 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
The Fourth Monocular Depth Estimation Challenge
Apr 24, 2025


This paper presents the results of the fourth edition of the Monocular Depth Estimation Challenge (MDEC), which focuses on zero-shot generalization to the SYNS-Patches benchmark, a dataset featuring challenging environments in both natural and indoor settings. In this edition, we revised the evaluation protocol to use least-squares alignment with two degrees of freedom to support disparity and affine-invariant predictions. We also revised the baselines and included popular off-the-shelf methods: Depth Anything v2 and Marigold. The challenge received a total of 24 submissions that outperformed the baselines on the test set; 10 of these included a report describing their approach, with most leading methods relying on affine-invariant predictions. The challenge winners improved the 3D F-Score over the previous edition's best result, raising it from 22.58% to 23.05%.
Adaptive Stereo Depth Estimation with Multi-Spectral Images Across All Lighting Conditions
Nov 06, 2024



Depth estimation under adverse conditions remains a significant challenge. Recently, multi-spectral depth estimation, which integrates both visible light and thermal images, has shown promise in addressing this issue. However, existing algorithms struggle with precise pixel-level feature matching, limiting their ability to fully exploit geometric constraints across different spectra. To address this, we propose a novel framework incorporating stereo depth estimation to enforce accurate geometric constraints. In particular, we treat the visible light and thermal images as a stereo pair and utilize a Cross-modal Feature Matching (CFM) Module to construct a cost volume for pixel-level matching. To mitigate the effects of poor lighting on stereo matching, we introduce Degradation Masking, which leverages robust monocular thermal depth estimation in degraded regions. Our method achieves state-of-the-art (SOTA) performance on the Multi-Spectral Stereo (MS2) dataset, with qualitative evaluations demonstrating high-quality depth maps under varying lighting conditions.
Herald: A Natural Language Annotated Lean 4 Dataset
Oct 09, 2024


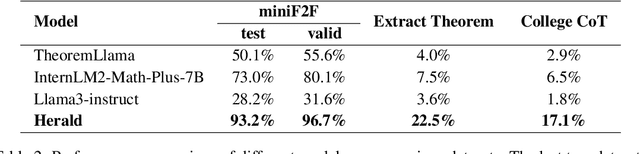
Verifiable formal languages like Lean have profoundly impacted mathematical reasoning, particularly through the use of large language models (LLMs) for automated reasoning. A significant challenge in training LLMs for these formal languages is the lack of parallel datasets that align natural language with formal language proofs. To address this challenge, this paper introduces a novel framework for translating the Mathlib4 corpus (a unified library of mathematics in formal language Lean 4) into natural language. Building upon this, we employ a dual augmentation strategy that combines tactic-based and informal-based approaches, leveraging the Lean-jixia system, a Lean 4 analyzer. We present the results of this pipeline on Mathlib4 as Herald (Hierarchy and Retrieval-based Translated Lean Dataset). We also propose the Herald Translator, which is fine-tuned on Herald. Herald translator achieves a 93.2% accuracy (Pass@128) on formalizing statements in the miniF2F-test and a 22.5% accuracy on our internal graduate-level textbook dataset, outperforming InternLM2-Math-Plus-7B (74.0% and 7.5%) and TheoremLlama (50.1% and 4.0%). Furthermore, we propose a section-level translation framework for real-world applications. As a direct application of Herald translator, we have successfully translated a template section in the Stack project, marking a notable progress in the automatic formalization of graduate-level mathematical literature. Our model, along with the datasets, will be open-sourced to the public soon.
MM-LDM: Multi-Modal Latent Diffusion Model for Sounding Video Generation
Oct 02, 2024Sounding Video Generation (SVG) is an audio-video joint generation task challenged by high-dimensional signal spaces, distinct data formats, and different patterns of content information. To address these issues, we introduce a novel multi-modal latent diffusion model (MM-LDM) for the SVG task. We first unify the representation of audio and video data by converting them into a single or a couple of images. Then, we introduce a hierarchical multi-modal autoencoder that constructs a low-level perceptual latent space for each modality and a shared high-level semantic feature space. The former space is perceptually equivalent to the raw signal space of each modality but drastically reduces signal dimensions. The latter space serves to bridge the information gap between modalities and provides more insightful cross-modal guidance. Our proposed method achieves new state-of-the-art results with significant quality and efficiency gains. Specifically, our method achieves a comprehensive improvement on all evaluation metrics and a faster training and sampling speed on Landscape and AIST++ datasets. Moreover, we explore its performance on open-domain sounding video generation, long sounding video generation, audio continuation, video continuation, and conditional single-modal generation tasks for a comprehensive evaluation, where our MM-LDM demonstrates exciting adaptability and generalization ability.
DINO-SD: Champion Solution for ICRA 2024 RoboDepth Challenge
May 27, 2024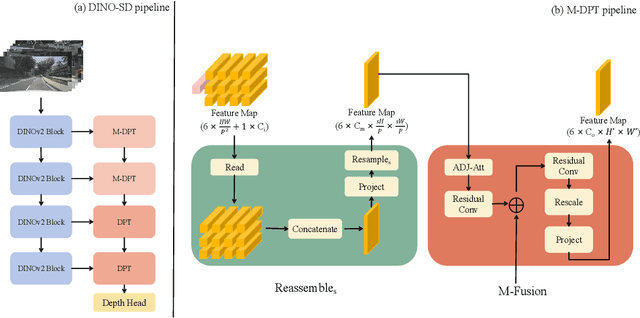

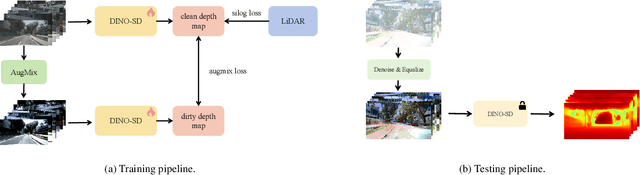
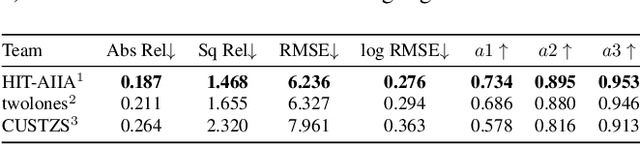
Surround-view depth estimation is a crucial task aims to acquire the depth maps of the surrounding views. It has many applications in real world scenarios such as autonomous driving, AR/VR and 3D reconstruction, etc. However, given that most of the data in the autonomous driving dataset is collected in daytime scenarios, this leads to poor depth model performance in the face of out-of-distribution(OoD) data. While some works try to improve the robustness of depth model under OoD data, these methods either require additional training data or lake generalizability. In this report, we introduce the DINO-SD, a novel surround-view depth estimation model. Our DINO-SD does not need additional data and has strong robustness. Our DINO-SD get the best performance in the track4 of ICRA 2024 RoboDepth Challenge.
The RoboDrive Challenge: Drive Anytime Anywhere in Any Condition
May 14, 2024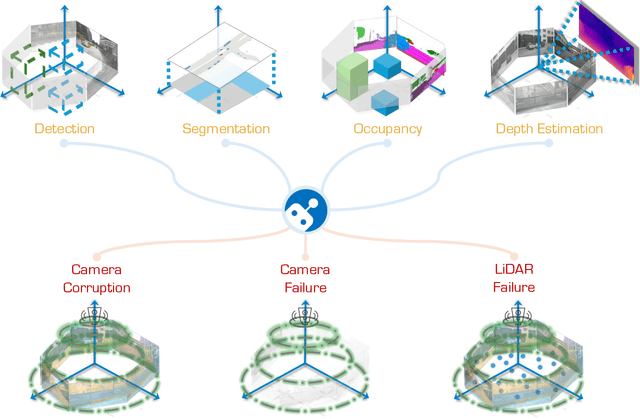


In the realm of autonomous driving, robust perception under out-of-distribution conditions is paramount for the safe deployment of vehicles. Challenges such as adverse weather, sensor malfunctions, and environmental unpredictability can severely impact the performance of autonomous systems. The 2024 RoboDrive Challenge was crafted to propel the development of driving perception technologies that can withstand and adapt to these real-world variabilities. Focusing on four pivotal tasks -- BEV detection, map segmentation, semantic occupancy prediction, and multi-view depth estimation -- the competition laid down a gauntlet to innovate and enhance system resilience against typical and atypical disturbances. This year's challenge consisted of five distinct tracks and attracted 140 registered teams from 93 institutes across 11 countries, resulting in nearly one thousand submissions evaluated through our servers. The competition culminated in 15 top-performing solutions, which introduced a range of innovative approaches including advanced data augmentation, multi-sensor fusion, self-supervised learning for error correction, and new algorithmic strategies to enhance sensor robustness. These contributions significantly advanced the state of the art, particularly in handling sensor inconsistencies and environmental variability. Participants, through collaborative efforts, pushed the boundaries of current technologies, showcasing their potential in real-world scenarios. Extensive evaluations and analyses provided insights into the effectiveness of these solutions, highlighting key trends and successful strategies for improving the resilience of driving perception systems. This challenge has set a new benchmark in the field, providing a rich repository of techniques expected to guide future research in this field.
A Semantic Search Engine for Mathlib4
Mar 20, 2024



The interactive theorem prover, Lean, enables the verification of formal mathematical proofs and is backed by an expanding community. Central to this ecosystem is its mathematical library, mathlib4, which lays the groundwork for the formalization of an expanding range of mathematical theories. However, searching for theorems in mathlib4 can be challenging. To successfully search in mathlib4, users often need to be familiar with its naming conventions or documentation strings. Therefore, creating a semantic search engine that can be used easily by individuals with varying familiarity with mathlib4 is very important. In this paper, we present a semantic search engine for mathlib4 that accepts informal queries and finds the relevant theorems. We also establish a benchmark for assessing the performance of various search engines for mathlib4.
GLOBER: Coherent Non-autoregressive Video Generation via GLOBal Guided Video DecodER
Sep 23, 2023Video generation necessitates both global coherence and local realism. This work presents a novel non-autoregressive method GLOBER, which first generates global features to obtain comprehensive global guidance and then synthesizes video frames based on the global features to generate coherent videos. Specifically, we propose a video auto-encoder, where a video encoder encodes videos into global features, and a video decoder, built on a diffusion model, decodes the global features and synthesizes video frames in a non-autoregressive manner. To achieve maximum flexibility, our video decoder perceives temporal information through normalized frame indexes, which enables it to synthesize arbitrary sub video clips with predetermined starting and ending frame indexes. Moreover, a novel adversarial loss is introduced to improve the global coherence and local realism between the synthesized video frames. Finally, we employ a diffusion-based video generator to fit the global features outputted by the video encoder for video generation. Extensive experimental results demonstrate the effectiveness and efficiency of our proposed method, and new state-of-the-art results have been achieved on multiple benchmarks.