 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaSpark: Adaptive Sparsity for Efficient Long-Video Understanding
Apr 09, 2026Processing long-form videos with Video Large Language Models (Video-LLMs) is computationally prohibitive. Current efficiency methods often compromise fine-grained perception through irreversible information disposal or inhibit long-range temporal modeling via rigid, predefined sparse patterns. This paper introduces AdaSpark, an adaptive sparsity framework designed to address these limitations. AdaSpark first partitions video inputs into 3D spatio-temporal cubes. It then employs two co-designed, context-aware components: (1) Adaptive Cube-Selective Attention (AdaS-Attn), which adaptively selects a subset of relevant video cubes to attend for each query token, and (2) Adaptive Token-Selective FFN (AdaS-FFN), which selectively processes only the most salient tokens within each cube. An entropy-based (Top-p) selection mechanism adaptively allocates computational resources based on input complexity. Experiments demonstrate that AdaSpark significantly reduces computational load by up to 57% FLOPs while maintaining comparable performance to dense models and preserving fine-grained, long-range dependencies, as validated on challenging hour-scale video benchmarks.
Prefix Grouper: Efficient GRPO Training through Shared-Prefix Forward
Jun 05, 2025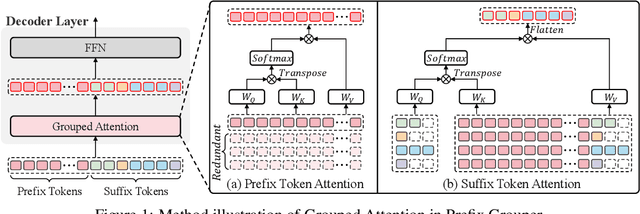
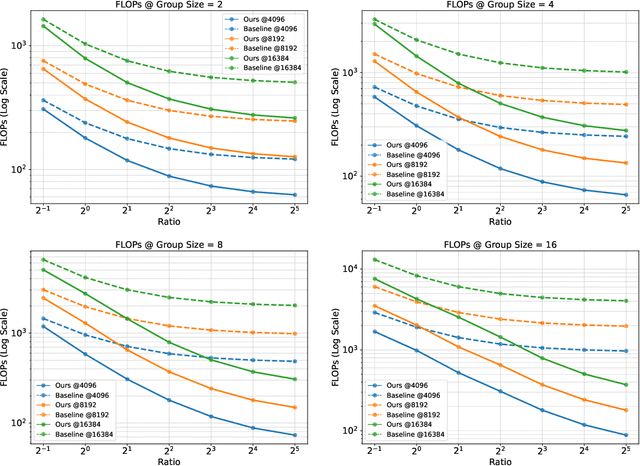
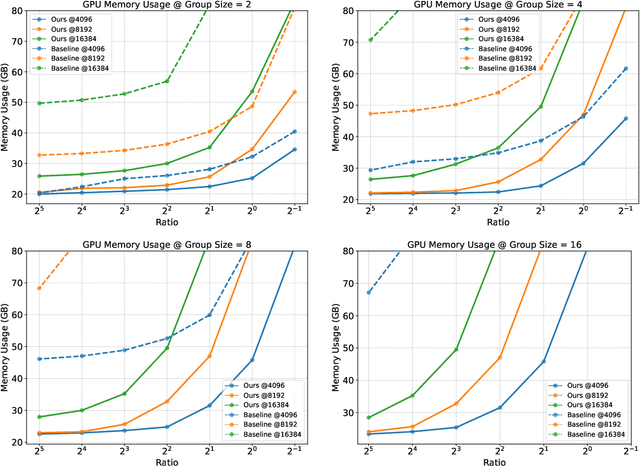
Group Relative Policy Optimization (GRPO) enhances policy learning by computing gradients from relative comparisons among candidate outputs that share a common input prefix. Despite its effectiveness, GRPO introduces substantial computational overhead when processing long shared prefixes, which must be redundantly encoded for each group member. This inefficiency becomes a major scalability bottleneck in long-context learning scenarios. We propose Prefix Grouper, an efficient GRPO training algorithm that eliminates redundant prefix computation via a Shared-Prefix Forward strategy. In particular, by restructuring self-attention into two parts, our method enables the shared prefix to be encoded only once, while preserving full differentiability and compatibility with end-to-end training. We provide both theoretical and empirical evidence that Prefix Grouper is training-equivalent to standard GRPO: it yields identical forward outputs and backward gradients, ensuring that the optimization dynamics and final policy performance remain unchanged. Empirically, our experiments confirm that Prefix Grouper achieves consistent results while significantly reducing the computational cost of training, particularly in long-prefix scenarios. The proposed method is fully plug-and-play: it is compatible with existing GRPO-based architectures and can be seamlessly integrated into current training pipelines as a drop-in replacement, requiring no structural modifications and only minimal changes to input construction and attention computation. Prefix Grouper enables the use of larger group sizes under the same computational budget, thereby improving the scalability of GRPO to more complex tasks and larger models. Code is now available at https://github.com/johncaged/PrefixGrouper
Towards Unified Referring Expression Segmentation Across Omni-Level Visual Target Granularities
Apr 02, 2025Referring expression segmentation (RES) aims at segmenting the entities' masks that match the descriptive language expression. While traditional RES methods primarily address object-level grounding, real-world scenarios demand a more versatile framework that can handle multiple levels of target granularity, such as multi-object, single object or part-level references. This introduces great challenges due to the diverse and nuanced ways users describe targets. However, existing datasets and models mainly focus on designing grounding specialists for object-level target localization, lacking the necessary data resources and unified frameworks for the more practical multi-grained RES. In this paper, we take a step further towards visual granularity unified RES task. To overcome the limitation of data scarcity, we introduce a new multi-granularity referring expression segmentation (MRES) task, alongside the RefCOCOm benchmark, which includes part-level annotations for advancing finer-grained visual understanding. In addition, we create MRES-32M, the largest visual grounding dataset, comprising over 32.2M masks and captions across 1M images, specifically designed for part-level vision-language grounding. To tackle the challenges of multi-granularity RES, we propose UniRES++, a unified multimodal large language model that integrates object-level and part-level RES tasks. UniRES++ incorporates targeted designs for fine-grained visual feature exploration. With the joint model architecture and parameters, UniRES++ achieves state-of-the-art performance across multiple benchmarks, including RefCOCOm for MRES, gRefCOCO for generalized RES, and RefCOCO, RefCOCO+, RefCOCOg for classic RES. To foster future research into multi-grained visual grounding, our RefCOCOm benchmark, MRES-32M dataset and model UniRES++ will be publicly available at https://github.com/Rubics-Xuan/MRES.
Efficient Motion-Aware Video MLLM
Mar 17, 2025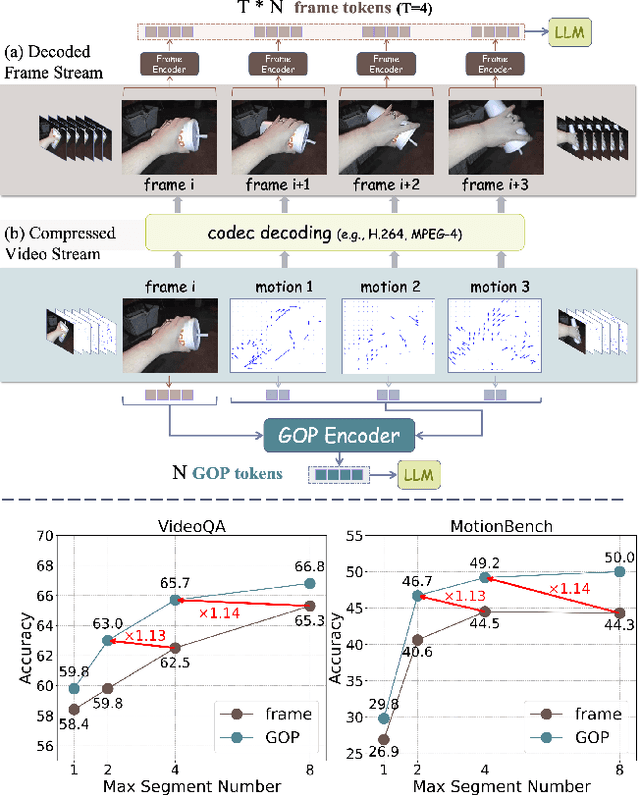
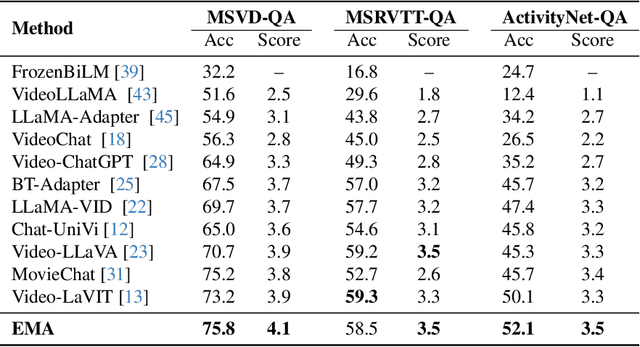
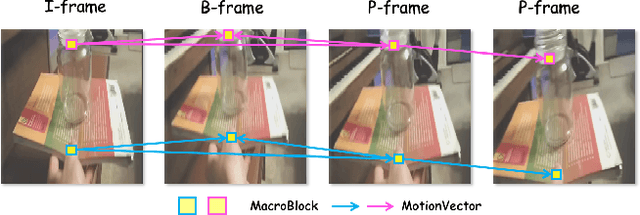
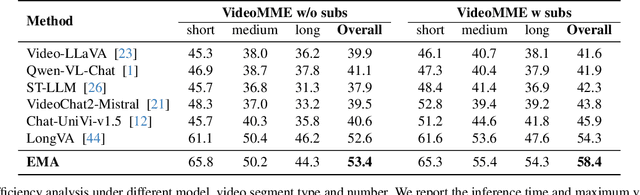
Most current video MLLMs rely on uniform frame sampling and image-level encoders, resulting in inefficient data processing and limited motion awareness. To address these challenges, we introduce EMA, an Efficient Motion-Aware video MLLM that utilizes compressed video structures as inputs. We propose a motion-aware GOP (Group of Pictures) encoder that fuses spatial and motion information within a GOP unit in the compressed video stream, generating compact, informative visual tokens. By integrating fewer but denser RGB frames with more but sparser motion vectors in this native slow-fast input architecture, our approach reduces redundancy and enhances motion representation. Additionally, we introduce MotionBench, a benchmark for evaluating motion understanding across four motion types: linear, curved, rotational, and contact-based. Experimental results show that EMA achieves state-of-the-art performance on both MotionBench and popular video question answering benchmarks, while reducing inference costs. Moreover, EMA demonstrates strong scalability, as evidenced by its competitive performance on long video understanding benchmarks.
ChatSearch: a Dataset and a Generative Retrieval Model for General Conversational Image Retrieval
Oct 24, 2024
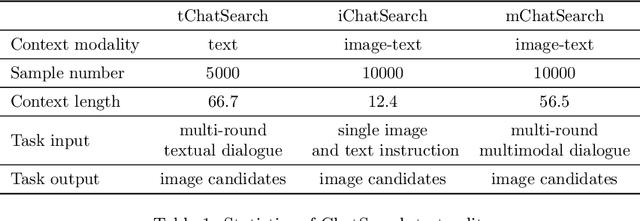
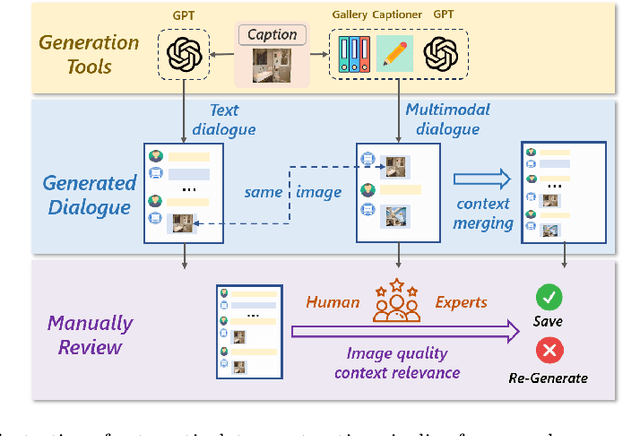
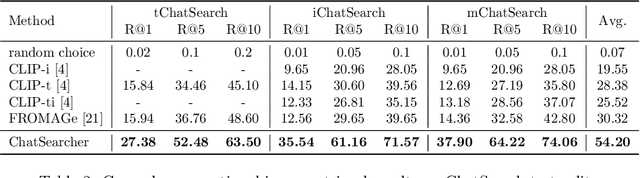
In this paper, we investigate the task of general conversational image retrieval on open-domain images. The objective is to search for images based on interactive conversations between humans and computers. To advance this task, we curate a dataset called ChatSearch. This dataset includes a multi-round multimodal conversational context query for each target image, thereby requiring the retrieval system to find the accurate image from database. Simultaneously, we propose a generative retrieval model named ChatSearcher, which is trained end-to-end to accept/produce interleaved image-text inputs/outputs. ChatSearcher exhibits strong capability in reasoning with multimodal context and can leverage world knowledge to yield visual retrieval results. It demonstrates superior performance on the ChatSearch dataset and also achieves competitive results on other image retrieval tasks and visual conversation tasks. We anticipate that this work will inspire further research on interactive multimodal retrieval systems. Our dataset will be available at https://github.com/joez17/ChatSearch.
Ada-K Routing: Boosting the Efficiency of MoE-based LLMs
Oct 15, 2024



In the era of Large Language Models (LLMs), Mixture-of-Experts (MoE) architectures offer a promising approach to managing computational costs while scaling up model parameters. Conventional MoE-based LLMs typically employ static Top-K routing, which activates a fixed and equal number of experts for each token regardless of their significance within the context. In this paper, we propose a novel Ada-K routing strategy that dynamically adjusts the number of activated experts for each token, thereby improving the balance between computational efficiency and model performance. Specifically, our strategy incorporates learnable and lightweight allocator modules that decide customized expert resource allocation tailored to the contextual needs for each token. These allocators are designed to be fully pluggable, making it broadly applicable across all mainstream MoE-based LLMs. We leverage the Proximal Policy Optimization (PPO) algorithm to facilitate an end-to-end learning process for this non-differentiable decision-making framework. Extensive evaluations on four popular baseline models demonstrate that our Ada-K routing method significantly outperforms conventional Top-K routing. Compared to Top-K, our method achieves over 25% reduction in FLOPs and more than 20% inference speedup while still improving performance across various benchmarks. Moreover, the training of Ada-K is highly efficient. Even for Mixtral-8x22B, a MoE-based LLM with more than 140B parameters, the training time is limited to 8 hours. Detailed analysis shows that harder tasks, middle layers, and content words tend to activate more experts, providing valuable insights for future adaptive MoE system designs. Both the training code and model checkpoints will be publicly available.
OneDiff: A Generalist Model for Image Difference
Jul 08, 2024



In computer vision, Image Difference Captioning (IDC) is crucial for accurately describing variations between closely related images. Traditional IDC methods often rely on specialist models, which restrict their applicability across varied contexts. This paper introduces the OneDiff model, a novel generalist approach that utilizes a robust vision-language model architecture, integrating a siamese image encoder with a Visual Delta Module. This innovative configuration allows for the precise detection and articulation of fine-grained differences between image pairs. OneDiff is trained through a dual-phase strategy, encompassing Coupled Sample Training and multi-task learning across a diverse array of data types, supported by our newly developed DiffCap Dataset. This dataset merges real-world and synthetic data, enhancing the training process and bolstering the model's robustness. Extensive testing on diverse IDC benchmarks, such as Spot-the-Diff, CLEVR-Change, and Birds-to-Words, shows that OneDiff consistently outperforms existing state-of-the-art models in accuracy and adaptability, achieving improvements of up to 85\% CIDEr points in average. By setting a new benchmark in IDC, OneDiff paves the way for more versatile and effective applications in detecting and describing visual differences. The code, models, and data will be made publicly available.
Needle In A Video Haystack: A Scalable Synthetic Framework for Benchmarking Video MLLMs
Jun 13, 2024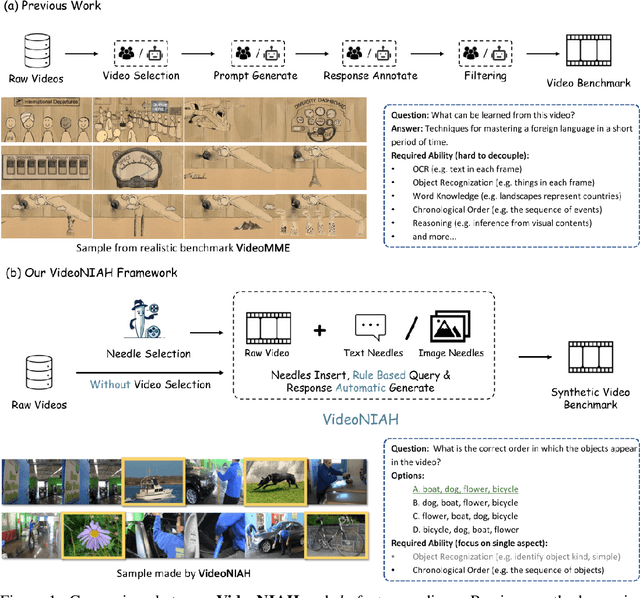
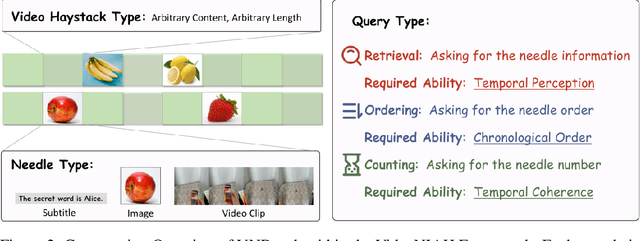
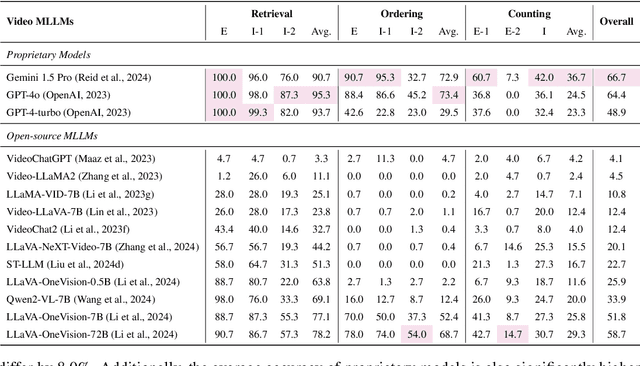
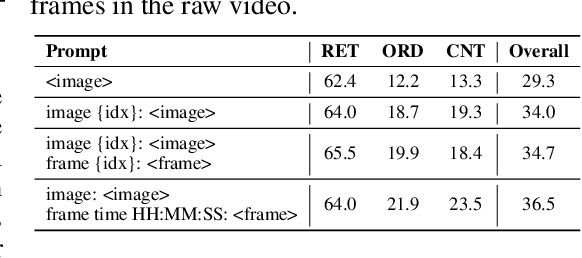
Video understanding is a crucial next step for multimodal large language models (MLLMs). To probe specific aspects of video understanding ability, existing video benchmarks typically require careful video selection based on the target capability, along with laborious annotation of query-response pairs to match the specific video content. This process is both challenging and resource-intensive. In this paper, we propose VideoNIAH (Video Needle In A Haystack), a benchmark construction framework through synthetic video generation. VideoNIAH decouples test video content from their query-responses by inserting unrelated image/text 'needles' into original videos. It generates annotations solely from these needles, ensuring diversity in video sources and a variety of query-responses. Additionally, by inserting multiple needles, VideoNIAH rigorously evaluates the temporal understanding capabilities of models. We utilized VideoNIAH to compile a video benchmark VNBench, including tasks such as retrieval, ordering, and counting. VNBench can efficiently evaluate the fine-grained understanding ability and spatio-temporal modeling ability of a video model, while also supporting the long-context evaluation. Additionally, we evaluated recent video-centric multimodal large language models (MLLMs), both open-source and proprietary, providing a comprehensive analysis. We found that although proprietary models have significant advantages over open-source models, all existing video models still perform poorly on long-distance dependency tasks. VideoNIAH is a simple yet highly scalable benchmark construction framework, and we believe it will inspire future video benchmark works. The code and data are available at https://github.com/joez17/VideoNIAH.
SC-Tune: Unleashing Self-Consistent Referential Comprehension in Large Vision Language Models
Mar 20, 2024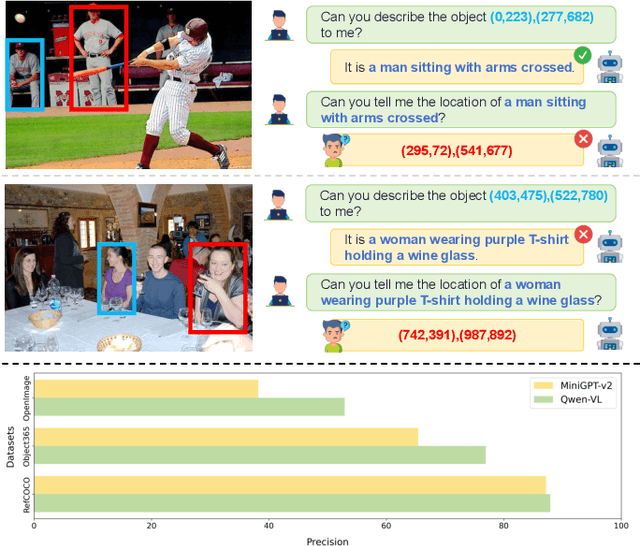

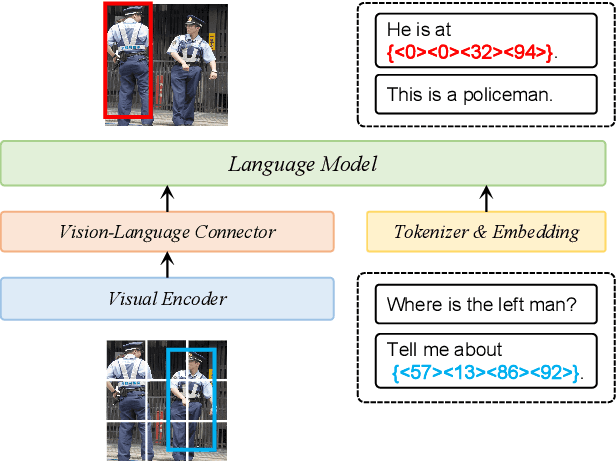

Recent trends in Large Vision Language Models (LVLMs) research have been increasingly focusing on advancing beyond general image understanding towards more nuanced, object-level referential comprehension. In this paper, we present and delve into the self-consistency capability of LVLMs, a crucial aspect that reflects the models' ability to both generate informative captions for specific objects and subsequently utilize these captions to accurately re-identify the objects in a closed-loop process. This capability significantly mirrors the precision and reliability of fine-grained visual-language understanding. Our findings reveal that the self-consistency level of existing LVLMs falls short of expectations, posing limitations on their practical applicability and potential. To address this gap, we introduce a novel fine-tuning paradigm named Self-Consistency Tuning (SC-Tune). It features the synergistic learning of a cyclic describer-locator system. This paradigm is not only data-efficient but also exhibits generalizability across multiple LVLMs. Through extensive experiments, we demonstrate that SC-Tune significantly elevates performance across a spectrum of object-level vision-language benchmarks and maintains competitive or improved performance on image-level vision-language benchmarks. Both our model and code will be publicly available at https://github.com/ivattyue/SC-Tune.
Unveiling Parts Beyond Objects:Towards Finer-Granularity Referring Expression Segmentation
Dec 13, 2023
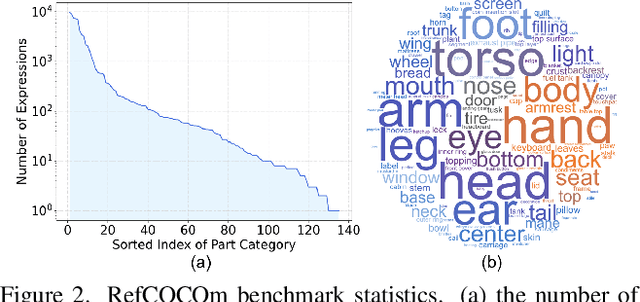
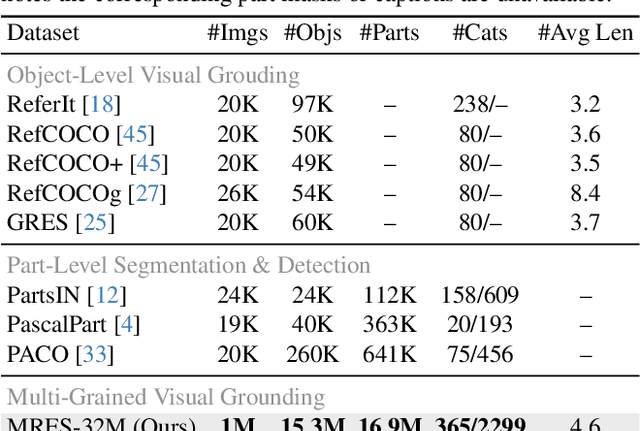
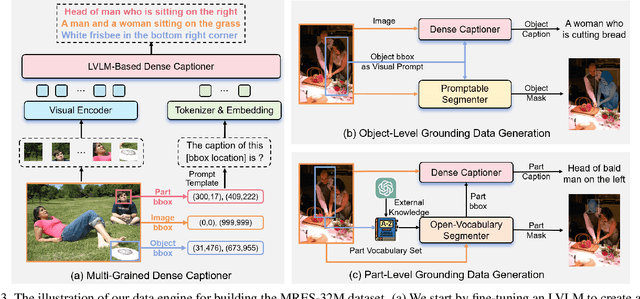
Referring expression segmentation (RES) aims at segmenting the foreground masks of the entities that match the descriptive natural language expression. Previous datasets and methods for classic RES task heavily rely on the prior assumption that one expression must refer to object-level targets. In this paper, we take a step further to finer-grained part-level RES task. To promote the object-level RES task towards finer-grained vision-language understanding, we put forward a new multi-granularity referring expression segmentation (MRES) task and construct an evaluation benchmark called RefCOCOm by manual annotations. By employing our automatic model-assisted data engine, we build the largest visual grounding dataset namely MRES-32M, which comprises over 32.2M high-quality masks and captions on the provided 1M images. Besides, a simple yet strong model named UniRES is designed to accomplish the unified object-level and part-level grounding task. Extensive experiments on our RefCOCOm for MRES and three datasets (i.e., RefCOCO(+/g) for classic RES task demonstrate the superiority of our method over previous state-of-the-art methods. To foster future research into fine-grained visual grounding, our benchmark RefCOCOm, the MRES-32M dataset and model UniRES will be publicly available at https://github.com/Rubics-Xuan/MRES