 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial4D-Bench: A Versatile 4D Spatial Intelligence Benchmark
Dec 31, 20254D spatial intelligence involves perceiving and processing how objects move or change over time. Humans naturally possess 4D spatial intelligence, supporting a broad spectrum of spatial reasoning abilities. To what extent can Multimodal Large Language Models (MLLMs) achieve human-level 4D spatial intelligence? In this work, we present Spatial4D-Bench, a versatile 4D spatial intelligence benchmark designed to comprehensively assess the 4D spatial reasoning abilities of MLLMs. Unlike existing spatial intelligence benchmarks that are often small-scale or limited in diversity, Spatial4D-Bench provides a large-scale, multi-task evaluation benchmark consisting of ~40,000 question-answer pairs covering 18 well-defined tasks. We systematically organize these tasks into six cognitive categories: object understanding, scene understanding, spatial relationship understanding, spatiotemporal relationship understanding, spatial reasoning and spatiotemporal reasoning. Spatial4D-Bench thereby offers a structured and comprehensive benchmark for evaluating the spatial cognition abilities of MLLMs, covering a broad spectrum of tasks that parallel the versatility of human spatial intelligence. We benchmark various state-of-the-art open-source and proprietary MLLMs on Spatial4D-Bench and reveal their substantial limitations in a wide variety of 4D spatial reasoning aspects, such as route plan, action recognition, and physical plausibility reasoning. We hope that the findings provided in this work offer valuable insights to the community and that our benchmark can facilitate the development of more capable MLLMs toward human-level 4D spatial intelligence. More resources can be found on our project page.
Contrastive Knowledge Transfer and Robust Optimization for Secure Alignment of Large Language Models
Oct 31, 2025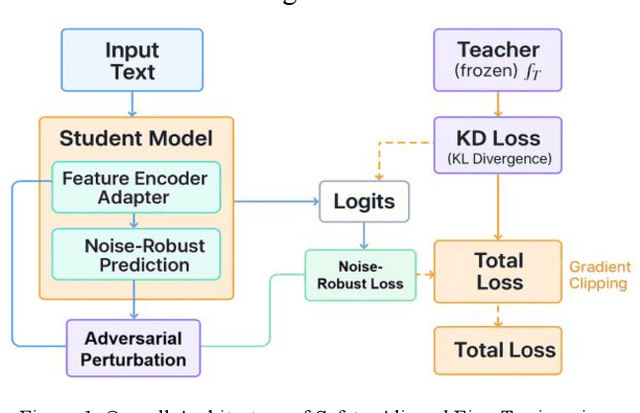
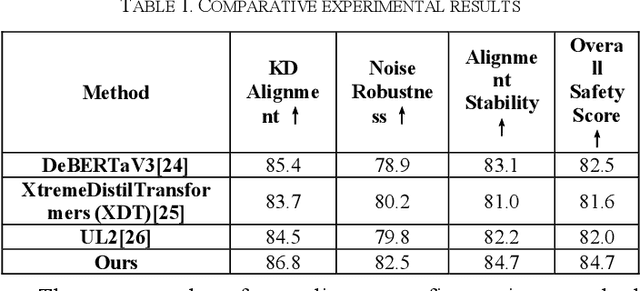
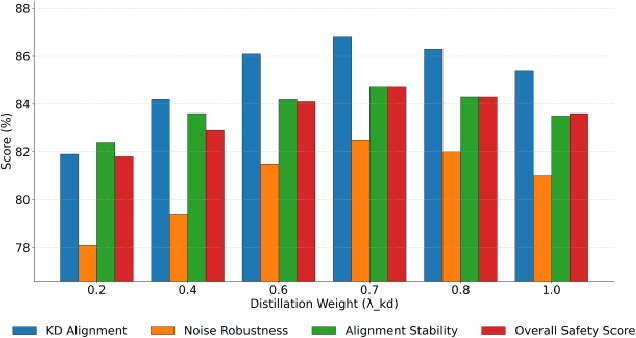
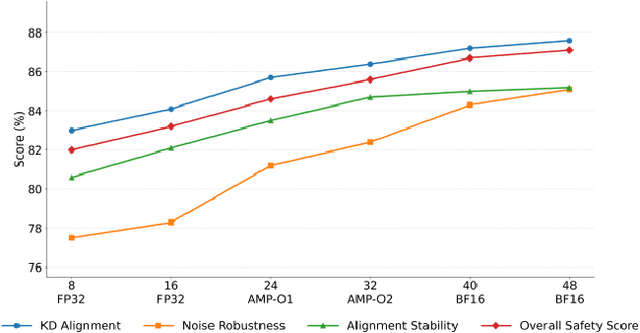
This paper addresses the limitations of large-scale language models in safety alignment and robustness by proposing a fine-tuning method that combines contrastive distillation with noise-robust training. The method freezes the backbone model and transfers the knowledge boundaries of the teacher model to the student model through distillation, thereby improving semantic consistency and alignment accuracy. At the same time, noise perturbations and robust optimization constraints are introduced during training to ensure that the model maintains stable predictive outputs under noisy and uncertain inputs. The overall framework consists of distillation loss, robustness loss, and a regularization term, forming a unified optimization objective that balances alignment ability with resistance to interference. To systematically validate its effectiveness, the study designs experiments from multiple perspectives, including distillation weight sensitivity, stability analysis under computation budgets and mixed-precision environments, and the impact of data noise and distribution shifts on model performance. Results show that the method significantly outperforms existing baselines in knowledge transfer, robustness, and overall safety, achieving the best performance across several key metrics. This work not only enriches the theoretical system of parameter-efficient fine-tuning but also provides a new solution for building safer and more trustworthy alignment mechanisms.
AnalogSeeker: An Open-source Foundation Language Model for Analog Circuit Design
Aug 14, 2025In this paper, we propose AnalogSeeker, an effort toward an open-source foundation language model for analog circuit design, with the aim of integrating domain knowledge and giving design assistance. To overcome the scarcity of data in this field, we employ a corpus collection strategy based on the domain knowledge framework of analog circuits. High-quality, accessible textbooks across relevant subfields are systematically curated and cleaned into a textual domain corpus. To address the complexity of knowledge of analog circuits, we introduce a granular domain knowledge distillation method. Raw, unlabeled domain corpus is decomposed into typical, granular learning nodes, where a multi-agent framework distills implicit knowledge embedded in unstructured text into question-answer data pairs with detailed reasoning processes, yielding a fine-grained, learnable dataset for fine-tuning. To address the unexplored challenges in training analog circuit foundation models, we explore and share our training methods through both theoretical analysis and experimental validation. We finally establish a fine-tuning-centric training paradigm, customizing and implementing a neighborhood self-constrained supervised fine-tuning algorithm. This approach enhances training outcomes by constraining the perturbation magnitude between the model's output distributions before and after training. In practice, we train the Qwen2.5-32B-Instruct model to obtain AnalogSeeker, which achieves 85.04% accuracy on AMSBench-TQA, the analog circuit knowledge evaluation benchmark, with a 15.67% point improvement over the original model and is competitive with mainstream commercial models. Furthermore, AnalogSeeker also shows effectiveness in the downstream operational amplifier design task. AnalogSeeker is open-sourced at https://huggingface.co/analogllm/analogseeker for research use.
A Physics-Driven Neural Network with Parameter Embedding for Generating Quantitative MR Maps from Weighted Images
Aug 11, 2025We propose a deep learning-based approach that integrates MRI sequence parameters to improve the accuracy and generalizability of quantitative image synthesis from clinical weighted MRI. Our physics-driven neural network embeds MRI sequence parameters -- repetition time (TR), echo time (TE), and inversion time (TI) -- directly into the model via parameter embedding, enabling the network to learn the underlying physical principles of MRI signal formation. The model takes conventional T1-weighted, T2-weighted, and T2-FLAIR images as input and synthesizes T1, T2, and proton density (PD) quantitative maps. Trained on healthy brain MR images, it was evaluated on both internal and external test datasets. The proposed method achieved high performance with PSNR values exceeding 34 dB and SSIM values above 0.92 for all synthesized parameter maps. It outperformed conventional deep learning models in accuracy and robustness, including data with previously unseen brain structures and lesions. Notably, our model accurately synthesized quantitative maps for these unseen pathological regions, highlighting its superior generalization capability. Incorporating MRI sequence parameters via parameter embedding allows the neural network to better learn the physical characteristics of MR signals, significantly enhancing the performance and reliability of quantitative MRI synthesis. This method shows great potential for accelerating qMRI and improving its clinical utility.
EVolSplat: Efficient Volume-based Gaussian Splatting for Urban View Synthesis
Mar 26, 2025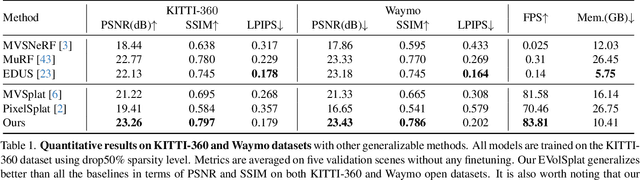
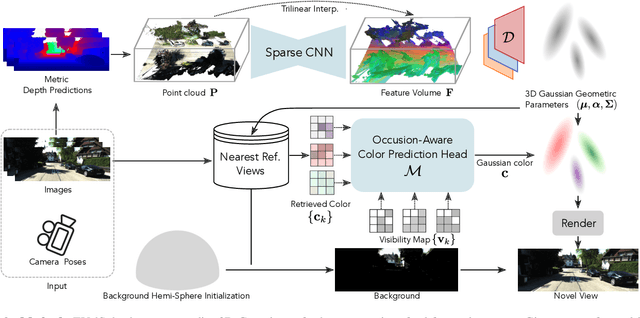
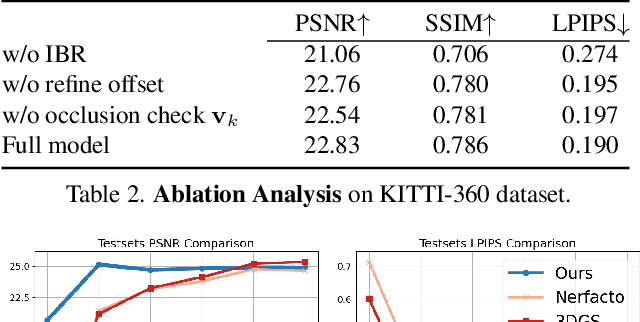
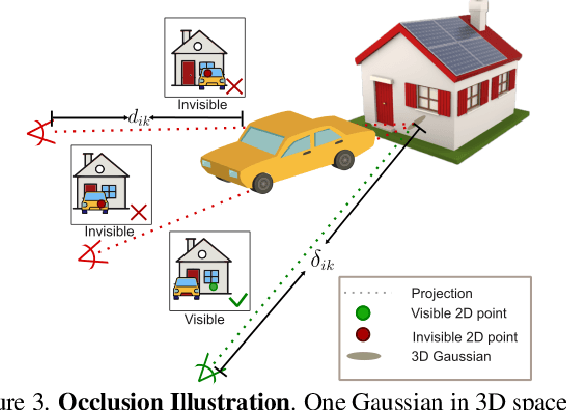
Novel view synthesis of urban scenes is essential for autonomous driving-related applications.Existing NeRF and 3DGS-based methods show promising results in achieving photorealistic renderings but require slow, per-scene optimization. We introduce EVolSplat, an efficient 3D Gaussian Splatting model for urban scenes that works in a feed-forward manner. Unlike existing feed-forward, pixel-aligned 3DGS methods, which often suffer from issues like multi-view inconsistencies and duplicated content, our approach predicts 3D Gaussians across multiple frames within a unified volume using a 3D convolutional network. This is achieved by initializing 3D Gaussians with noisy depth predictions, and then refining their geometric properties in 3D space and predicting color based on 2D textures. Our model also handles distant views and the sky with a flexible hemisphere background model. This enables us to perform fast, feed-forward reconstruction while achieving real-time rendering. Experimental evaluations on the KITTI-360 and Waymo datasets show that our method achieves state-of-the-art quality compared to existing feed-forward 3DGS- and NeRF-based methods.
Occ-LLM: Enhancing Autonomous Driving with Occupancy-Based Large Language Models
Feb 10, 2025Large Language Models (LLMs) have made substantial advancements in the field of robotic and autonomous driving. This study presents the first Occupancy-based Large Language Model (Occ-LLM), which represents a pioneering effort to integrate LLMs with an important representation. To effectively encode occupancy as input for the LLM and address the category imbalances associated with occupancy, we propose Motion Separation Variational Autoencoder (MS-VAE). This innovative approach utilizes prior knowledge to distinguish dynamic objects from static scenes before inputting them into a tailored Variational Autoencoder (VAE). This separation enhances the model's capacity to concentrate on dynamic trajectories while effectively reconstructing static scenes. The efficacy of Occ-LLM has been validated across key tasks, including 4D occupancy forecasting, self-ego planning, and occupancy-based scene question answering. Comprehensive evaluations demonstrate that Occ-LLM significantly surpasses existing state-of-the-art methodologies, achieving gains of about 6\% in Intersection over Union (IoU) and 4\% in mean Intersection over Union (mIoU) for the task of 4D occupancy forecasting. These findings highlight the transformative potential of Occ-LLM in reshaping current paradigms within robotic and autonomous driving.
An Efficient Occupancy World Model via Decoupled Dynamic Flow and Image-assisted Training
Dec 18, 2024



The field of autonomous driving is experiencing a surge of interest in world models, which aim to predict potential future scenarios based on historical observations. In this paper, we introduce DFIT-OccWorld, an efficient 3D occupancy world model that leverages decoupled dynamic flow and image-assisted training strategy, substantially improving 4D scene forecasting performance. To simplify the training process, we discard the previous two-stage training strategy and innovatively reformulate the occupancy forecasting problem as a decoupled voxels warping process. Our model forecasts future dynamic voxels by warping existing observations using voxel flow, whereas static voxels are easily obtained through pose transformation. Moreover, our method incorporates an image-assisted training paradigm to enhance prediction reliability. Specifically, differentiable volume rendering is adopted to generate rendered depth maps through predicted future volumes, which are adopted in render-based photometric consistency. Experiments demonstrate the effectiveness of our approach, showcasing its state-of-the-art performance on the nuScenes and OpenScene benchmarks for 4D occupancy forecasting, end-to-end motion planning and point cloud forecasting. Concretely, it achieves state-of-the-art performances compared to existing 3D world models while incurring substantially lower computational costs.
D$^2$-World: An Efficient World Model through Decoupled Dynamic Flow
Nov 26, 2024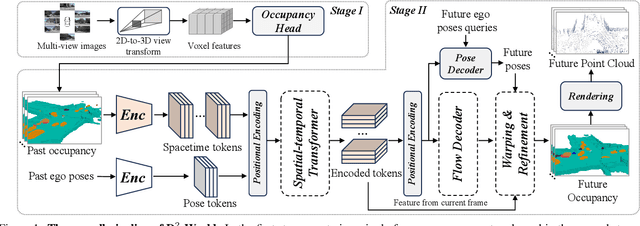
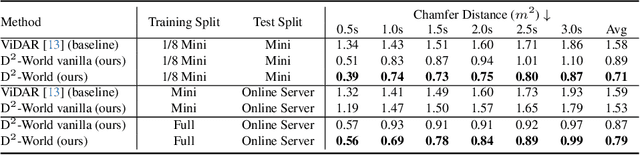
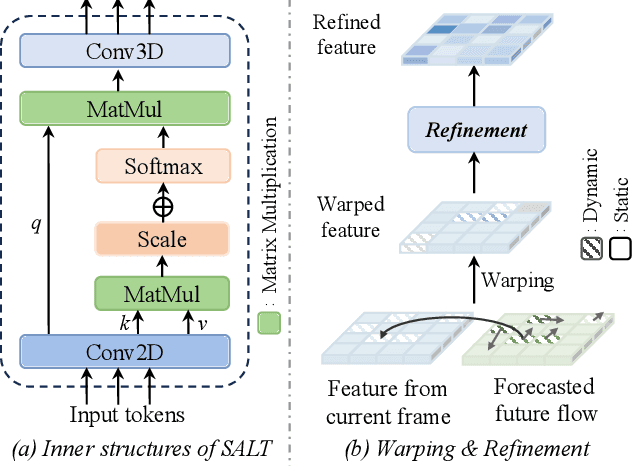
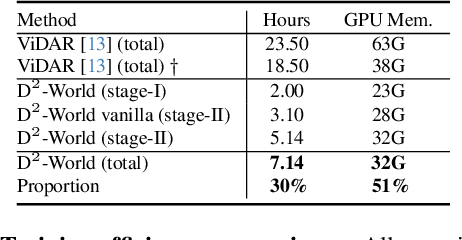
This technical report summarizes the second-place solution for the Predictive World Model Challenge held at the CVPR-2024 Workshop on Foundation Models for Autonomous Systems. We introduce D$^2$-World, a novel World model that effectively forecasts future point clouds through Decoupled Dynamic flow. Specifically, the past semantic occupancies are obtained via existing occupancy networks (e.g., BEVDet). Following this, the occupancy results serve as the input for a single-stage world model, generating future occupancy in a non-autoregressive manner. To further simplify the task, dynamic voxel decoupling is performed in the world model. The model generates future dynamic voxels by warping the existing observations through voxel flow, while remaining static voxels can be easily obtained through pose transformation. As a result, our approach achieves state-of-the-art performance on the OpenScene Predictive World Model benchmark, securing second place, and trains more than 300% faster than the baseline model. Code is available at https://github.com/zhanghm1995/D2-World.
VisionPAD: A Vision-Centric Pre-training Paradigm for Autonomous Driving
Nov 22, 2024



This paper introduces VisionPAD, a novel self-supervised pre-training paradigm designed for vision-centric algorithms in autonomous driving. In contrast to previous approaches that employ neural rendering with explicit depth supervision, VisionPAD utilizes more efficient 3D Gaussian Splatting to reconstruct multi-view representations using only images as supervision. Specifically, we introduce a self-supervised method for voxel velocity estimation. By warping voxels to adjacent frames and supervising the rendered outputs, the model effectively learns motion cues in the sequential data. Furthermore, we adopt a multi-frame photometric consistency approach to enhance geometric perception. It projects adjacent frames to the current frame based on rendered depths and relative poses, boosting the 3D geometric representation through pure image supervision. Extensive experiments on autonomous driving datasets demonstrate that VisionPAD significantly improves performance in 3D object detection, occupancy prediction and map segmentation, surpassing state-of-the-art pre-training strategies by a considerable margin.
Self-Supervised Graph Neural Networks for Enhanced Feature Extraction in Heterogeneous Information Networks
Oct 23, 2024This paper explores the applications and challenges of graph neural networks (GNNs) in processing complex graph data brought about by the rapid development of the Internet. Given the heterogeneity and redundancy problems that graph data often have, traditional GNN methods may be overly dependent on the initial structure and attribute information of the graph, which limits their ability to accurately simulate more complex relationships and patterns in the graph. Therefore, this study proposes a graph neural network model under a self-supervised learning framework, which can flexibly combine different types of additional information of the attribute graph and its nodes, so as to better mine the deep features in the graph data. By introducing a self-supervisory mechanism, it is expected to improve the adaptability of existing models to the diversity and complexity of graph data and improve the overall performance of the model.