 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning Beyond Text: Graph-based Reasoning for Complex Narrative Generation
Apr 23, 2026While LLMs demonstrate remarkable fluency in narrative generation, existing methods struggle to maintain global narrative coherence, contextual logical consistency, and smooth character development, often producing monotonous scripts with structural fractures. To this end, we introduce PLOTTER, a framework that performs narrative planning on structural graph representations instead of the direct sequential text representations used in existing work. Specifically, PLOTTER executes the Evaluate-Plan-Revise cycle on the event graph and character graph. By diagnosing and repairing issues of the graph topology under rigorous logical constraints, the model optimizes the causality and narrative skeleton before complete context generation. Experiments demonstrate that PLOTTER significantly outperforms representative baselines across diverse narrative scenarios. These findings verify that planning narratives on structural graph representations-rather than directly on text-is crucial to enhance the long context reasoning of LLMs in complex narrative generation.
UAV-Track VLA: Embodied Aerial Tracking via Vision-Language-Action Models
Apr 02, 2026Embodied visual tracking is crucial for Unmanned Aerial Vehicles (UAVs) executing complex real-world tasks. In dynamic urban scenarios with complex semantic requirements, Vision-Language-Action (VLA) models show great promise due to their cross-modal fusion and continuous action generation capabilities. To benchmark multimodal tracking in such environments, we construct a dedicated evaluation benchmark and a large-scale dataset encompassing over 890K frames, 176 tasks, and 85 diverse objects. Furthermore, to address temporal feature redundancy and the lack of spatial geometric priors in existing VLA models, we propose an improved VLA tracking model, UAV-Track VLA. Built upon the $π_{0.5}$ architecture, our model introduces a temporal compression net to efficiently capture inter-frame dynamics. Additionally, a parallel dual-branch decoder comprising a spatial-aware auxiliary grounding head and a flow matching action expert is designed to decouple cross-modal features and generate fine-grained continuous actions. Systematic experiments in the CARLA simulator validate the superior end-to-end performance of our method. Notably, in challenging long-distance pedestrian tracking tasks, UAV-Track VLA achieves a 61.76\% success rate and 269.65 average tracking frames, significantly outperforming existing baselines. Furthermore, it demonstrates robust zero-shot generalization in unseen environments and reduces single-step inference latency by 33.4\% (to 0.0571s) compared to the original $π_{0.5}$, enabling highly efficient, real-time UAV control. Data samples and demonstration videos are available at: https://github.com/Hub-Tian/UAV-Track\_VLA.
OpenCOOD-Air: Prompting Heterogeneous Ground-Air Collaborative Perception with Spatial Conversion and Offset Prediction
Mar 14, 2026While Vehicle-to-Vehicle (V2V) collaboration extends sensing ranges through multi-agent data sharing, its reliability remains severely constrained by ground-level occlusions and the limited perspective of chassis-mounted sensors, which often result in critical perception blind spots. We propose OpenCOOD-Air, a novel framework that integrates UAVs as extensible platforms into V2V collaborative perception to overcome these constraints. To mitigate gradient interference from ground-air domain gaps and data sparsity, we adopt a transfer learning strategy to fine-tune UAV weights from pre-trained V2V models. To prevent the spatial information loss inherent in this transition, we formulate ground-air collaborative perception as a heterogeneous integration task with explicit altitude supervision and introduce a Cross-Domain Spatial Converter (CDSC) and a Spatial Offset Prediction Transformer (SOPT). Furthermore, we present the OPV2V-Air benchmark to validate the transition from V2V to Vehicle-to-Vehicle-to-UAV. Compared to state-of-the-art methods, our approach improves 2D and 3D AP@0.7 by 4% and 7%, respectively.
AIR-VLA: Vision-Language-Action Systems for Aerial Manipulation
Jan 29, 2026While Vision-Language-Action (VLA) models have achieved remarkable success in ground-based embodied intelligence, their application to Aerial Manipulation Systems (AMS) remains a largely unexplored frontier. The inherent characteristics of AMS, including floating-base dynamics, strong coupling between the UAV and the manipulator, and the multi-step, long-horizon nature of operational tasks, pose severe challenges to existing VLA paradigms designed for static or 2D mobile bases. To bridge this gap, we propose AIR-VLA, the first VLA benchmark specifically tailored for aerial manipulation. We construct a physics-based simulation environment and release a high-quality multimodal dataset comprising 3000 manually teleoperated demonstrations, covering base manipulation, object & spatial understanding, semantic reasoning, and long-horizon planning. Leveraging this platform, we systematically evaluate mainstream VLA models and state-of-the-art VLM models. Our experiments not only validate the feasibility of transferring VLA paradigms to aerial systems but also, through multi-dimensional metrics tailored to aerial tasks, reveal the capabilities and boundaries of current models regarding UAV mobility, manipulator control, and high-level planning. AIR-VLA establishes a standardized testbed and data foundation for future research in general-purpose aerial robotics. The resource of AIR-VLA will be available at https://anonymous.4open.science/r/AIR-VLA-dataset-B5CC/.
CogRail: Benchmarking VLMs in Cognitive Intrusion Perception for Intelligent Railway Transportation Systems
Jan 14, 2026Accurate and early perception of potential intrusion targets is essential for ensuring the safety of railway transportation systems. However, most existing systems focus narrowly on object classification within fixed visual scopes and apply rule-based heuristics to determine intrusion status, often overlooking targets that pose latent intrusion risks. Anticipating such risks requires the cognition of spatial context and temporal dynamics for the object of interest (OOI), which presents challenges for conventional visual models. To facilitate deep intrusion perception, we introduce a novel benchmark, CogRail, which integrates curated open-source datasets with cognitively driven question-answer annotations to support spatio-temporal reasoning and prediction. Building upon this benchmark, we conduct a systematic evaluation of state-of-the-art visual-language models (VLMs) using multimodal prompts to identify their strengths and limitations in this domain. Furthermore, we fine-tune VLMs for better performance and propose a joint fine-tuning framework that integrates three core tasks, position perception, movement prediction, and threat analysis, facilitating effective adaptation of general-purpose foundation models into specialized models tailored for cognitive intrusion perception. Extensive experiments reveal that current large-scale multimodal models struggle with the complex spatial-temporal reasoning required by the cognitive intrusion perception task, underscoring the limitations of existing foundation models in this safety-critical domain. In contrast, our proposed joint fine-tuning framework significantly enhances model performance by enabling targeted adaptation to domain-specific reasoning demands, highlighting the advantages of structured multi-task learning in improving both accuracy and interpretability. Code will be available at https://github.com/Hub-Tian/CogRail.
MedGround: Bridging the Evidence Gap in Medical Vision-Language Models with Verified Grounding Data
Jan 11, 2026Vision-Language Models (VLMs) can generate convincing clinical narratives, yet frequently struggle to visually ground their statements. We posit this limitation arises from the scarcity of high-quality, large-scale clinical referring-localization pairs. To address this, we introduce MedGround, an automated pipeline that transforms segmentation resources into high-quality medical referring grounding data. Leveraging expert masks as spatial anchors, MedGround precisely derives localization targets, extracts shape and spatial cues, and guides VLMs to synthesize natural, clinically grounded queries that reflect morphology and location. To ensure data rigor, a multi-stage verification system integrates strict formatting checks, geometry- and medical-prior rules, and image-based visual judging to filter out ambiguous or visually unsupported samples. Finally, we present MedGround-35K, a novel multimodal medical dataset. Extensive experiments demonstrate that VLMs trained with MedGround-35K consistently achieve improved referring grounding performance, enhance multi-object semantic disambiguation, and exhibit strong generalization to unseen grounding settings. This work highlights MedGround as a scalable, data-driven approach to anchor medical language to verifiable visual evidence. Dataset and code will be released publicly upon acceptance.
AstroReview: An LLM-driven Multi-Agent Framework for Telescope Proposal Peer Review and Refinement
Dec 31, 2025Competitive access to modern observatories has intensified as proposal volumes outpace available telescope time, making timely, consistent, and transparent peer review a critical bottleneck for the advancement of astronomy. Automating parts of this process is therefore both scientifically significant and operationally necessary to ensure fair allocation and reproducible decisions at scale. We present AstroReview, an open-source, agent-based framework that automates proposal review in three stages: (i) novelty and scientific merit, (ii) feasibility and expected yield, and (iii) meta-review and reliability verification. Task isolation and explicit reasoning traces curb hallucinations and improve transparency. Without any domain specific fine tuning, AstroReview used in our experiments only for the last stage, correctly identifies genuinely accepted proposals with an accuracy of 87%. The AstroReview in Action module replicates the review and refinement loop; with its integrated Proposal Authoring Agent, the acceptance rate of revised drafts increases by 66% after two iterations, showing that iterative feedback combined with automated meta-review and reliability verification delivers measurable quality gains. Together, these results point to a practical path toward scalable, auditable, and higher throughput proposal review for resource limited facilities.
Context-Aware Probabilistic Modeling with LLM for Multimodal Time Series Forecasting
May 16, 2025Time series forecasting is important for applications spanning energy markets, climate analysis, and traffic management. However, existing methods struggle to effectively integrate exogenous texts and align them with the probabilistic nature of large language models (LLMs). Current approaches either employ shallow text-time series fusion via basic prompts or rely on deterministic numerical decoding that conflict with LLMs' token-generation paradigm, which limits contextual awareness and distribution modeling. To address these limitations, we propose CAPTime, a context-aware probabilistic multimodal time series forecasting method that leverages text-informed abstraction and autoregressive LLM decoding. Our method first encodes temporal patterns using a pretrained time series encoder, then aligns them with textual contexts via learnable interactions to produce joint multimodal representations. By combining a mixture of distribution experts with frozen LLMs, we enable context-aware probabilistic forecasting while preserving LLMs' inherent distribution modeling capabilities. Experiments on diverse time series forecasting tasks demonstrate the superior accuracy and generalization of CAPTime, particularly in multimodal scenarios. Additional analysis highlights its robustness in data-scarce scenarios through hybrid probabilistic decoding.
Stop Summation: Min-Form Credit Assignment Is All Process Reward Model Needs for Reasoning
Apr 21, 2025



Process reward models (PRMs) have proven effective for test-time scaling of Large Language Models (LLMs) on challenging reasoning tasks. However, reward hacking issues with PRMs limit their successful application in reinforcement fine-tuning. In this paper, we identify the main cause of PRM-induced reward hacking: the canonical summation-form credit assignment in reinforcement learning (RL), which defines the value as cumulative gamma-decayed future rewards, easily induces LLMs to hack steps with high rewards. To address this, we propose PURE: Process sUpervised Reinforcement lEarning. The key innovation of PURE is a min-form credit assignment that formulates the value function as the minimum of future rewards. This method significantly alleviates reward hacking by limiting the value function range and distributing advantages more reasonably. Through extensive experiments on 3 base models, we show that PRM-based approaches enabling min-form credit assignment achieve comparable reasoning performance to verifiable reward-based methods within only 30% steps. In contrast, the canonical sum-form credit assignment collapses training even at the beginning! Additionally, when we supplement PRM-based fine-tuning with just 10% verifiable rewards, we further alleviate reward hacking and produce the best fine-tuned model based on Qwen2.5-Math-7B in our experiments, achieving 82.5% accuracy on AMC23 and 53.3% average accuracy across 5 benchmarks. Moreover, we summarize the observed reward hacking cases and analyze the causes of training collapse. Code and models are available at https://github.com/CJReinforce/PURE.
Offline Reinforcement Learning with Discrete Diffusion Skills
Mar 26, 2025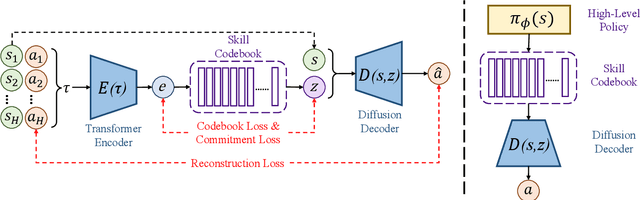
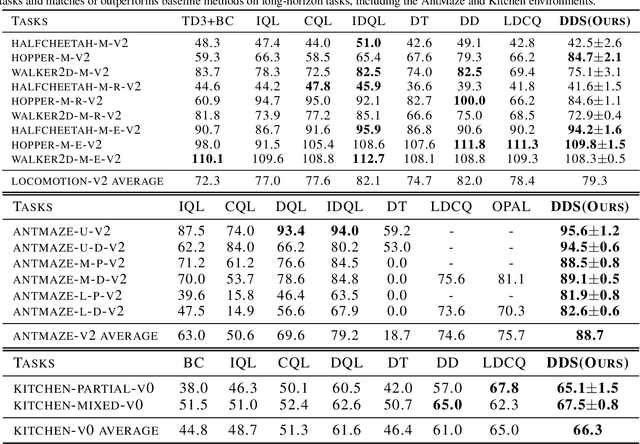
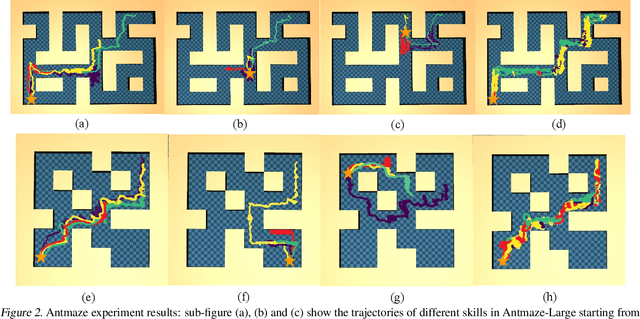
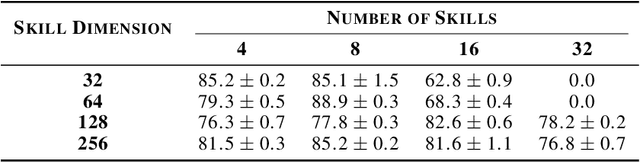
Skills have been introduced to offline reinforcement learning (RL) as temporal abstractions to tackle complex, long-horizon tasks, promoting consistent behavior and enabling meaningful exploration. While skills in offline RL are predominantly modeled within a continuous latent space, the potential of discrete skill spaces remains largely underexplored. In this paper, we propose a compact discrete skill space for offline RL tasks supported by state-of-the-art transformer-based encoder and diffusion-based decoder. Coupled with a high-level policy trained via offline RL techniques, our method establishes a hierarchical RL framework where the trained diffusion decoder plays a pivotal role. Empirical evaluations show that the proposed algorithm, Discrete Diffusion Skill (DDS), is a powerful offline RL method. DDS performs competitively on Locomotion and Kitchen tasks and excels on long-horizon tasks, achieving at least a 12 percent improvement on AntMaze-v2 benchmarks compared to existing offline RL approaches. Furthermore, DDS offers improved interpretability, training stability, and online exploration compared to previous skill-based methods.