models, by a significant margin on text-to-speech synthesis and machine translation. We also test AMLP's self- and cross-attention ability separately with extensive ablation experiments, and find them comparable or even superior to the other efficient models. The efficiency analysis further shows that AMLP extremely reduces the memory cost against vanilla non-autoregressive models for long sequences.
Optimizing Non-Autoregressive Transformers with Contrastive Learning
May 23, 2023Non-autoregressive Transformers (NATs) reduce the inference latency of Autoregressive Transformers (ATs) by predicting words all at once rather than in sequential order. They have achieved remarkable progress in machine translation as well as many other applications. However, a long-standing challenge for NATs is the learning of multi-modality data distribution, which is the main cause of the performance gap between NATs and ATs. In this paper, we propose to ease the difficulty of modality learning via sampling from the model distribution instead of the data distribution. We derive contrastive constraints to stabilize the training process and integrate this resulting objective with the state-of-the-art NAT architecture DA-Transformer. Our model \method is examined on 3 different tasks, including machine translation, text summarization, and paraphrasing with 5 benchmarks. Results show that our approach outperforms previous non-autoregressive baselines by a significant margin and establishes new state-of-the-art results for non-autoregressive transformers on all the benchmarks.
OpenICL: An Open-Source Framework for In-context Learning
Mar 06, 2023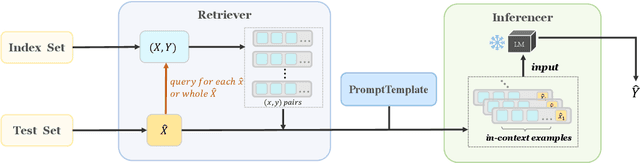

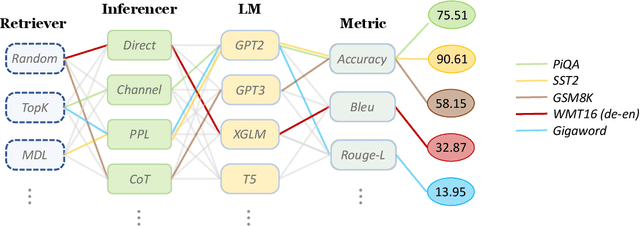
In recent years, In-context Learning (ICL) has gained increasing attention and emerged as the new paradigm for large language model (LLM) evaluation. Unlike traditional fine-tuning methods, ICL instead adapts the pre-trained models to unseen tasks without any parameter updates. However, the implementation of ICL is sophisticated due to the diverse retrieval and inference methods involved, as well as the varying pre-processing requirements for different models, datasets, and tasks. A unified and flexible framework for ICL is urgently needed to ease the implementation of the aforementioned components. To facilitate ICL research, we introduce OpenICL, an open-source toolkit for ICL and LLM evaluation. OpenICL is research-friendly with a highly flexible architecture that users can easily combine different components to suit their needs. It also provides various state-of-the-art retrieval and inference methods to streamline the process of adapting ICL to cutting-edge research. The effectiveness of OpenICL has been validated on a wide range of NLP tasks, including classification, QA, machine translation, and semantic parsing. As a side-product, we found OpenICL to be an efficient yet robust tool for LLMs evaluation. OpenICL is released at https://github.com/Shark-NLP/OpenICL
Compositional Exemplars for In-context Learning
Feb 11, 2023Large pretrained language models (LMs) have shown impressive In-Context Learning (ICL) ability, where the model learns to do an unseen task via a prompt consisting of input-output examples as the demonstration, without any parameter updates. The performance of ICL is highly dominated by the quality of the selected in-context examples. However, previous selection methods are mostly based on simple heuristics, leading to sub-optimal performance. In this work, we formulate in-context example selection as a subset selection problem. We propose CEIL(Compositional Exemplars for In-context Learning), which is instantiated by Determinantal Point Processes (DPPs) to model the interaction between the given input and in-context examples, and optimized through a carefully-designed contrastive learning objective to obtain preference from LMs. We validate CEIL on 12 classification and generation datasets from 7 distinct NLP tasks, including sentiment analysis, paraphrase detection, natural language inference, commonsense reasoning, open-domain question answering, code generation, and semantic parsing. Extensive experiments demonstrate not only the state-of-the-art performance but also the transferability and compositionality of CEIL, shedding new light on effective and efficient in-context learning. Our code is released at https://github.com/HKUNLP/icl-ceil.
In-Context Learning with Many Demonstration Examples
Feb 09, 2023Large pre-training language models (PLMs) have shown promising in-context learning abilities. However, due to the backbone transformer architecture, existing PLMs are bottlenecked by the memory and computational cost when scaling up to a large context size, leaving instruction tuning and in-context learning of many demonstration examples, as well as long-range language modeling under-explored. In this study, we propose a long-range language model EVALM based on an efficient transformer mechanism. EVALM is trained with 8k tokens per batch line and can test up to 256k-lengthed contexts with extrapolation, 128 times to the limit of existing PLMs (e.g. GPT3). Based on EVALM, we scale up the size of examples efficiently in both instruction tuning and in-context learning to explore the boundary of the benefits from more annotated data. Experimental results on a diverse set of tasks show that EVALM achieves 4.1% higher accuracy on average, and the average length of achieving the best accuracy score over tasks is around 12k. We find that in-context learning can achieve higher performance with more demonstrations under many-shot instruction tuning (8k), and further extending the length of instructions (16k) can further improve the upper bound of scaling in-context learning.
CAB: Comprehensive Attention Benchmarking on Long Sequence Modeling
Oct 19, 2022
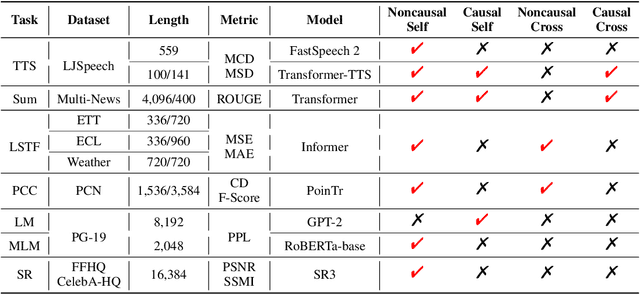


Transformer has achieved remarkable success in language, image, and speech processing. Recently, various efficient attention architectures have been proposed to improve transformer's efficiency while largely preserving its efficacy, especially in modeling long sequences. A widely-used benchmark to test these efficient methods' capability on long-range modeling is Long Range Arena (LRA). However, LRA only focuses on the standard bidirectional (or noncausal) self attention, and completely ignores cross attentions and unidirectional (or causal) attentions, which are equally important to downstream applications. Although designing cross and causal variants of an attention method is straightforward for vanilla attention, it is often challenging for efficient attentions with subquadratic time and memory complexity. In this paper, we propose Comprehensive Attention Benchmark (CAB) under a fine-grained attention taxonomy with four distinguishable attention patterns, namely, noncausal self, causal self, noncausal cross, and causal cross attentions. CAB collects seven real-world tasks from different research areas to evaluate efficient attentions under the four attention patterns. Among these tasks, CAB validates efficient attentions in eight backbone networks to show their generalization across neural architectures. We conduct exhaustive experiments to benchmark the performances of nine widely-used efficient attention architectures designed with different philosophies on CAB. Extensive experimental results also shed light on the fundamental problems of efficient attentions, such as efficiency length against vanilla attention, performance consistency across attention patterns, the benefit of attention mechanisms, and interpolation/extrapolation on long-context language modeling.