 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken Entropy Regularization for Multi-modal Antenna Affiliation Identification
Jan 29, 2026Accurate antenna affiliation identification is crucial for optimizing and maintaining communication networks. Current practice, however, relies on the cumbersome and error-prone process of manual tower inspections. We propose a novel paradigm shift that fuses video footage of base stations, antenna geometric features, and Physical Cell Identity (PCI) signals, transforming antenna affiliation identification into multi-modal classification and matching tasks. Publicly available pretrained transformers struggle with this unique task due to a lack of analogous data in the communications domain, which hampers cross-modal alignment. To address this, we introduce a dedicated training framework that aligns antenna images with corresponding PCI signals. To tackle the representation alignment challenge, we propose a novel Token Entropy Regularization module in the pretraining stage. Our experiments demonstrate that TER accelerates convergence and yields significant performance gains. Further analysis reveals that the entropy of the first token is modality-dependent. Code will be made available upon publication.
The Fourth Monocular Depth Estimation Challenge
Apr 24, 2025


This paper presents the results of the fourth edition of the Monocular Depth Estimation Challenge (MDEC), which focuses on zero-shot generalization to the SYNS-Patches benchmark, a dataset featuring challenging environments in both natural and indoor settings. In this edition, we revised the evaluation protocol to use least-squares alignment with two degrees of freedom to support disparity and affine-invariant predictions. We also revised the baselines and included popular off-the-shelf methods: Depth Anything v2 and Marigold. The challenge received a total of 24 submissions that outperformed the baselines on the test set; 10 of these included a report describing their approach, with most leading methods relying on affine-invariant predictions. The challenge winners improved the 3D F-Score over the previous edition's best result, raising it from 22.58% to 23.05%.
Adaptive Stereo Depth Estimation with Multi-Spectral Images Across All Lighting Conditions
Nov 06, 2024



Depth estimation under adverse conditions remains a significant challenge. Recently, multi-spectral depth estimation, which integrates both visible light and thermal images, has shown promise in addressing this issue. However, existing algorithms struggle with precise pixel-level feature matching, limiting their ability to fully exploit geometric constraints across different spectra. To address this, we propose a novel framework incorporating stereo depth estimation to enforce accurate geometric constraints. In particular, we treat the visible light and thermal images as a stereo pair and utilize a Cross-modal Feature Matching (CFM) Module to construct a cost volume for pixel-level matching. To mitigate the effects of poor lighting on stereo matching, we introduce Degradation Masking, which leverages robust monocular thermal depth estimation in degraded regions. Our method achieves state-of-the-art (SOTA) performance on the Multi-Spectral Stereo (MS2) dataset, with qualitative evaluations demonstrating high-quality depth maps under varying lighting conditions.
DINO-SD: Champion Solution for ICRA 2024 RoboDepth Challenge
May 27, 2024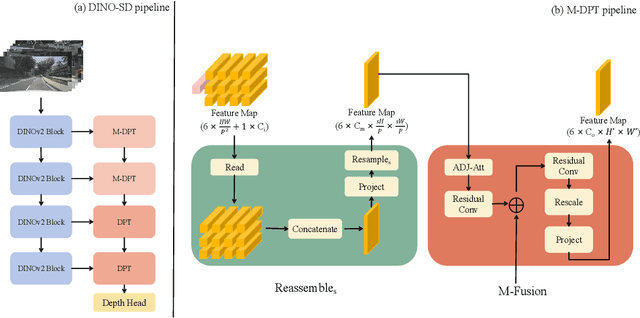

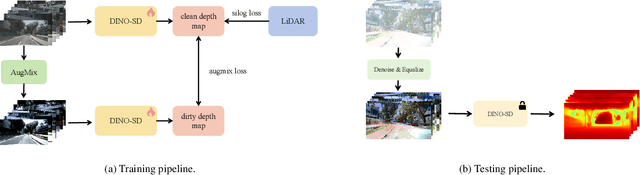
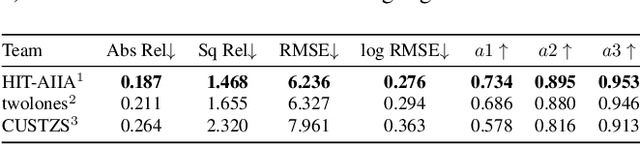
Surround-view depth estimation is a crucial task aims to acquire the depth maps of the surrounding views. It has many applications in real world scenarios such as autonomous driving, AR/VR and 3D reconstruction, etc. However, given that most of the data in the autonomous driving dataset is collected in daytime scenarios, this leads to poor depth model performance in the face of out-of-distribution(OoD) data. While some works try to improve the robustness of depth model under OoD data, these methods either require additional training data or lake generalizability. In this report, we introduce the DINO-SD, a novel surround-view depth estimation model. Our DINO-SD does not need additional data and has strong robustness. Our DINO-SD get the best performance in the track4 of ICRA 2024 RoboDepth Challenge.
The RoboDrive Challenge: Drive Anytime Anywhere in Any Condition
May 14, 2024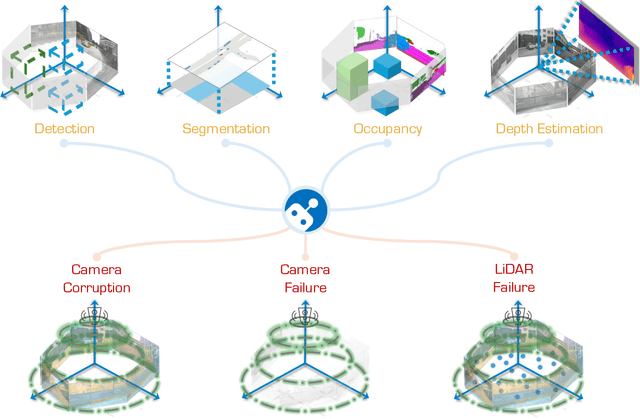


In the realm of autonomous driving, robust perception under out-of-distribution conditions is paramount for the safe deployment of vehicles. Challenges such as adverse weather, sensor malfunctions, and environmental unpredictability can severely impact the performance of autonomous systems. The 2024 RoboDrive Challenge was crafted to propel the development of driving perception technologies that can withstand and adapt to these real-world variabilities. Focusing on four pivotal tasks -- BEV detection, map segmentation, semantic occupancy prediction, and multi-view depth estimation -- the competition laid down a gauntlet to innovate and enhance system resilience against typical and atypical disturbances. This year's challenge consisted of five distinct tracks and attracted 140 registered teams from 93 institutes across 11 countries, resulting in nearly one thousand submissions evaluated through our servers. The competition culminated in 15 top-performing solutions, which introduced a range of innovative approaches including advanced data augmentation, multi-sensor fusion, self-supervised learning for error correction, and new algorithmic strategies to enhance sensor robustness. These contributions significantly advanced the state of the art, particularly in handling sensor inconsistencies and environmental variability. Participants, through collaborative efforts, pushed the boundaries of current technologies, showcasing their potential in real-world scenarios. Extensive evaluations and analyses provided insights into the effectiveness of these solutions, highlighting key trends and successful strategies for improving the resilience of driving perception systems. This challenge has set a new benchmark in the field, providing a rich repository of techniques expected to guide future research in this field.
SDGE: Stereo Guided Depth Estimation for 360$^\circ$ Camera Sets
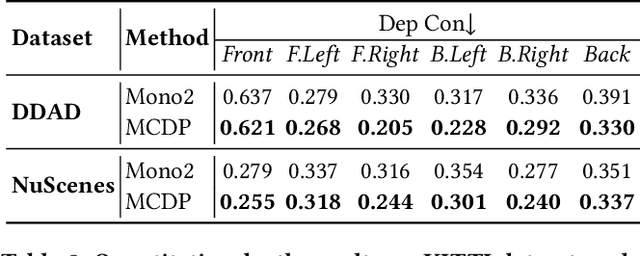
Feb 29, 2024Depth estimation is a critical technology in autonomous driving, and multi-camera systems are often used to achieve a 360$^\circ$ perception. These 360$^\circ$ camera sets often have limited or low-quality overlap regions, making multi-view stereo methods infeasible for the entire image. Alternatively, monocular methods may not produce consistent cross-view predictions. To address these issues, we propose the Stereo Guided Depth Estimation (SGDE) method, which enhances depth estimation of the full image by explicitly utilizing multi-view stereo results on the overlap. We suggest building virtual pinhole cameras to resolve the distortion problem of fisheye cameras and unify the processing for the two types of 360$^\circ$ cameras. For handling the varying noise on camera poses caused by unstable movement, the approach employs a self-calibration method to obtain highly accurate relative poses of the adjacent cameras with minor overlap. These enable the use of robust stereo methods to obtain high-quality depth prior in the overlap region. This prior serves not only as an additional input but also as pseudo-labels that enhance the accuracy of depth estimation methods and improve cross-view prediction consistency. The effectiveness of SGDE is evaluated on one fisheye camera dataset, Synthetic Urban, and two pinhole camera datasets, DDAD and nuScenes. Our experiments demonstrate that SGDE is effective for both supervised and self-supervised depth estimation, and highlight the potential of our method for advancing downstream autonomous driving technologies, such as 3D object detection and occupancy prediction.
Unveiling the Depths: A Multi-Modal Fusion Framework for Challenging Scenarios
Feb 19, 2024



Monocular depth estimation from RGB images plays a pivotal role in 3D vision. However, its accuracy can deteriorate in challenging environments such as nighttime or adverse weather conditions. While long-wave infrared cameras offer stable imaging in such challenging conditions, they are inherently low-resolution, lacking rich texture and semantics as delivered by the RGB image. Current methods focus solely on a single modality due to the difficulties to identify and integrate faithful depth cues from both sources. To address these issues, this paper presents a novel approach that identifies and integrates dominant cross-modality depth features with a learning-based framework. Concretely, we independently compute the coarse depth maps with separate networks by fully utilizing the individual depth cues from each modality. As the advantageous depth spreads across both modalities, we propose a novel confidence loss steering a confidence predictor network to yield a confidence map specifying latent potential depth areas. With the resulting confidence map, we propose a multi-modal fusion network that fuses the final depth in an end-to-end manner. Harnessing the proposed pipeline, our method demonstrates the ability of robust depth estimation in a variety of difficult scenarios. Experimental results on the challenging MS$^2$ and ViViD++ datasets demonstrate the effectiveness and robustness of our method.
Efficient Single-Image Depth Estimation on Mobile Devices, Mobile AI & AIM 2022 Challenge: Report
Nov 07, 2022

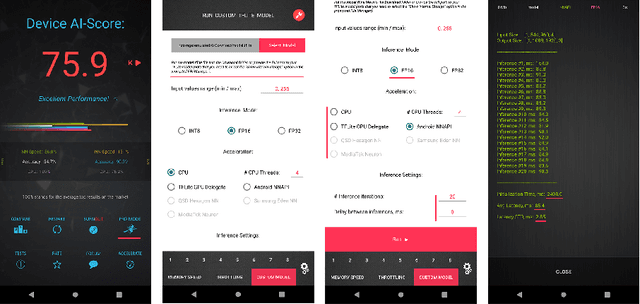
Various depth estimation models are now widely used on many mobile and IoT devices for image segmentation, bokeh effect rendering, object tracking and many other mobile tasks. Thus, it is very crucial to have efficient and accurate depth estimation models that can run fast on low-power mobile chipsets. In this Mobile AI challenge, the target was to develop deep learning-based single image depth estimation solutions that can show a real-time performance on IoT platforms and smartphones. For this, the participants used a large-scale RGB-to-depth dataset that was collected with the ZED stereo camera capable to generated depth maps for objects located at up to 50 meters. The runtime of all models was evaluated on the Raspberry Pi 4 platform, where the developed solutions were able to generate VGA resolution depth maps at up to 27 FPS while achieving high fidelity results. All models developed in the challenge are also compatible with any Android or Linux-based mobile devices, their detailed description is provided in this paper.
Multi-Camera Collaborative Depth Prediction via Consistent Structure Estimation
Oct 05, 2022


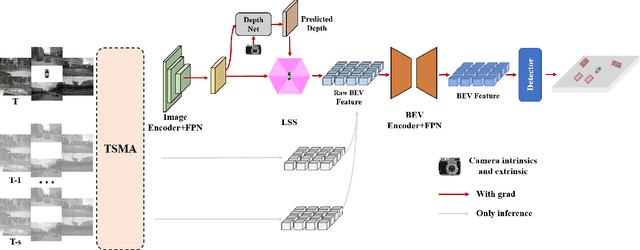
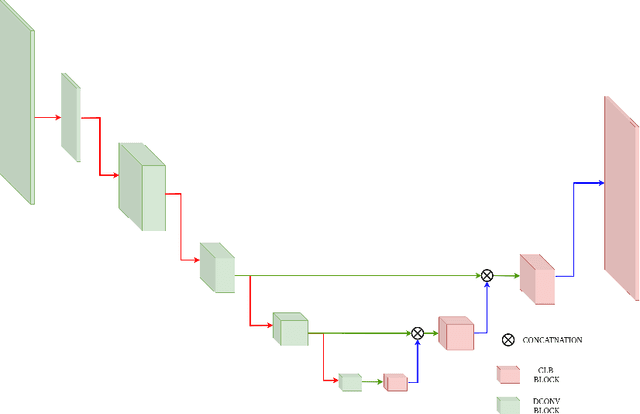
Depth map estimation from images is an important task in robotic systems. Existing methods can be categorized into two groups including multi-view stereo and monocular depth estimation. The former requires cameras to have large overlapping areas and sufficient baseline between cameras, while the latter that processes each image independently can hardly guarantee the structure consistency between cameras. In this paper, we propose a novel multi-camera collaborative depth prediction method that does not require large overlapping areas while maintaining structure consistency between cameras. Specifically, we formulate the depth estimation as a weighted combination of depth basis, in which the weights are updated iteratively by a refinement network driven by the proposed consistency loss. During the iterative update, the results of depth estimation are compared across cameras and the information of overlapping areas is propagated to the whole depth maps with the help of basis formulation. Experimental results on DDAD and NuScenes datasets demonstrate the superior performance of our method.
LiteDepth: Digging into Fast and Accurate Depth Estimation on Mobile Devices
Sep 02, 2022
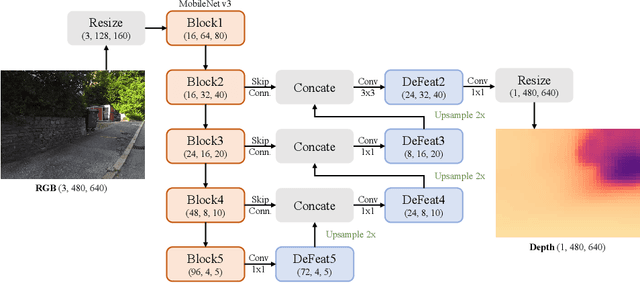


Monocular depth estimation is an essential task in the computer vision community. While tremendous successful methods have obtained excellent results, most of them are computationally expensive and not applicable for real-time on-device inference. In this paper, we aim to address more practical applications of monocular depth estimation, where the solution should consider not only the precision but also the inference time on mobile devices. To this end, we first develop an end-to-end learning-based model with a tiny weight size (1.4MB) and a short inference time (27FPS on Raspberry Pi 4). Then, we propose a simple yet effective data augmentation strategy, called R2 crop, to boost the model performance. Moreover, we observe that the simple lightweight model trained with only one single loss term will suffer from performance bottleneck. To alleviate this issue, we adopt multiple loss terms to provide sufficient constraints during the training stage. Furthermore, with a simple dynamic re-weight strategy, we can avoid the time-consuming hyper-parameter choice of loss terms. Finally, we adopt the structure-aware distillation to further improve the model performance. Notably, our solution named LiteDepth ranks 2nd in the MAI&AIM2022 Monocular Depth Estimation Challenge}, with a si-RMSE of 0.311, an RMSE of 3.79, and the inference time is 37$ms$ tested on the Raspberry Pi 4. Notably, we provide the fastest solution to the challenge. Codes and models will be released at \url{https://github.com/zhyever/LiteDepth}.