 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonoJSG: Joint Semantic and Geometric Cost Volume for Monocular 3D Object Detection
Paper and Code
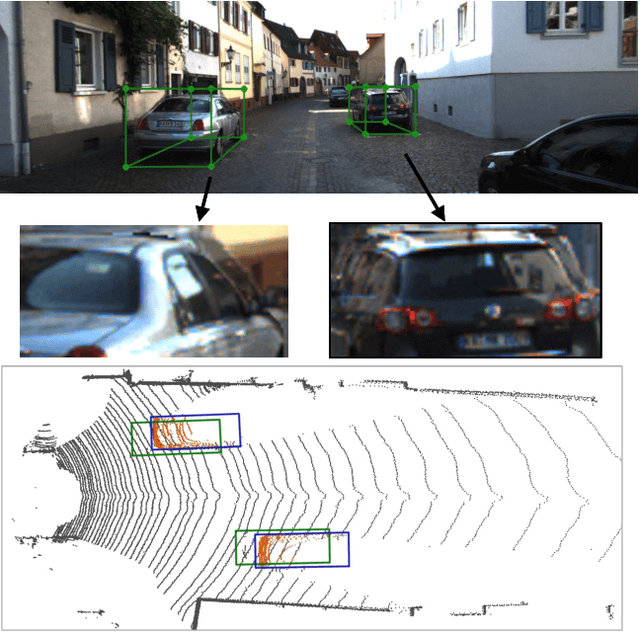
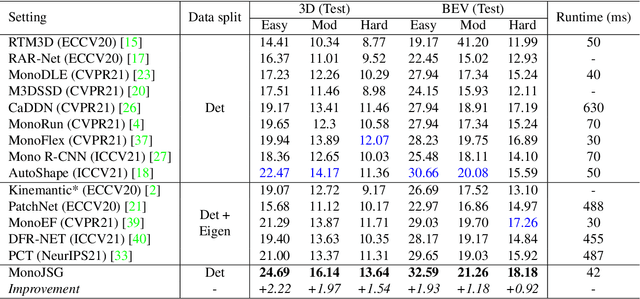
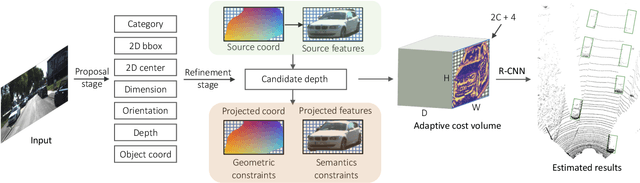
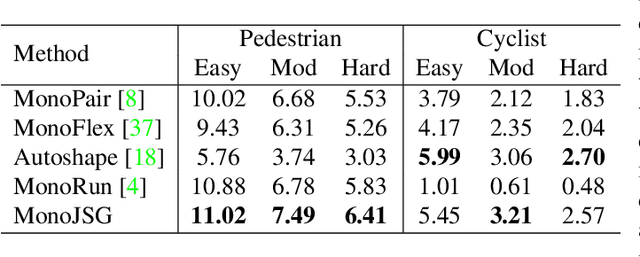
Due to the inherent ill-posed nature of 2D-3D projection, monocular 3D object detection lacks accurate depth recovery ability. Although the deep neural network (DNN) enables monocular depth-sensing from high-level learned features, the pixel-level cues are usually omitted due to the deep convolution mechanism. To benefit from both the powerful feature representation in DNN and pixel-level geometric constraints, we reformulate the monocular object depth estimation as a progressive refinement problem and propose a joint semantic and geometric cost volume to model the depth error. Specifically, we first leverage neural networks to learn the object position, dimension, and dense normalized 3D object coordinates. Based on the object depth, the dense coordinates patch together with the corresponding object features is reprojected to the image space to build a cost volume in a joint semantic and geometric error manner. The final depth is obtained by feeding the cost volume to a refinement network, where the distribution of semantic and geometric error is regularized by direct depth supervision. Through effectively mitigating depth error by the refinement framework, we achieve state-of-the-art results on both the KITTI and Waymo datasets.