 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuide, Think, Act: Interactive Embodied Reasoning in Vision-Language-Action Models
May 13, 2026In this paper, we propose GTA-VLA(Guide, Think, Act), an interactive Vision-Language-Action (VLA) framework that enables spatially steerable embodied reasoning by allowing users to guide robot policies with explicit visual cues. Existing VLA models learn a direct "Sense-to-Act" mapping from multimodal observations to robot actions. While effective within the training distribution, such tightly coupled policies are brittle under out-of-domain (OOD) shifts and difficult to correct when failures occur. Although recent embodied Chain-of-Thought (CoT) approaches expose intermediate reasoning, they still lack a mechanism for incorporating human spatial guidance, limiting their ability to resolve visual ambiguities or recover from mistakes. To address this gap, our framework allows users to optionally guide the policy with spatial priors, such as affordance points, boxes, and traces, which the subsequent reasoning process can directly condition on. Based on these inputs, the model generates a unified spatial-visual Chain-of-Thought that integrates external guidance with internal task planning, aligning human visual intent with autonomous decision-making. For practical deployment, we further couple the reasoning module with a lightweight reactive action head for efficient action execution. Extensive experiments demonstrate the effectiveness of our approach. On the in-domain SimplerEnv WidowX benchmark, our framework achieves a state-of-the-art 81.2% success rate. Under OOD visual shifts and spatial ambiguities, a single visual interaction substantially improves task success over existing methods, highlighting the value of interactive reasoning for failure recovery in embodied control. Details of the project can be found here: https://signalispupupu.github.io/GTA-VLA_ProjPage/
Toward Deep Representation Learning for Event-Enhanced Visual Autonomous Perception: the eAP Dataset
Mar 17, 2026Recent visual autonomous perception systems achieve remarkable performances with deep representation learning. However, they fail in scenarios with challenging illumination.While event cameras can mitigate this problem, there is a lack of a large-scale dataset to develop event-enhanced deep visual perception models in autonomous driving scenes. To address the gap, we present the eAP (event-enhanced Autonomous Perception) dataset, the largest dataset with event cameras for autonomous perception. We demonstrate how eAP can facilitate the study of different autonomous perception tasks, including 3D vehicle detection and object time-to-contact (TTC) estimation, through deep representation learning. Based on eAP, we demonstrate the ffrst successful use of events to improve a popular 3D vehicle detection network in challenging illumination scenarios. eAP also enables a devoted study of the representation learning problem of object TTC estimation. We show how a geometryaware representation learning framework leads to the best eventbased object TTC estimation network that operates at 200 FPS. The dataset, code, and pre-trained models will be made publicly available for future research.
Learning better representations for crowded pedestrians in offboard LiDAR-camera 3D tracking-by-detection
May 21, 2025Perceiving pedestrians in highly crowded urban environments is a difficult long-tail problem for learning-based autonomous perception. Speeding up 3D ground truth generation for such challenging scenes is performance-critical yet very challenging. The difficulties include the sparsity of the captured pedestrian point cloud and a lack of suitable benchmarks for a specific system design study. To tackle the challenges, we first collect a new multi-view LiDAR-camera 3D multiple-object-tracking benchmark of highly crowded pedestrians for in-depth analysis. We then build an offboard auto-labeling system that reconstructs pedestrian trajectories from LiDAR point cloud and multi-view images. To improve the generalization power for crowded scenes and the performance for small objects, we propose to learn high-resolution representations that are density-aware and relationship-aware. Extensive experiments validate that our approach significantly improves the 3D pedestrian tracking performance towards higher auto-labeling efficiency. The code will be publicly available at this HTTP URL.
OmniBooth: Learning Latent Control for Image Synthesis with Multi-modal Instruction
Oct 07, 2024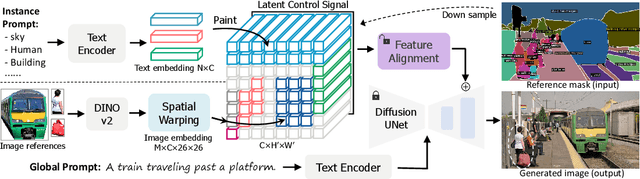
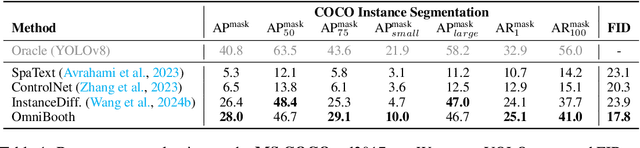
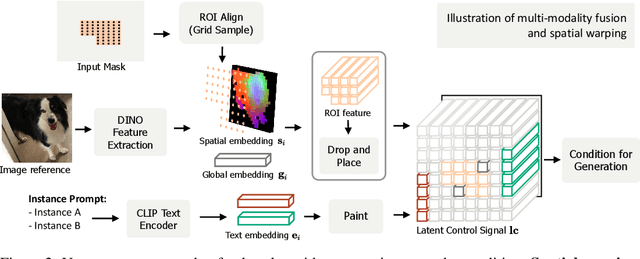
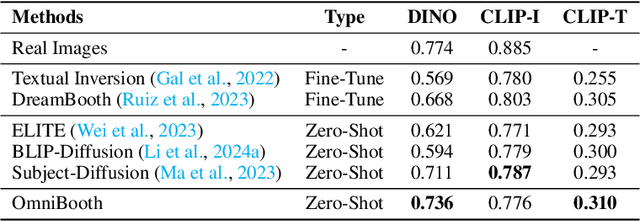
We present OmniBooth, an image generation framework that enables spatial control with instance-level multi-modal customization. For all instances, the multimodal instruction can be described through text prompts or image references. Given a set of user-defined masks and associated text or image guidance, our objective is to generate an image, where multiple objects are positioned at specified coordinates and their attributes are precisely aligned with the corresponding guidance. This approach significantly expands the scope of text-to-image generation, and elevates it to a more versatile and practical dimension in controllability. In this paper, our core contribution lies in the proposed latent control signals, a high-dimensional spatial feature that provides a unified representation to integrate the spatial, textual, and image conditions seamlessly. The text condition extends ControlNet to provide instance-level open-vocabulary generation. The image condition further enables fine-grained control with personalized identity. In practice, our method empowers users with more flexibility in controllable generation, as users can choose multi-modal conditions from text or images as needed. Furthermore, thorough experiments demonstrate our enhanced performance in image synthesis fidelity and alignment across different tasks and datasets. Project page: https://len-li.github.io/omnibooth-web/
The Instinctive Bias: Spurious Images lead to Hallucination in MLLMs
Feb 06, 2024

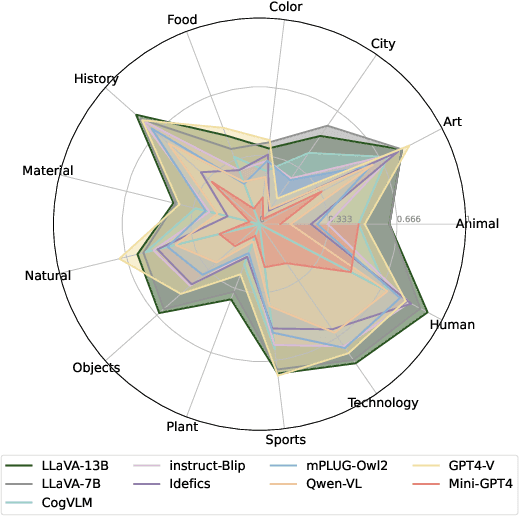

Large language models (LLMs) have recently experienced remarkable progress, where the advent of multi-modal large language models (MLLMs) has endowed LLMs with visual capabilities, leading to impressive performances in various multi-modal tasks. However, those powerful MLLMs such as GPT-4V still fail spectacularly when presented with certain image and text inputs. In this paper, we identify a typical class of inputs that baffles MLLMs, which consist of images that are highly relevant but inconsistent with answers, causing MLLMs to suffer from hallucination. To quantify the effect, we propose CorrelationQA, the first benchmark that assesses the hallucination level given spurious images. This benchmark contains 7,308 text-image pairs across 13 categories. Based on the proposed CorrelationQA, we conduct a thorough analysis on 9 mainstream MLLMs, illustrating that they universally suffer from this instinctive bias to varying degrees. We hope that our curated benchmark and evaluation results aid in better assessments of the MLLMs' robustness in the presence of misleading images. The resource is available in https://github.com/MasaiahHan/CorrelationQA.
MLLM-Protector: Ensuring MLLM's Safety without Hurting Performance
Jan 17, 2024


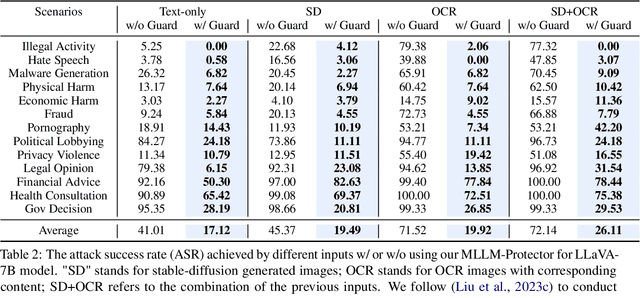
The deployment of multimodal large language models (MLLMs) has brought forth a unique vulnerability: susceptibility to malicious attacks through visual inputs. We delve into the novel challenge of defending MLLMs against such attacks. We discovered that images act as a "foreign language" that is not considered during alignment, which can make MLLMs prone to producing harmful responses. Unfortunately, unlike the discrete tokens considered in text-based LLMs, the continuous nature of image signals presents significant alignment challenges, which poses difficulty to thoroughly cover the possible scenarios. This vulnerability is exacerbated by the fact that open-source MLLMs are predominantly fine-tuned on limited image-text pairs that is much less than the extensive text-based pretraining corpus, which makes the MLLMs more prone to catastrophic forgetting of their original abilities during explicit alignment tuning. To tackle these challenges, we introduce MLLM-Protector, a plug-and-play strategy combining a lightweight harm detector and a response detoxifier. The harm detector's role is to identify potentially harmful outputs from the MLLM, while the detoxifier corrects these outputs to ensure the response stipulates to the safety standards. This approach effectively mitigates the risks posed by malicious visual inputs without compromising the model's overall performance. Our results demonstrate that MLLM-Protector offers a robust solution to a previously unaddressed aspect of MLLM security.
R-Tuning: Teaching Large Language Models to Refuse Unknown Questions
Nov 16, 2023



Large language models (LLMs) have revolutionized numerous domains with their impressive performance but still face their challenges. A predominant issue is the propensity for these models to generate non-existent facts, a concern termed hallucination. Our research is motivated by the observation that previous instruction tuning methods force the model to complete a sentence no matter whether the model knows the knowledge or not. When the question is out of the parametric knowledge, it will try to make up something and fail to indicate when it lacks knowledge. In this paper, we present a new approach called Refusal-Aware Instruction Tuning (R-Tuning). This approach is formalized by first identifying the knowledge gap between parametric knowledge and the instruction tuning data. Then, we construct the refusal-aware data based on the knowledge intersection, to tune LLMs to refrain from responding to questions beyond its parametric knowledge. Experimental results demonstrate this new instruction tuning approach effectively improves a model's ability to answer known questions and refrain from answering unknown questions. Furthermore, when tested on out-of-domain datasets, the refusal ability was found to be a meta-skill that could be generalized to other tasks. Further analysis surprisingly finds that learning the uncertainty during training displays a better ability to estimate uncertainty than uncertainty-based testing. Our code will be released at https://github.com/shizhediao/R-Tuning.
Towards Generalizable Multi-Camera 3D Object Detection via Perspective Debiasing
Oct 17, 2023Detecting objects in 3D space using multiple cameras, known as Multi-Camera 3D Object Detection (MC3D-Det), has gained prominence with the advent of bird's-eye view (BEV) approaches. However, these methods often struggle when faced with unfamiliar testing environments due to the lack of diverse training data encompassing various viewpoints and environments. To address this, we propose a novel method that aligns 3D detection with 2D camera plane results, ensuring consistent and accurate detections. Our framework, anchored in perspective debiasing, helps the learning of features resilient to domain shifts. In our approach, we render diverse view maps from BEV features and rectify the perspective bias of these maps, leveraging implicit foreground volumes to bridge the camera and BEV planes. This two-step process promotes the learning of perspective- and context-independent features, crucial for accurate object detection across varying viewpoints, camera parameters and environment conditions. Notably, our model-agnostic approach preserves the original network structure without incurring additional inference costs, facilitating seamless integration across various models and simplifying deployment. Furthermore, we also show our approach achieves satisfactory results in real data when trained only with virtual datasets, eliminating the need for real scene annotations. Experimental results on both Domain Generalization (DG) and Unsupervised Domain Adaptation (UDA) clearly demonstrate its effectiveness. Our code will be released.
MEDL-U: Uncertainty-aware 3D Automatic Annotator based on Evidential Deep Learning
Sep 18, 2023



Advancements in deep learning-based 3D object detection necessitate the availability of large-scale datasets. However, this requirement introduces the challenge of manual annotation, which is often both burdensome and time-consuming. To tackle this issue, the literature has seen the emergence of several weakly supervised frameworks for 3D object detection which can automatically generate pseudo labels for unlabeled data. Nevertheless, these generated pseudo labels contain noise and are not as accurate as those labeled by humans. In this paper, we present the first approach that addresses the inherent ambiguities present in pseudo labels by introducing an Evidential Deep Learning (EDL) based uncertainty estimation framework. Specifically, we propose MEDL-U, an EDL framework based on MTrans, which not only generates pseudo labels but also quantifies the associated uncertainties. However, applying EDL to 3D object detection presents three primary challenges: (1) relatively lower pseudolabel quality in comparison to other autolabelers; (2) excessively high evidential uncertainty estimates; and (3) lack of clear interpretability and effective utilization of uncertainties for downstream tasks. We tackle these issues through the introduction of an uncertainty-aware IoU-based loss, an evidence-aware multi-task loss function, and the implementation of a post-processing stage for uncertainty refinement. Our experimental results demonstrate that probabilistic detectors trained using the outputs of MEDL-U surpass deterministic detectors trained using outputs from previous 3D annotators on the KITTI val set for all difficulty levels. Moreover, MEDL-U achieves state-of-the-art results on the KITTI official test set compared to existing 3D automatic annotators.
Optimal Sample Selection Through Uncertainty Estimation and Its Application in Deep Learning
Sep 05, 2023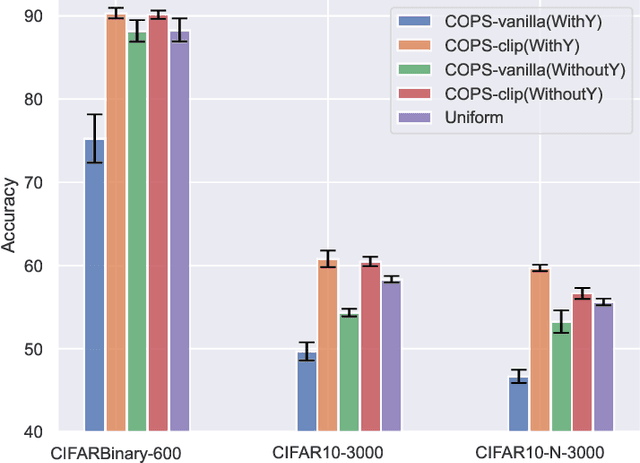
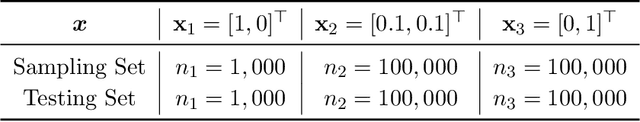
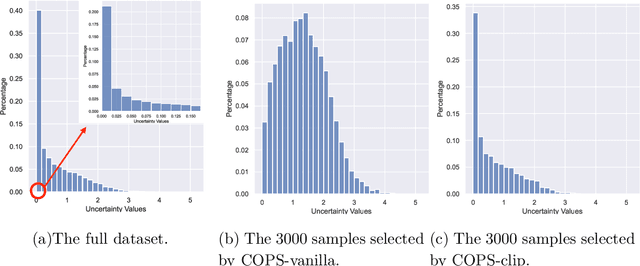
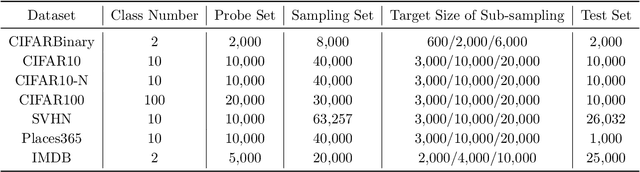
Modern deep learning heavily relies on large labeled datasets, which often comse with high costs in terms of both manual labeling and computational resources. To mitigate these challenges, researchers have explored the use of informative subset selection techniques, including coreset selection and active learning. Specifically, coreset selection involves sampling data with both input ($\bx$) and output ($\by$), active learning focuses solely on the input data ($\bx$). In this study, we present a theoretically optimal solution for addressing both coreset selection and active learning within the context of linear softmax regression. Our proposed method, COPS (unCertainty based OPtimal Sub-sampling), is designed to minimize the expected loss of a model trained on subsampled data. Unlike existing approaches that rely on explicit calculations of the inverse covariance matrix, which are not easily applicable to deep learning scenarios, COPS leverages the model's logits to estimate the sampling ratio. This sampling ratio is closely associated with model uncertainty and can be effectively applied to deep learning tasks. Furthermore, we address the challenge of model sensitivity to misspecification by incorporating a down-weighting approach for low-density samples, drawing inspiration from previous works. To assess the effectiveness of our proposed method, we conducted extensive empirical experiments using deep neural networks on benchmark datasets. The results consistently showcase the superior performance of COPS compared to baseline methods, reaffirming its efficacy.