 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning better representations for crowded pedestrians in offboard LiDAR-camera 3D tracking-by-detection
May 21, 2025Perceiving pedestrians in highly crowded urban environments is a difficult long-tail problem for learning-based autonomous perception. Speeding up 3D ground truth generation for such challenging scenes is performance-critical yet very challenging. The difficulties include the sparsity of the captured pedestrian point cloud and a lack of suitable benchmarks for a specific system design study. To tackle the challenges, we first collect a new multi-view LiDAR-camera 3D multiple-object-tracking benchmark of highly crowded pedestrians for in-depth analysis. We then build an offboard auto-labeling system that reconstructs pedestrian trajectories from LiDAR point cloud and multi-view images. To improve the generalization power for crowded scenes and the performance for small objects, we propose to learn high-resolution representations that are density-aware and relationship-aware. Extensive experiments validate that our approach significantly improves the 3D pedestrian tracking performance towards higher auto-labeling efficiency. The code will be publicly available at this HTTP URL.
Adaptive Fusion of Single-View and Multi-View Depth for Autonomous Driving
Mar 12, 2024Multi-view depth estimation has achieved impressive performance over various benchmarks. However, almost all current multi-view systems rely on given ideal camera poses, which are unavailable in many real-world scenarios, such as autonomous driving. In this work, we propose a new robustness benchmark to evaluate the depth estimation system under various noisy pose settings. Surprisingly, we find current multi-view depth estimation methods or single-view and multi-view fusion methods will fail when given noisy pose settings. To address this challenge, we propose a single-view and multi-view fused depth estimation system, which adaptively integrates high-confident multi-view and single-view results for both robust and accurate depth estimations. The adaptive fusion module performs fusion by dynamically selecting high-confidence regions between two branches based on a wrapping confidence map. Thus, the system tends to choose the more reliable branch when facing textureless scenes, inaccurate calibration, dynamic objects, and other degradation or challenging conditions. Our method outperforms state-of-the-art multi-view and fusion methods under robustness testing. Furthermore, we achieve state-of-the-art performance on challenging benchmarks (KITTI and DDAD) when given accurate pose estimations. Project website: https://github.com/Junda24/AFNet/.
GIM: Learning Generalizable Image Matcher From Internet Videos
Feb 16, 2024



Image matching is a fundamental computer vision problem. While learning-based methods achieve state-of-the-art performance on existing benchmarks, they generalize poorly to in-the-wild images. Such methods typically need to train separate models for different scene types and are impractical when the scene type is unknown in advance. One of the underlying problems is the limited scalability of existing data construction pipelines, which limits the diversity of standard image matching datasets. To address this problem, we propose GIM, a self-training framework for learning a single generalizable model based on any image matching architecture using internet videos, an abundant and diverse data source. Given an architecture, GIM first trains it on standard domain-specific datasets and then combines it with complementary matching methods to create dense labels on nearby frames of novel videos. These labels are filtered by robust fitting, and then enhanced by propagating them to distant frames. The final model is trained on propagated data with strong augmentations. We also propose ZEB, the first zero-shot evaluation benchmark for image matching. By mixing data from diverse domains, ZEB can thoroughly assess the cross-domain generalization performance of different methods. Applying GIM consistently improves the zero-shot performance of 3 state-of-the-art image matching architectures; with 50 hours of YouTube videos, the relative zero-shot performance improves by 8.4%-18.1%. GIM also enables generalization to extreme cross-domain data such as Bird Eye View (BEV) images of projected 3D point clouds (Fig. 1(c)). More importantly, our single zero-shot model consistently outperforms domain-specific baselines when evaluated on downstream tasks inherent to their respective domains. The video presentation is available at https://www.youtube.com/watch?v=FU_MJLD8LeY.
UC-NeRF: Neural Radiance Field for Under-Calibrated multi-view cameras in autonomous driving
Nov 28, 2023Multi-camera setups find widespread use across various applications, such as autonomous driving, as they greatly expand sensing capabilities. Despite the fast development of Neural radiance field (NeRF) techniques and their wide applications in both indoor and outdoor scenes, applying NeRF to multi-camera systems remains very challenging. This is primarily due to the inherent under-calibration issues in multi-camera setup, including inconsistent imaging effects stemming from separately calibrated image signal processing units in diverse cameras, and system errors arising from mechanical vibrations during driving that affect relative camera poses. In this paper, we present UC-NeRF, a novel method tailored for novel view synthesis in under-calibrated multi-view camera systems. Firstly, we propose a layer-based color correction to rectify the color inconsistency in different image regions. Second, we propose virtual warping to generate more viewpoint-diverse but color-consistent virtual views for color correction and 3D recovery. Finally, a spatiotemporally constrained pose refinement is designed for more robust and accurate pose calibration in multi-camera systems. Our method not only achieves state-of-the-art performance of novel view synthesis in multi-camera setups, but also effectively facilitates depth estimation in large-scale outdoor scenes with the synthesized novel views.
Metric3D: Towards Zero-shot Metric 3D Prediction from A Single Image
Jul 20, 2023



Reconstructing accurate 3D scenes from images is a long-standing vision task. Due to the ill-posedness of the single-image reconstruction problem, most well-established methods are built upon multi-view geometry. State-of-the-art (SOTA) monocular metric depth estimation methods can only handle a single camera model and are unable to perform mixed-data training due to the metric ambiguity. Meanwhile, SOTA monocular methods trained on large mixed datasets achieve zero-shot generalization by learning affine-invariant depths, which cannot recover real-world metrics. In this work, we show that the key to a zero-shot single-view metric depth model lies in the combination of large-scale data training and resolving the metric ambiguity from various camera models. We propose a canonical camera space transformation module, which explicitly addresses the ambiguity problems and can be effortlessly plugged into existing monocular models. Equipped with our module, monocular models can be stably trained with over 8 million images with thousands of camera models, resulting in zero-shot generalization to in-the-wild images with unseen camera settings. Experiments demonstrate SOTA performance of our method on 7 zero-shot benchmarks. Notably, our method won the championship in the 2nd Monocular Depth Estimation Challenge. Our method enables the accurate recovery of metric 3D structures on randomly collected internet images, paving the way for plausible single-image metrology. The potential benefits extend to downstream tasks, which can be significantly improved by simply plugging in our model. For example, our model relieves the scale drift issues of monocular-SLAM (Fig. 1), leading to high-quality metric scale dense mapping. The code is available at https://github.com/YvanYin/Metric3D.
The Second Monocular Depth Estimation Challenge
Apr 26, 2023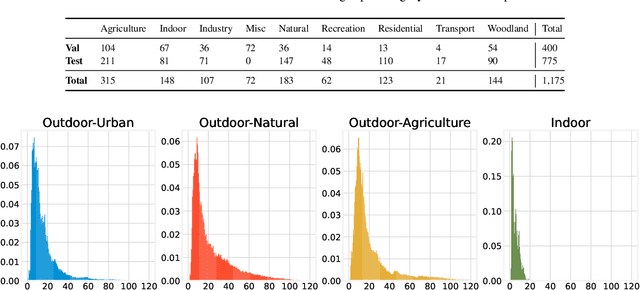
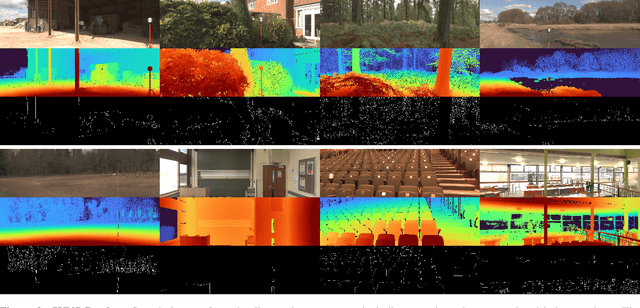
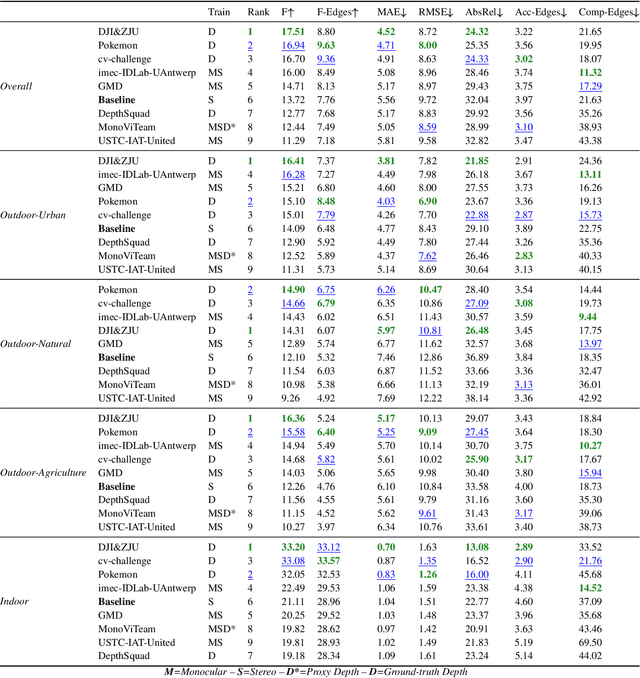
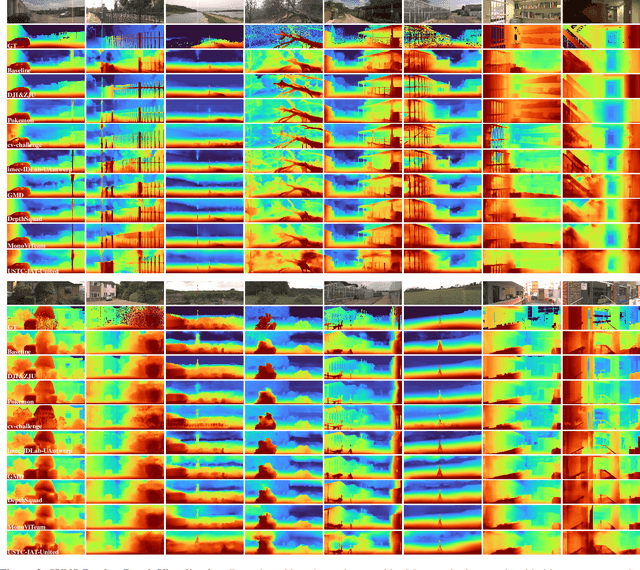
This paper discusses the results for the second edition of the Monocular Depth Estimation Challenge (MDEC). This edition was open to methods using any form of supervision, including fully-supervised, self-supervised, multi-task or proxy depth. The challenge was based around the SYNS-Patches dataset, which features a wide diversity of environments with high-quality dense ground-truth. This includes complex natural environments, e.g. forests or fields, which are greatly underrepresented in current benchmarks. The challenge received eight unique submissions that outperformed the provided SotA baseline on any of the pointcloud- or image-based metrics. The top supervised submission improved relative F-Score by 27.62%, while the top self-supervised improved it by 16.61%. Supervised submissions generally leveraged large collections of datasets to improve data diversity. Self-supervised submissions instead updated the network architecture and pretrained backbones. These results represent a significant progress in the field, while highlighting avenues for future research, such as reducing interpolation artifacts at depth boundaries, improving self-supervised indoor performance and overall natural image accuracy.
Learning to Fuse Monocular and Multi-view Cues for Multi-frame Depth Estimation in Dynamic Scenes
Apr 18, 2023Multi-frame depth estimation generally achieves high accuracy relying on the multi-view geometric consistency. When applied in dynamic scenes, e.g., autonomous driving, this consistency is usually violated in the dynamic areas, leading to corrupted estimations. Many multi-frame methods handle dynamic areas by identifying them with explicit masks and compensating the multi-view cues with monocular cues represented as local monocular depth or features. The improvements are limited due to the uncontrolled quality of the masks and the underutilized benefits of the fusion of the two types of cues. In this paper, we propose a novel method to learn to fuse the multi-view and monocular cues encoded as volumes without needing the heuristically crafted masks. As unveiled in our analyses, the multi-view cues capture more accurate geometric information in static areas, and the monocular cues capture more useful contexts in dynamic areas. To let the geometric perception learned from multi-view cues in static areas propagate to the monocular representation in dynamic areas and let monocular cues enhance the representation of multi-view cost volume, we propose a cross-cue fusion (CCF) module, which includes the cross-cue attention (CCA) to encode the spatially non-local relative intra-relations from each source to enhance the representation of the other. Experiments on real-world datasets prove the significant effectiveness and generalization ability of the proposed method.
Are All Point Clouds Suitable for Completion? Weakly Supervised Quality Evaluation Network for Point Cloud Completion
Mar 03, 2023In the practical application of point cloud completion tasks, real data quality is usually much worse than the CAD datasets used for training. A small amount of noisy data will usually significantly impact the overall system's accuracy. In this paper, we propose a quality evaluation network to score the point clouds and help judge the quality of the point cloud before applying the completion model. We believe our scoring method can help researchers select more appropriate point clouds for subsequent completion and reconstruction and avoid manual parameter adjustment. Moreover, our evaluation model is fast and straightforward and can be directly inserted into any model's training or use process to facilitate the automatic selection and post-processing of point clouds. We propose a complete dataset construction and model evaluation method based on ShapeNet. We verify our network using detection and flow estimation tasks on KITTI, a real-world dataset for autonomous driving. The experimental results show that our model can effectively distinguish the quality of point clouds and help in practical tasks.
You Only Label Once: 3D Box Adaptation from Point Cloud to Image via Semi-Supervised Learning
Nov 17, 2022The image-based 3D object detection task expects that the predicted 3D bounding box has a ``tightness'' projection (also referred to as cuboid), which fits the object contour well on the image while still keeping the geometric attribute on the 3D space, e.g., physical dimension, pairwise orthogonal, etc. These requirements bring significant challenges to the annotation. Simply projecting the Lidar-labeled 3D boxes to the image leads to non-trivial misalignment, while directly drawing a cuboid on the image cannot access the original 3D information. In this work, we propose a learning-based 3D box adaptation approach that automatically adjusts minimum parameters of the 360$^{\circ}$ Lidar 3D bounding box to perfectly fit the image appearance of panoramic cameras. With only a few 2D boxes annotation as guidance during the training phase, our network can produce accurate image-level cuboid annotations with 3D properties from Lidar boxes. We call our method ``you only label once'', which means labeling on the point cloud once and automatically adapting to all surrounding cameras. As far as we know, we are the first to focus on image-level cuboid refinement, which balances the accuracy and efficiency well and dramatically reduces the labeling effort for accurate cuboid annotation. Extensive experiments on the public Waymo and NuScenes datasets show that our method can produce human-level cuboid annotation on the image without needing manual adjustment.
Multi-Camera Collaborative Depth Prediction via Consistent Structure Estimation
Oct 05, 2022


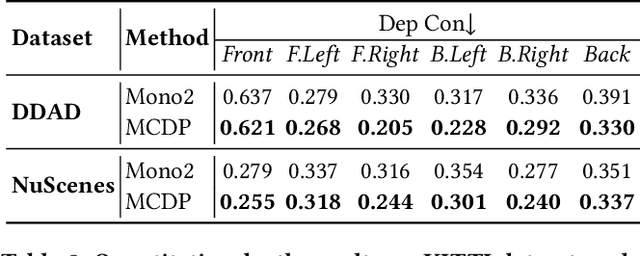
Depth map estimation from images is an important task in robotic systems. Existing methods can be categorized into two groups including multi-view stereo and monocular depth estimation. The former requires cameras to have large overlapping areas and sufficient baseline between cameras, while the latter that processes each image independently can hardly guarantee the structure consistency between cameras. In this paper, we propose a novel multi-camera collaborative depth prediction method that does not require large overlapping areas while maintaining structure consistency between cameras. Specifically, we formulate the depth estimation as a weighted combination of depth basis, in which the weights are updated iteratively by a refinement network driven by the proposed consistency loss. During the iterative update, the results of depth estimation are compared across cameras and the information of overlapping areas is propagated to the whole depth maps with the help of basis formulation. Experimental results on DDAD and NuScenes datasets demonstrate the superior performance of our method.