 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS1-MMAlign: A Large-Scale, Multi-Disciplinary Dataset for Scientific Figure-Text Understanding
Jan 01, 2026Multimodal learning has revolutionized general domain tasks, yet its application in scientific discovery is hindered by the profound semantic gap between complex scientific imagery and sparse textual descriptions. We present S1-MMAlign, a large-scale, multi-disciplinary multimodal dataset comprising over 15.5 million high-quality image-text pairs derived from 2.5 million open-access scientific papers. Spanning disciplines from physics and biology to engineering, the dataset captures diverse visual modalities including experimental setups, heatmaps, and microscopic imagery. To address the pervasive issue of weak alignment in raw scientific captions, we introduce an AI-ready semantic enhancement pipeline that utilizes the Qwen-VL multimodal large model series to recaption images by synthesizing context from paper abstracts and citation contexts. Technical validation demonstrates that this enhancement significantly improves data quality: SciBERT-based pseudo-perplexity metrics show reduced semantic ambiguity, while CLIP scores indicate an 18.21% improvement in image-text alignment. S1-MMAlign provides a foundational resource for advancing scientific reasoning and cross-modal understanding in the era of AI for Science. The dataset is publicly available at https://huggingface.co/datasets/ScienceOne-AI/S1-MMAlign.
UrbanNav: Learning Language-Guided Urban Navigation from Web-Scale Human Trajectories
Dec 10, 2025
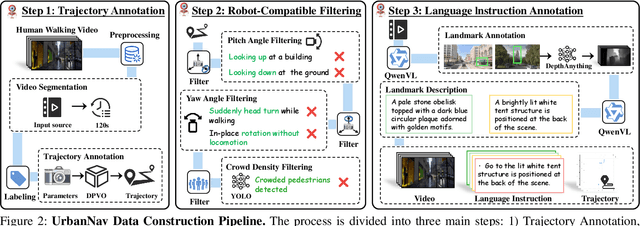
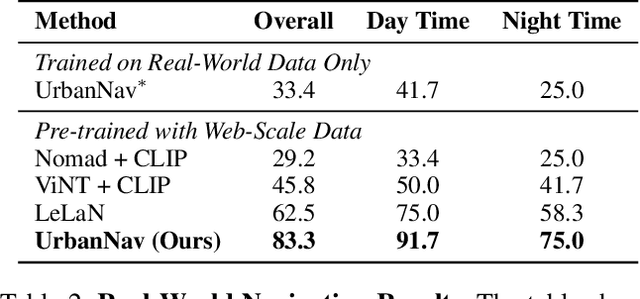
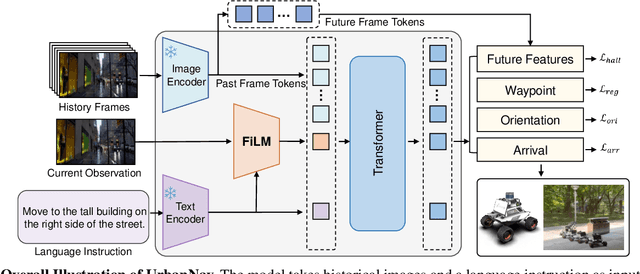
Navigating complex urban environments using natural language instructions poses significant challenges for embodied agents, including noisy language instructions, ambiguous spatial references, diverse landmarks, and dynamic street scenes. Current visual navigation methods are typically limited to simulated or off-street environments, and often rely on precise goal formats, such as specific coordinates or images. This limits their effectiveness for autonomous agents like last-mile delivery robots navigating unfamiliar cities. To address these limitations, we introduce UrbanNav, a scalable framework that trains embodied agents to follow free-form language instructions in diverse urban settings. Leveraging web-scale city walking videos, we develop an scalable annotation pipeline that aligns human navigation trajectories with language instructions grounded in real-world landmarks. UrbanNav encompasses over 1,500 hours of navigation data and 3 million instruction-trajectory-landmark triplets, capturing a wide range of urban scenarios. Our model learns robust navigation policies to tackle complex urban scenarios, demonstrating superior spatial reasoning, robustness to noisy instructions, and generalization to unseen urban settings. Experimental results show that UrbanNav significantly outperforms existing methods, highlighting the potential of large-scale web video data to enable language-guided, real-world urban navigation for embodied agents.
Prefix Grouper: Efficient GRPO Training through Shared-Prefix Forward
Jun 05, 2025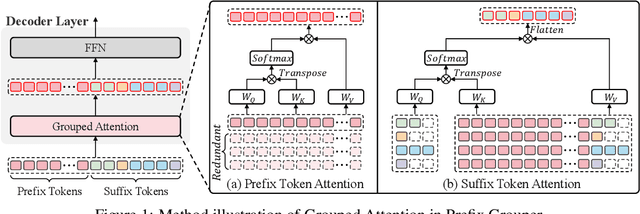
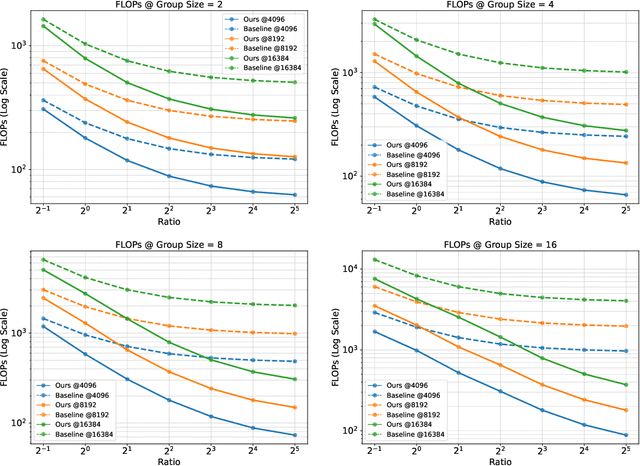
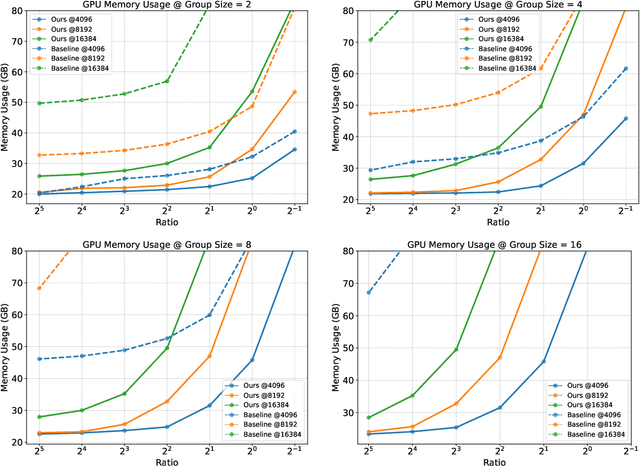
Group Relative Policy Optimization (GRPO) enhances policy learning by computing gradients from relative comparisons among candidate outputs that share a common input prefix. Despite its effectiveness, GRPO introduces substantial computational overhead when processing long shared prefixes, which must be redundantly encoded for each group member. This inefficiency becomes a major scalability bottleneck in long-context learning scenarios. We propose Prefix Grouper, an efficient GRPO training algorithm that eliminates redundant prefix computation via a Shared-Prefix Forward strategy. In particular, by restructuring self-attention into two parts, our method enables the shared prefix to be encoded only once, while preserving full differentiability and compatibility with end-to-end training. We provide both theoretical and empirical evidence that Prefix Grouper is training-equivalent to standard GRPO: it yields identical forward outputs and backward gradients, ensuring that the optimization dynamics and final policy performance remain unchanged. Empirically, our experiments confirm that Prefix Grouper achieves consistent results while significantly reducing the computational cost of training, particularly in long-prefix scenarios. The proposed method is fully plug-and-play: it is compatible with existing GRPO-based architectures and can be seamlessly integrated into current training pipelines as a drop-in replacement, requiring no structural modifications and only minimal changes to input construction and attention computation. Prefix Grouper enables the use of larger group sizes under the same computational budget, thereby improving the scalability of GRPO to more complex tasks and larger models. Code is now available at https://github.com/johncaged/PrefixGrouper
Towards Unified Referring Expression Segmentation Across Omni-Level Visual Target Granularities
Apr 02, 2025Referring expression segmentation (RES) aims at segmenting the entities' masks that match the descriptive language expression. While traditional RES methods primarily address object-level grounding, real-world scenarios demand a more versatile framework that can handle multiple levels of target granularity, such as multi-object, single object or part-level references. This introduces great challenges due to the diverse and nuanced ways users describe targets. However, existing datasets and models mainly focus on designing grounding specialists for object-level target localization, lacking the necessary data resources and unified frameworks for the more practical multi-grained RES. In this paper, we take a step further towards visual granularity unified RES task. To overcome the limitation of data scarcity, we introduce a new multi-granularity referring expression segmentation (MRES) task, alongside the RefCOCOm benchmark, which includes part-level annotations for advancing finer-grained visual understanding. In addition, we create MRES-32M, the largest visual grounding dataset, comprising over 32.2M masks and captions across 1M images, specifically designed for part-level vision-language grounding. To tackle the challenges of multi-granularity RES, we propose UniRES++, a unified multimodal large language model that integrates object-level and part-level RES tasks. UniRES++ incorporates targeted designs for fine-grained visual feature exploration. With the joint model architecture and parameters, UniRES++ achieves state-of-the-art performance across multiple benchmarks, including RefCOCOm for MRES, gRefCOCO for generalized RES, and RefCOCO, RefCOCO+, RefCOCOg for classic RES. To foster future research into multi-grained visual grounding, our RefCOCOm benchmark, MRES-32M dataset and model UniRES++ will be publicly available at https://github.com/Rubics-Xuan/MRES.
FlexVLN: Flexible Adaptation for Diverse Vision-and-Language Navigation Tasks
Mar 18, 2025



The aspiration of the Vision-and-Language Navigation (VLN) task has long been to develop an embodied agent with robust adaptability, capable of seamlessly transferring its navigation capabilities across various tasks. Despite remarkable advancements in recent years, most methods necessitate dataset-specific training, thereby lacking the capability to generalize across diverse datasets encompassing distinct types of instructions. Large language models (LLMs) have demonstrated exceptional reasoning and generalization abilities, exhibiting immense potential in robot action planning. In this paper, we propose FlexVLN, an innovative hierarchical approach to VLN that integrates the fundamental navigation ability of a supervised-learning-based Instruction Follower with the robust generalization ability of the LLM Planner, enabling effective generalization across diverse VLN datasets. Moreover, a verification mechanism and a multi-model integration mechanism are proposed to mitigate potential hallucinations by the LLM Planner and enhance execution accuracy of the Instruction Follower. We take REVERIE, SOON, and CVDN-target as out-of-domain datasets for assessing generalization ability. The generalization performance of FlexVLN surpasses that of all the previous methods to a large extent.
Efficient Motion-Aware Video MLLM
Mar 17, 2025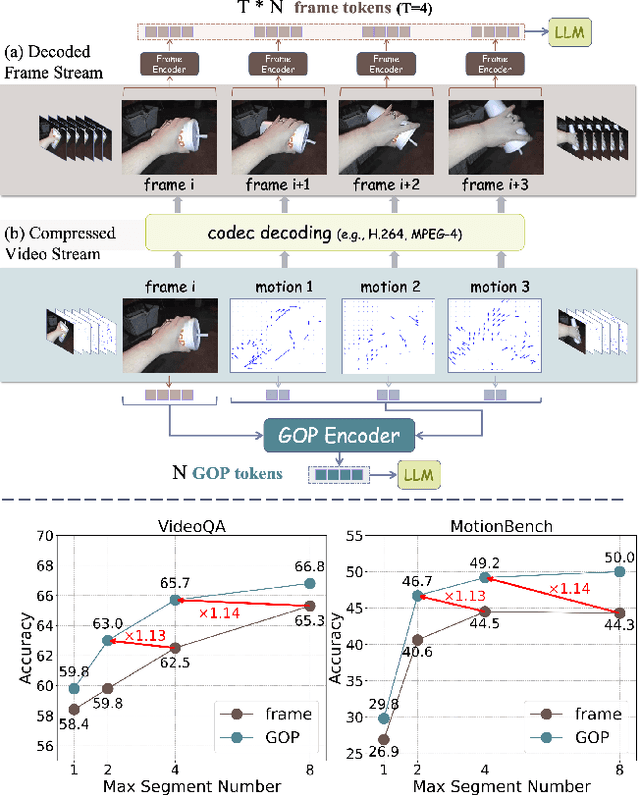
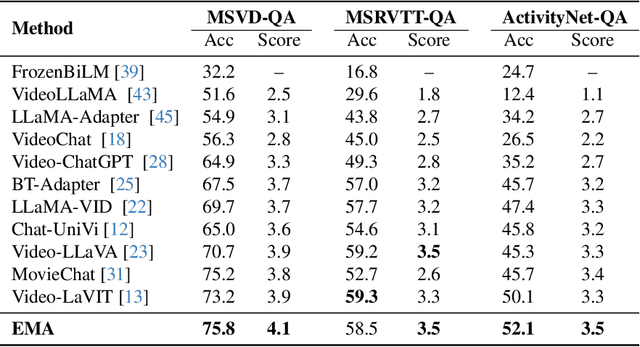
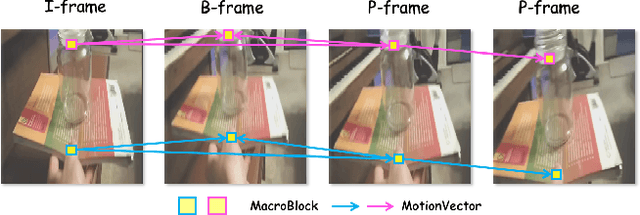
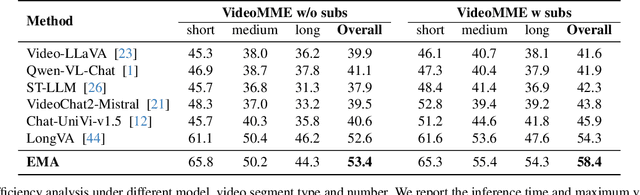
Most current video MLLMs rely on uniform frame sampling and image-level encoders, resulting in inefficient data processing and limited motion awareness. To address these challenges, we introduce EMA, an Efficient Motion-Aware video MLLM that utilizes compressed video structures as inputs. We propose a motion-aware GOP (Group of Pictures) encoder that fuses spatial and motion information within a GOP unit in the compressed video stream, generating compact, informative visual tokens. By integrating fewer but denser RGB frames with more but sparser motion vectors in this native slow-fast input architecture, our approach reduces redundancy and enhances motion representation. Additionally, we introduce MotionBench, a benchmark for evaluating motion understanding across four motion types: linear, curved, rotational, and contact-based. Experimental results show that EMA achieves state-of-the-art performance on both MotionBench and popular video question answering benchmarks, while reducing inference costs. Moreover, EMA demonstrates strong scalability, as evidenced by its competitive performance on long video understanding benchmarks.
VRoPE: Rotary Position Embedding for Video Large Language Models
Feb 17, 2025Rotary Position Embedding (RoPE) has shown strong performance in text-based Large Language Models (LLMs), but extending it to video remains a challenge due to the intricate spatiotemporal structure of video frames. Existing adaptations, such as RoPE-3D, attempt to encode spatial and temporal dimensions separately but suffer from two major limitations: positional bias in attention distribution and disruptions in video-text transitions. To overcome these issues, we propose Video Rotary Position Embedding (VRoPE), a novel positional encoding method tailored for Video-LLMs. Our approach restructures positional indices to preserve spatial coherence and ensure a smooth transition between video and text tokens. Additionally, we introduce a more balanced encoding strategy that mitigates attention biases, ensuring a more uniform distribution of spatial focus. Extensive experiments on Vicuna and Qwen2 across different model scales demonstrate that VRoPE consistently outperforms previous RoPE variants, achieving significant improvements in video understanding, temporal reasoning, and retrieval tasks. Code will be available at https://github.com/johncaged/VRoPE
ChatSearch: a Dataset and a Generative Retrieval Model for General Conversational Image Retrieval
Oct 24, 2024
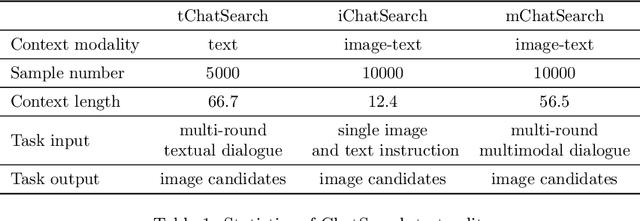
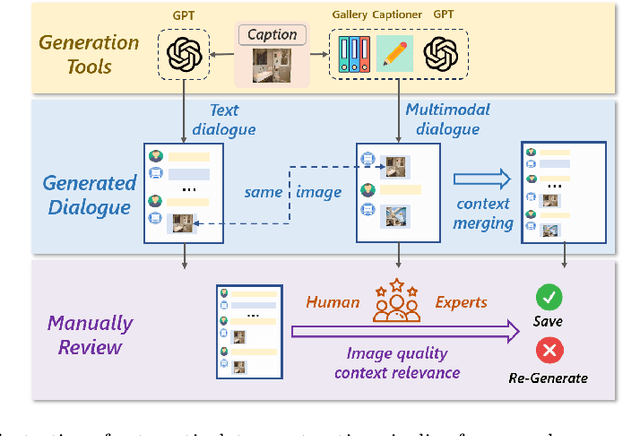
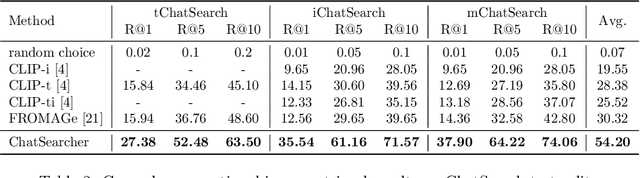
In this paper, we investigate the task of general conversational image retrieval on open-domain images. The objective is to search for images based on interactive conversations between humans and computers. To advance this task, we curate a dataset called ChatSearch. This dataset includes a multi-round multimodal conversational context query for each target image, thereby requiring the retrieval system to find the accurate image from database. Simultaneously, we propose a generative retrieval model named ChatSearcher, which is trained end-to-end to accept/produce interleaved image-text inputs/outputs. ChatSearcher exhibits strong capability in reasoning with multimodal context and can leverage world knowledge to yield visual retrieval results. It demonstrates superior performance on the ChatSearch dataset and also achieves competitive results on other image retrieval tasks and visual conversation tasks. We anticipate that this work will inspire further research on interactive multimodal retrieval systems. Our dataset will be available at https://github.com/joez17/ChatSearch.
Ada-K Routing: Boosting the Efficiency of MoE-based LLMs
Oct 15, 2024



In the era of Large Language Models (LLMs), Mixture-of-Experts (MoE) architectures offer a promising approach to managing computational costs while scaling up model parameters. Conventional MoE-based LLMs typically employ static Top-K routing, which activates a fixed and equal number of experts for each token regardless of their significance within the context. In this paper, we propose a novel Ada-K routing strategy that dynamically adjusts the number of activated experts for each token, thereby improving the balance between computational efficiency and model performance. Specifically, our strategy incorporates learnable and lightweight allocator modules that decide customized expert resource allocation tailored to the contextual needs for each token. These allocators are designed to be fully pluggable, making it broadly applicable across all mainstream MoE-based LLMs. We leverage the Proximal Policy Optimization (PPO) algorithm to facilitate an end-to-end learning process for this non-differentiable decision-making framework. Extensive evaluations on four popular baseline models demonstrate that our Ada-K routing method significantly outperforms conventional Top-K routing. Compared to Top-K, our method achieves over 25% reduction in FLOPs and more than 20% inference speedup while still improving performance across various benchmarks. Moreover, the training of Ada-K is highly efficient. Even for Mixtral-8x22B, a MoE-based LLM with more than 140B parameters, the training time is limited to 8 hours. Detailed analysis shows that harder tasks, middle layers, and content words tend to activate more experts, providing valuable insights for future adaptive MoE system designs. Both the training code and model checkpoints will be publicly available.
MM-LDM: Multi-Modal Latent Diffusion Model for Sounding Video Generation
Oct 02, 2024Sounding Video Generation (SVG) is an audio-video joint generation task challenged by high-dimensional signal spaces, distinct data formats, and different patterns of content information. To address these issues, we introduce a novel multi-modal latent diffusion model (MM-LDM) for the SVG task. We first unify the representation of audio and video data by converting them into a single or a couple of images. Then, we introduce a hierarchical multi-modal autoencoder that constructs a low-level perceptual latent space for each modality and a shared high-level semantic feature space. The former space is perceptually equivalent to the raw signal space of each modality but drastically reduces signal dimensions. The latter space serves to bridge the information gap between modalities and provides more insightful cross-modal guidance. Our proposed method achieves new state-of-the-art results with significant quality and efficiency gains. Specifically, our method achieves a comprehensive improvement on all evaluation metrics and a faster training and sampling speed on Landscape and AIST++ datasets. Moreover, we explore its performance on open-domain sounding video generation, long sounding video generation, audio continuation, video continuation, and conditional single-modal generation tasks for a comprehensive evaluation, where our MM-LDM demonstrates exciting adaptability and generalization ability.