 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Occupancy World Model via Decoupled Dynamic Flow and Image-assisted Training
Dec 18, 2024



The field of autonomous driving is experiencing a surge of interest in world models, which aim to predict potential future scenarios based on historical observations. In this paper, we introduce DFIT-OccWorld, an efficient 3D occupancy world model that leverages decoupled dynamic flow and image-assisted training strategy, substantially improving 4D scene forecasting performance. To simplify the training process, we discard the previous two-stage training strategy and innovatively reformulate the occupancy forecasting problem as a decoupled voxels warping process. Our model forecasts future dynamic voxels by warping existing observations using voxel flow, whereas static voxels are easily obtained through pose transformation. Moreover, our method incorporates an image-assisted training paradigm to enhance prediction reliability. Specifically, differentiable volume rendering is adopted to generate rendered depth maps through predicted future volumes, which are adopted in render-based photometric consistency. Experiments demonstrate the effectiveness of our approach, showcasing its state-of-the-art performance on the nuScenes and OpenScene benchmarks for 4D occupancy forecasting, end-to-end motion planning and point cloud forecasting. Concretely, it achieves state-of-the-art performances compared to existing 3D world models while incurring substantially lower computational costs.
D$^2$-World: An Efficient World Model through Decoupled Dynamic Flow
Nov 26, 2024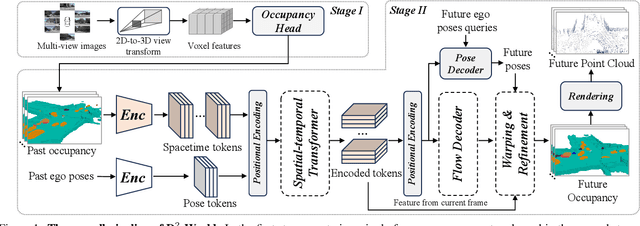
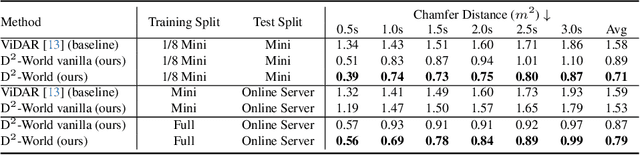
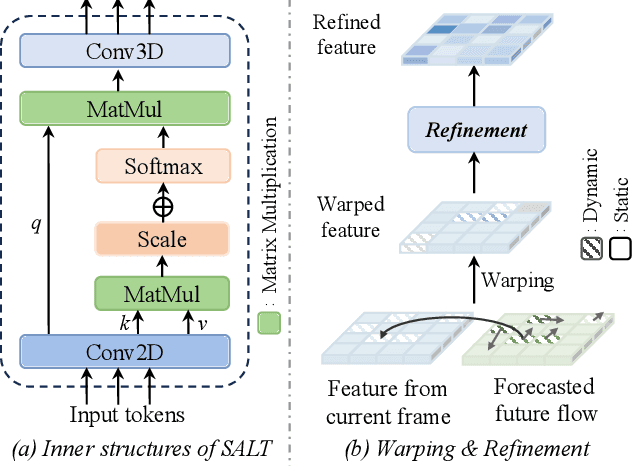
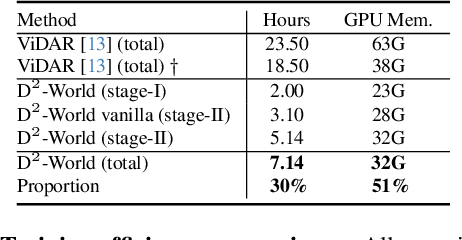
This technical report summarizes the second-place solution for the Predictive World Model Challenge held at the CVPR-2024 Workshop on Foundation Models for Autonomous Systems. We introduce D$^2$-World, a novel World model that effectively forecasts future point clouds through Decoupled Dynamic flow. Specifically, the past semantic occupancies are obtained via existing occupancy networks (e.g., BEVDet). Following this, the occupancy results serve as the input for a single-stage world model, generating future occupancy in a non-autoregressive manner. To further simplify the task, dynamic voxel decoupling is performed in the world model. The model generates future dynamic voxels by warping the existing observations through voxel flow, while remaining static voxels can be easily obtained through pose transformation. As a result, our approach achieves state-of-the-art performance on the OpenScene Predictive World Model benchmark, securing second place, and trains more than 300% faster than the baseline model. Code is available at https://github.com/zhanghm1995/D2-World.
VisionPAD: A Vision-Centric Pre-training Paradigm for Autonomous Driving
Nov 22, 2024



This paper introduces VisionPAD, a novel self-supervised pre-training paradigm designed for vision-centric algorithms in autonomous driving. In contrast to previous approaches that employ neural rendering with explicit depth supervision, VisionPAD utilizes more efficient 3D Gaussian Splatting to reconstruct multi-view representations using only images as supervision. Specifically, we introduce a self-supervised method for voxel velocity estimation. By warping voxels to adjacent frames and supervising the rendered outputs, the model effectively learns motion cues in the sequential data. Furthermore, we adopt a multi-frame photometric consistency approach to enhance geometric perception. It projects adjacent frames to the current frame based on rendered depths and relative poses, boosting the 3D geometric representation through pure image supervision. Extensive experiments on autonomous driving datasets demonstrate that VisionPAD significantly improves performance in 3D object detection, occupancy prediction and map segmentation, surpassing state-of-the-art pre-training strategies by a considerable margin.
KAN-AD: Time Series Anomaly Detection with Kolmogorov-Arnold Networks
Nov 01, 2024



Time series anomaly detection (TSAD) has become an essential component of large-scale cloud services and web systems because it can promptly identify anomalies, providing early warnings to prevent greater losses. Deep learning-based forecasting methods have become very popular in TSAD due to their powerful learning capabilities. However, accurate predictions don't necessarily lead to better anomaly detection. Due to the common occurrence of noise, i.e., local peaks and drops in time series, existing black-box learning methods can easily learn these unintended patterns, significantly affecting anomaly detection performance. Kolmogorov-Arnold Networks (KAN) offers a potential solution by decomposing complex temporal sequences into a combination of multiple univariate functions, making the training process more controllable. However, KAN optimizes univariate functions using spline functions, which are also susceptible to the influence of local anomalies. To address this issue, we present KAN-AD, which leverages the Fourier series to emphasize global temporal patterns, thereby mitigating the influence of local peaks and drops. KAN-AD improves both effectiveness and efficiency by transforming the existing black-box learning approach into learning the weights preceding univariate functions. Experimental results show that, compared to the current state-of-the-art, we achieved an accuracy increase of 15% while boosting inference speed by 55 times.
TimeSeriesBench: An Industrial-Grade Benchmark for Time Series Anomaly Detection Models
Feb 26, 2024Driven by the proliferation of real-world application scenarios and scales, time series anomaly detection (TSAD) has attracted considerable scholarly and industrial interest. However, existing algorithms exhibit a gap in terms of training paradigm, online detection paradigm, and evaluation criteria when compared to the actual needs of real-world industrial systems. Firstly, current algorithms typically train a specific model for each individual time series. In a large-scale online system with tens of thousands of curves, maintaining such a multitude of models is impractical. The performance of using merely one single unified model to detect anomalies remains unknown. Secondly, most TSAD models are trained on the historical part of a time series and are tested on its future segment. In distributed systems, however, there are frequent system deployments and upgrades, with new, previously unseen time series emerging daily. The performance of testing newly incoming unseen time series on current TSAD algorithms remains unknown. Lastly, although some papers have conducted detailed surveys, the absence of an online evaluation platform prevents answering questions like "Who is the best at anomaly detection at the current stage?" In this paper, we propose TimeSeriesBench, an industrial-grade benchmark that we continuously maintain as a leaderboard. On this leaderboard, we assess the performance of existing algorithms across more than 168 evaluation settings combining different training and testing paradigms, evaluation metrics and datasets. Through our comprehensive analysis of the results, we provide recommendations for the future design of anomaly detection algorithms. To address known issues with existing public datasets, we release an industrial dataset to the public together with TimeSeriesBench. All code, data, and the online leaderboard have been made publicly available.
Revisiting VAE for Unsupervised Time Series Anomaly Detection: A Frequency Perspective
Feb 05, 2024Time series Anomaly Detection (AD) plays a crucial role for web systems. Various web systems rely on time series data to monitor and identify anomalies in real time, as well as to initiate diagnosis and remediation procedures. Variational Autoencoders (VAEs) have gained popularity in recent decades due to their superior de-noising capabilities, which are useful for anomaly detection. However, our study reveals that VAE-based methods face challenges in capturing long-periodic heterogeneous patterns and detailed short-periodic trends simultaneously. To address these challenges, we propose Frequency-enhanced Conditional Variational Autoencoder (FCVAE), a novel unsupervised AD method for univariate time series. To ensure an accurate AD, FCVAE exploits an innovative approach to concurrently integrate both the global and local frequency features into the condition of Conditional Variational Autoencoder (CVAE) to significantly increase the accuracy of reconstructing the normal data. Together with a carefully designed "target attention" mechanism, our approach allows the model to pick the most useful information from the frequency domain for better short-periodic trend construction. Our FCVAE has been evaluated on public datasets and a large-scale cloud system, and the results demonstrate that it outperforms state-of-the-art methods. This confirms the practical applicability of our approach in addressing the limitations of current VAE-based anomaly detection models.
Forging Vision Foundation Models for Autonomous Driving: Challenges, Methodologies, and Opportunities
Jan 16, 2024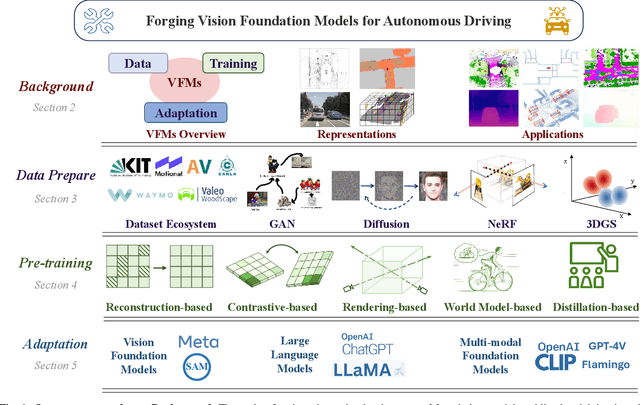
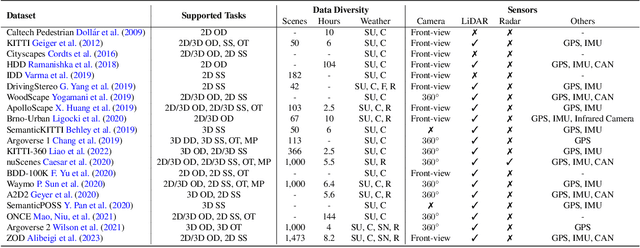
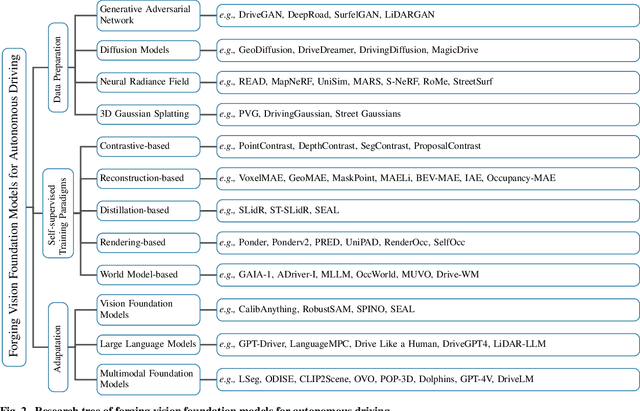

The rise of large foundation models, trained on extensive datasets, is revolutionizing the field of AI. Models such as SAM, DALL-E2, and GPT-4 showcase their adaptability by extracting intricate patterns and performing effectively across diverse tasks, thereby serving as potent building blocks for a wide range of AI applications. Autonomous driving, a vibrant front in AI applications, remains challenged by the lack of dedicated vision foundation models (VFMs). The scarcity of comprehensive training data, the need for multi-sensor integration, and the diverse task-specific architectures pose significant obstacles to the development of VFMs in this field. This paper delves into the critical challenge of forging VFMs tailored specifically for autonomous driving, while also outlining future directions. Through a systematic analysis of over 250 papers, we dissect essential techniques for VFM development, including data preparation, pre-training strategies, and downstream task adaptation. Moreover, we explore key advancements such as NeRF, diffusion models, 3D Gaussian Splatting, and world models, presenting a comprehensive roadmap for future research. To empower researchers, we have built and maintained https://github.com/zhanghm1995/Forge_VFM4AD, an open-access repository constantly updated with the latest advancements in forging VFMs for autonomous driving.
RadOcc: Learning Cross-Modality Occupancy Knowledge through Rendering Assisted Distillation
Dec 19, 2023



3D occupancy prediction is an emerging task that aims to estimate the occupancy states and semantics of 3D scenes using multi-view images. However, image-based scene perception encounters significant challenges in achieving accurate prediction due to the absence of geometric priors. In this paper, we address this issue by exploring cross-modal knowledge distillation in this task, i.e., we leverage a stronger multi-modal model to guide the visual model during training. In practice, we observe that directly applying features or logits alignment, proposed and widely used in bird's-eyeview (BEV) perception, does not yield satisfactory results. To overcome this problem, we introduce RadOcc, a Rendering assisted distillation paradigm for 3D Occupancy prediction. By employing differentiable volume rendering, we generate depth and semantic maps in perspective views and propose two novel consistency criteria between the rendered outputs of teacher and student models. Specifically, the depth consistency loss aligns the termination distributions of the rendered rays, while the semantic consistency loss mimics the intra-segment similarity guided by vision foundation models (VLMs). Experimental results on the nuScenes dataset demonstrate the effectiveness of our proposed method in improving various 3D occupancy prediction approaches, e.g., our proposed methodology enhances our baseline by 2.2% in the metric of mIoU and achieves 50% in Occ3D benchmark.
GSmoothFace: Generalized Smooth Talking Face Generation via Fine Grained 3D Face Guidance
Dec 12, 2023



Although existing speech-driven talking face generation methods achieve significant progress, they are far from real-world application due to the avatar-specific training demand and unstable lip movements. To address the above issues, we propose the GSmoothFace, a novel two-stage generalized talking face generation model guided by a fine-grained 3d face model, which can synthesize smooth lip dynamics while preserving the speaker's identity. Our proposed GSmoothFace model mainly consists of the Audio to Expression Prediction (A2EP) module and the Target Adaptive Face Translation (TAFT) module. Specifically, we first develop the A2EP module to predict expression parameters synchronized with the driven speech. It uses a transformer to capture the long-term audio context and learns the parameters from the fine-grained 3D facial vertices, resulting in accurate and smooth lip-synchronization performance. Afterward, the well-designed TAFT module, empowered by Morphology Augmented Face Blending (MAFB), takes the predicted expression parameters and target video as inputs to modify the facial region of the target video without distorting the background content. The TAFT effectively exploits the identity appearance and background context in the target video, which makes it possible to generalize to different speakers without retraining. Both quantitative and qualitative experiments confirm the superiority of our method in terms of realism, lip synchronization, and visual quality. See the project page for code, data, and request pre-trained models: https://zhanghm1995.github.io/GSmoothFace.
OpsEval: A Comprehensive Task-Oriented AIOps Benchmark for Large Language Models
Oct 12, 2023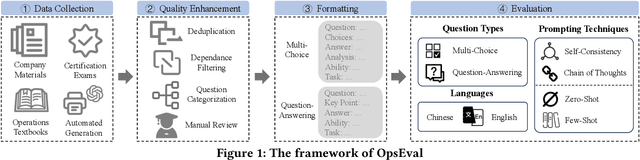
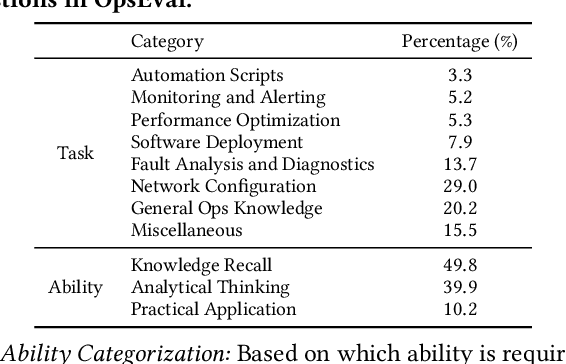

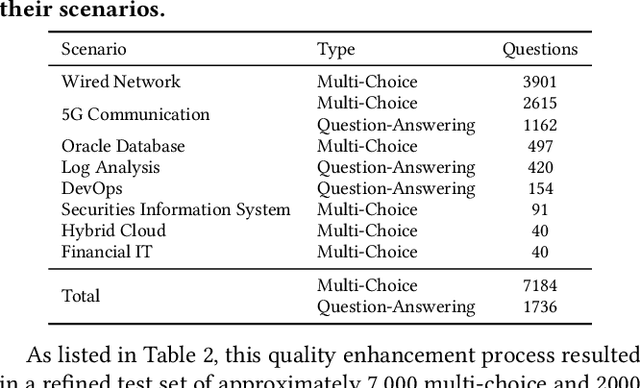
Large language models (LLMs) have exhibited remarkable capabilities in NLP-related tasks such as translation, summarizing, and generation. The application of LLMs in specific areas, notably AIOps (Artificial Intelligence for IT Operations), holds great potential due to their advanced abilities in information summarizing, report analyzing, and ability of API calling. Nevertheless, the performance of current LLMs in AIOps tasks is yet to be determined. Furthermore, a comprehensive benchmark is required to steer the optimization of LLMs tailored for AIOps. Compared with existing benchmarks that focus on evaluating specific fields like network configuration, in this paper, we present \textbf{OpsEval}, a comprehensive task-oriented AIOps benchmark designed for LLMs. For the first time, OpsEval assesses LLMs' proficiency in three crucial scenarios (Wired Network Operation, 5G Communication Operation, and Database Operation) at various ability levels (knowledge recall, analytical thinking, and practical application). The benchmark includes 7,200 questions in both multiple-choice and question-answer (QA) formats, available in English and Chinese. With quantitative and qualitative results, we show how various LLM tricks can affect the performance of AIOps, including zero-shot, chain-of-thought, and few-shot in-context learning. We find that GPT4-score is more consistent with experts than widely used Bleu and Rouge, which can be used to replace automatic metrics for large-scale qualitative evaluations.