 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Multi-Focus Image Fusion
Dec 25, 2025



Multi-focus image fusion aims to generate an all-in-focus image from a sequence of partially focused input images. Existing fusion algorithms generally assume that, for every spatial location in the scene, there is at least one input image in which that location is in focus. Furthermore, current fusion models often suffer from edge artifacts caused by uncertain focus estimation or hard-selection operations in complex real-world scenarios. To address these limitations, we propose a generative multi-focus image fusion framework, termed GMFF, which operates in two sequential stages. In the first stage, deterministic fusion is implemented using StackMFF V4, the latest version of the StackMFF series, and integrates the available focal plane information to produce an initial fused image. The second stage, generative restoration, is realized through IFControlNet, which leverages the generative capabilities of latent diffusion models to reconstruct content from missing focal planes, restore fine details, and eliminate edge artifacts. Each stage is independently developed and functions seamlessly in a cascaded manner. Extensive experiments demonstrate that GMFF achieves state-of-the-art fusion performance and exhibits significant potential for practical applications, particularly in scenarios involving complex multi-focal content. The implementation is publicly available at https://github.com/Xinzhe99/StackMFF-Series.
Learning better representations for crowded pedestrians in offboard LiDAR-camera 3D tracking-by-detection
May 21, 2025Perceiving pedestrians in highly crowded urban environments is a difficult long-tail problem for learning-based autonomous perception. Speeding up 3D ground truth generation for such challenging scenes is performance-critical yet very challenging. The difficulties include the sparsity of the captured pedestrian point cloud and a lack of suitable benchmarks for a specific system design study. To tackle the challenges, we first collect a new multi-view LiDAR-camera 3D multiple-object-tracking benchmark of highly crowded pedestrians for in-depth analysis. We then build an offboard auto-labeling system that reconstructs pedestrian trajectories from LiDAR point cloud and multi-view images. To improve the generalization power for crowded scenes and the performance for small objects, we propose to learn high-resolution representations that are density-aware and relationship-aware. Extensive experiments validate that our approach significantly improves the 3D pedestrian tracking performance towards higher auto-labeling efficiency. The code will be publicly available at this HTTP URL.
SEPT: Standard-Definition Map Enhanced Scene Perception and Topology Reasoning for Autonomous Driving
May 18, 2025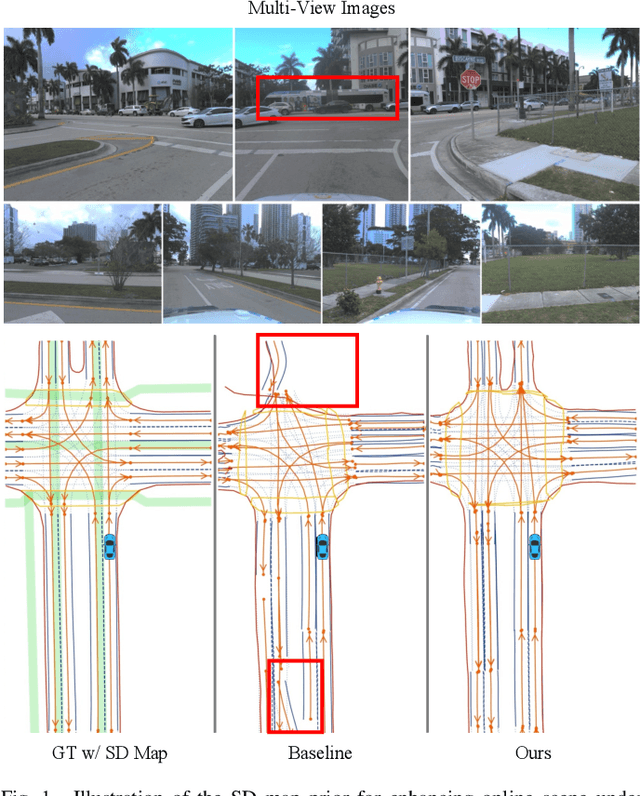
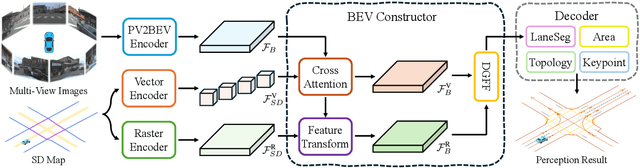
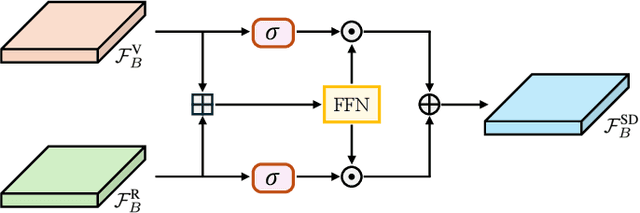
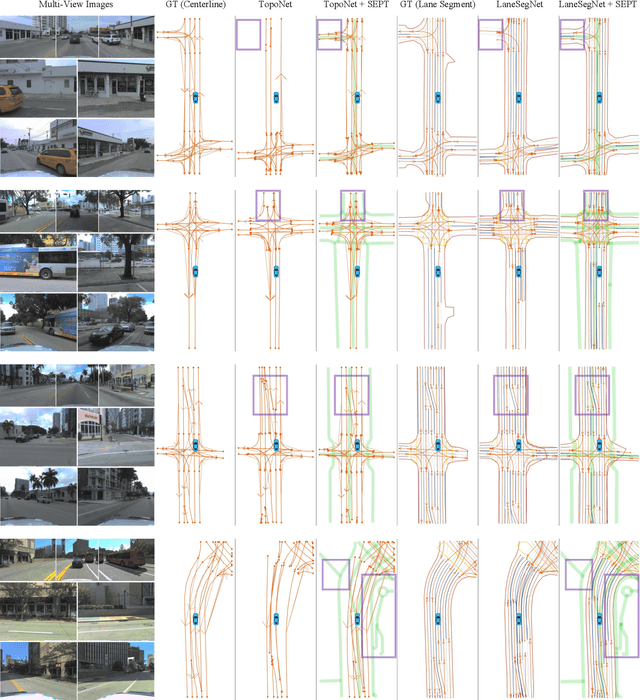
Online scene perception and topology reasoning are critical for autonomous vehicles to understand their driving environments, particularly for mapless driving systems that endeavor to reduce reliance on costly High-Definition (HD) maps. However, recent advances in online scene understanding still face limitations, especially in long-range or occluded scenarios, due to the inherent constraints of onboard sensors. To address this challenge, we propose a Standard-Definition (SD) Map Enhanced scene Perception and Topology reasoning (SEPT) framework, which explores how to effectively incorporate the SD map as prior knowledge into existing perception and reasoning pipelines. Specifically, we introduce a novel hybrid feature fusion strategy that combines SD maps with Bird's-Eye-View (BEV) features, considering both rasterized and vectorized representations, while mitigating potential misalignment between SD maps and BEV feature spaces. Additionally, we leverage the SD map characteristics to design an auxiliary intersection-aware keypoint detection task, which further enhances the overall scene understanding performance. Experimental results on the large-scale OpenLane-V2 dataset demonstrate that by effectively integrating SD map priors, our framework significantly improves both scene perception and topology reasoning, outperforming existing methods by a substantial margin.
SIMPL: A Simple and Efficient Multi-agent Motion Prediction Baseline for Autonomous Driving
Feb 04, 2024This paper presents a Simple and effIcient Motion Prediction baseLine (SIMPL) for autonomous vehicles. Unlike conventional agent-centric methods with high accuracy but repetitive computations and scene-centric methods with compromised accuracy and generalizability, SIMPL delivers real-time, accurate motion predictions for all relevant traffic participants. To achieve improvements in both accuracy and inference speed, we propose a compact and efficient global feature fusion module that performs directed message passing in a symmetric manner, enabling the network to forecast future motion for all road users in a single feed-forward pass and mitigating accuracy loss caused by viewpoint shifting. Additionally, we investigate the continuous trajectory parameterization using Bernstein basis polynomials in trajectory decoding, allowing evaluations of states and their higher-order derivatives at any desired time point, which is valuable for downstream planning tasks. As a strong baseline, SIMPL exhibits highly competitive performance on Argoverse 1 & 2 motion forecasting benchmarks compared with other state-of-the-art methods. Furthermore, its lightweight design and low inference latency make SIMPL highly extensible and promising for real-world onboard deployment. We open-source the code at https://github.com/HKUST-Aerial-Robotics/SIMPL.
Are All Point Clouds Suitable for Completion? Weakly Supervised Quality Evaluation Network for Point Cloud Completion
Mar 03, 2023In the practical application of point cloud completion tasks, real data quality is usually much worse than the CAD datasets used for training. A small amount of noisy data will usually significantly impact the overall system's accuracy. In this paper, we propose a quality evaluation network to score the point clouds and help judge the quality of the point cloud before applying the completion model. We believe our scoring method can help researchers select more appropriate point clouds for subsequent completion and reconstruction and avoid manual parameter adjustment. Moreover, our evaluation model is fast and straightforward and can be directly inserted into any model's training or use process to facilitate the automatic selection and post-processing of point clouds. We propose a complete dataset construction and model evaluation method based on ShapeNet. We verify our network using detection and flow estimation tasks on KITTI, a real-world dataset for autonomous driving. The experimental results show that our model can effectively distinguish the quality of point clouds and help in practical tasks.
You Only Label Once: 3D Box Adaptation from Point Cloud to Image via Semi-Supervised Learning
Nov 17, 2022The image-based 3D object detection task expects that the predicted 3D bounding box has a ``tightness'' projection (also referred to as cuboid), which fits the object contour well on the image while still keeping the geometric attribute on the 3D space, e.g., physical dimension, pairwise orthogonal, etc. These requirements bring significant challenges to the annotation. Simply projecting the Lidar-labeled 3D boxes to the image leads to non-trivial misalignment, while directly drawing a cuboid on the image cannot access the original 3D information. In this work, we propose a learning-based 3D box adaptation approach that automatically adjusts minimum parameters of the 360$^{\circ}$ Lidar 3D bounding box to perfectly fit the image appearance of panoramic cameras. With only a few 2D boxes annotation as guidance during the training phase, our network can produce accurate image-level cuboid annotations with 3D properties from Lidar boxes. We call our method ``you only label once'', which means labeling on the point cloud once and automatically adapting to all surrounding cameras. As far as we know, we are the first to focus on image-level cuboid refinement, which balances the accuracy and efficiency well and dramatically reduces the labeling effort for accurate cuboid annotation. Extensive experiments on the public Waymo and NuScenes datasets show that our method can produce human-level cuboid annotation on the image without needing manual adjustment.
MonoJSG: Joint Semantic and Geometric Cost Volume for Monocular 3D Object Detection
Mar 16, 2022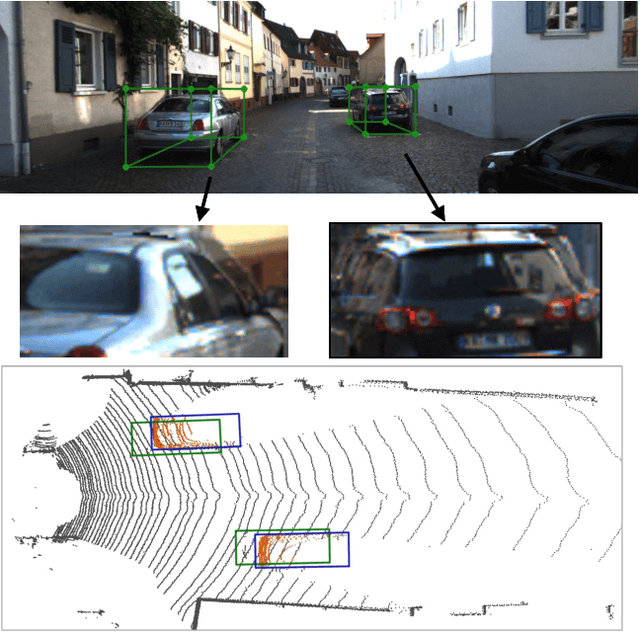
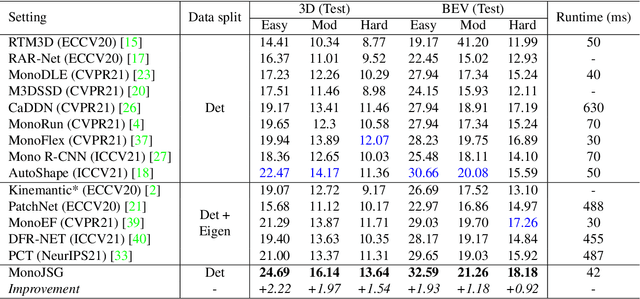
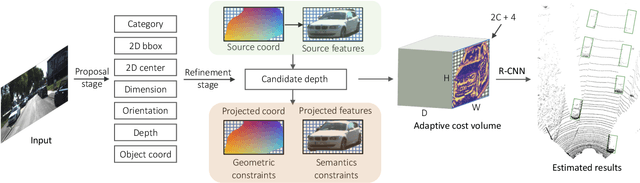
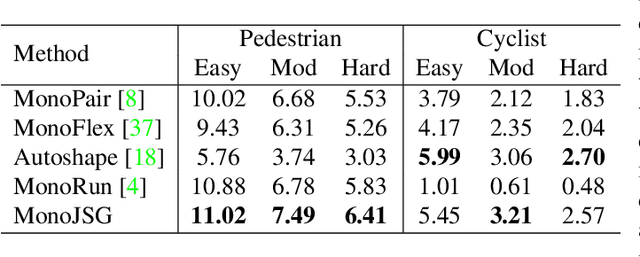
Due to the inherent ill-posed nature of 2D-3D projection, monocular 3D object detection lacks accurate depth recovery ability. Although the deep neural network (DNN) enables monocular depth-sensing from high-level learned features, the pixel-level cues are usually omitted due to the deep convolution mechanism. To benefit from both the powerful feature representation in DNN and pixel-level geometric constraints, we reformulate the monocular object depth estimation as a progressive refinement problem and propose a joint semantic and geometric cost volume to model the depth error. Specifically, we first leverage neural networks to learn the object position, dimension, and dense normalized 3D object coordinates. Based on the object depth, the dense coordinates patch together with the corresponding object features is reprojected to the image space to build a cost volume in a joint semantic and geometric error manner. The final depth is obtained by feeding the cost volume to a refinement network, where the distribution of semantic and geometric error is regularized by direct depth supervision. Through effectively mitigating depth error by the refinement framework, we achieve state-of-the-art results on both the KITTI and Waymo datasets.
Temporal Point Cloud Completion with Pose Disturbance
Feb 07, 2022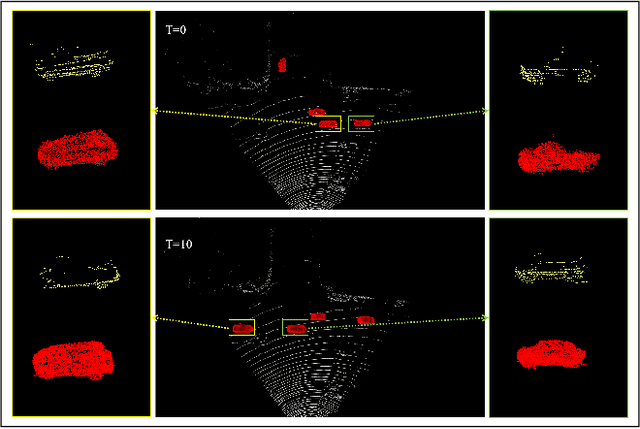
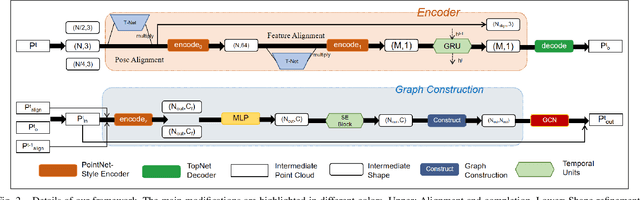
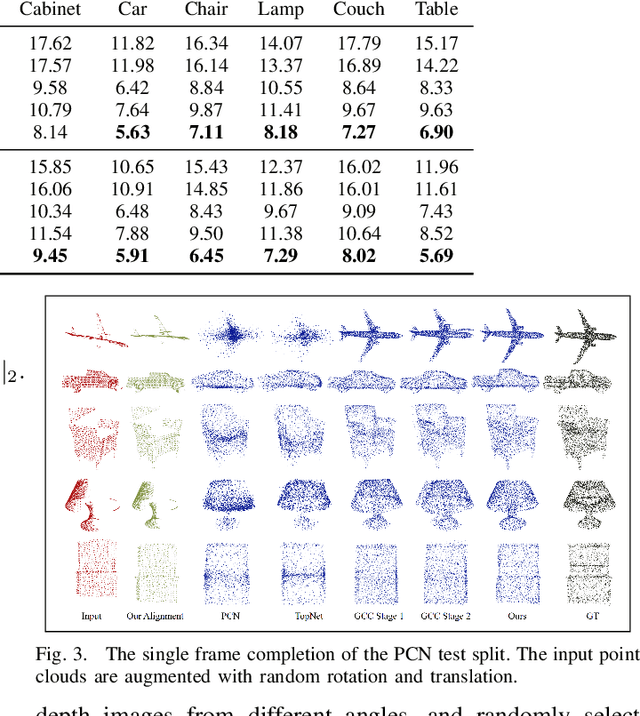
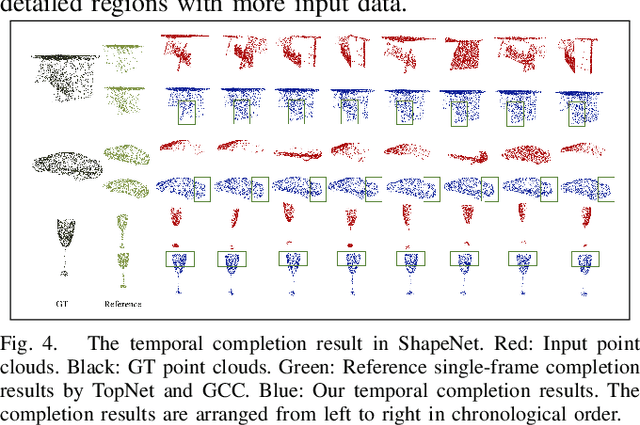
Point clouds collected by real-world sensors are always unaligned and sparse, which makes it hard to reconstruct the complete shape of object from a single frame of data. In this work, we manage to provide complete point clouds from sparse input with pose disturbance by limited translation and rotation. We also use temporal information to enhance the completion model, refining the output with a sequence of inputs. With the help of gated recovery units(GRU) and attention mechanisms as temporal units, we propose a point cloud completion framework that accepts a sequence of unaligned and sparse inputs, and outputs consistent and aligned point clouds. Our network performs in an online manner and presents a refined point cloud for each frame, which enables it to be integrated into any SLAM or reconstruction pipeline. As far as we know, our framework is the first to utilize temporal information and ensure temporal consistency with limited transformation. Through experiments in ShapeNet and KITTI, we prove that our framework is effective in both synthetic and real-world datasets.
Trajectory Prediction with Graph-based Dual-scale Context Fusion
Nov 02, 2021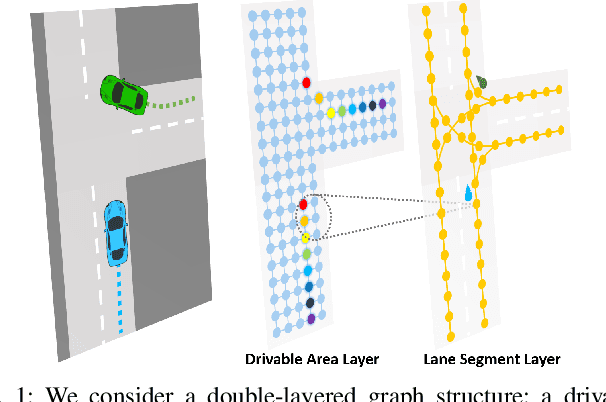
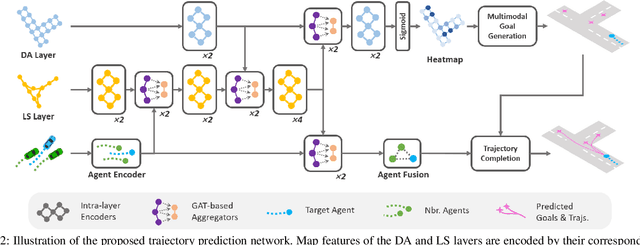
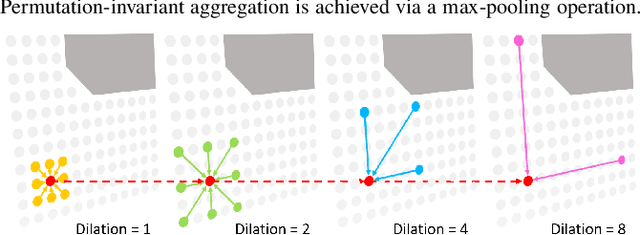
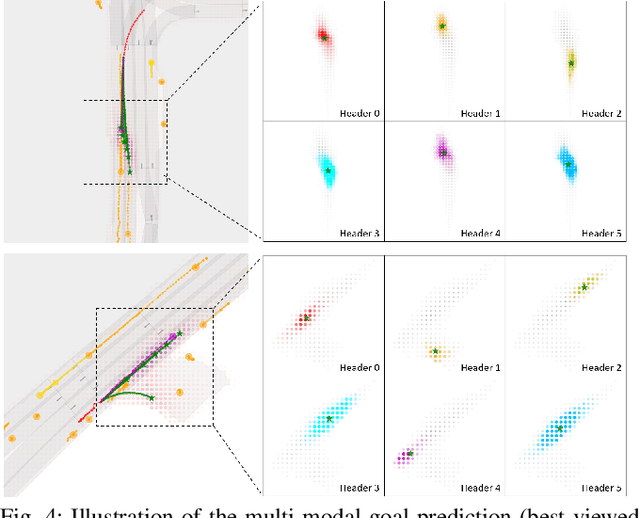
Motion prediction for traffic participants is essential for a safe and robust automated driving system, especially in cluttered urban environments. However, it is highly challenging due to the complex road topology as well as the uncertain intentions of the other agents. In this paper, we present a graph-based trajectory prediction network named the Dual Scale Predictor (DSP), which encodes both the static and dynamical driving context in a hierarchical manner. Different from methods based on a rasterized map or sparse lane graph, we consider the driving context as a graph with two layers, focusing on both geometrical and topological features. Graph neural networks (GNNs) are applied to extract features with different levels of granularity, and features are subsequently aggregated with attention-based inter-layer networks, realizing better local-global feature fusion. Following the recent goal-driven trajectory prediction pipeline, goal candidates with high likelihood for the target agent are extracted, and predicted trajectories are generated conditioned on these goals. Thanks to the proposed dual-scale context fusion network, our DSP is able to generate accurate and human-like multi-modal trajectories. We evaluate the proposed method on the large-scale Argoverse motion forecasting benchmark, and it achieves promising results, outperforming the recent state-of-the-art methods.
Tracking from Patterns: Learning Corresponding Patterns in Point Clouds for 3D Object Tracking
Oct 20, 2020


A robust 3D object tracker which continuously tracks surrounding objects and estimates their trajectories is key for self-driving vehicles. Most existing tracking methods employ a tracking-by-detection strategy, which usually requires complex pair-wise similarity computation and neglects the nature of continuous object motion. In this paper, we propose to directly learn 3D object correspondences from temporal point cloud data and infer the motion information from correspondence patterns. We modify the standard 3D object detector to process two lidar frames at the same time and predict bounding box pairs for the association and motion estimation tasks. We also equip our pipeline with a simple yet effective velocity smoothing module to estimate consistent object motion. Benifiting from the learned correspondences and motion refinement, our method exceeds the existing 3D tracking methods on both the KITTI and larger scale Nuscenes dataset.
* 4 pages, ECCV2020 Workshop on Perception for Autonomous Driving(PAD2020)