 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking ERP Analysis: Manual Features, Deep Learning, and Foundation Models
Jan 02, 2026Event-related potential (ERP), a specialized paradigm of electroencephalographic (EEG), reflects neurological responses to external stimuli or events, generally associated with the brain's processing of specific cognitive tasks. ERP plays a critical role in cognitive analysis, the detection of neurological diseases, and the assessment of psychological states. Recent years have seen substantial advances in deep learning-based methods for spontaneous EEG and other non-time-locked task-related EEG signals. However, their effectiveness on ERP data remains underexplored, and many existing ERP studies still rely heavily on manually extracted features. In this paper, we conduct a comprehensive benchmark study that systematically compares traditional manual features (followed by a linear classifier), deep learning models, and pre-trained EEG foundation models for ERP analysis. We establish a unified data preprocessing and training pipeline and evaluate these approaches on two representative tasks, ERP stimulus classification and ERP-based brain disease detection, across 12 publicly available datasets. Furthermore, we investigate various patch-embedding strategies within advanced Transformer architectures to identify embedding designs that better suit ERP data. Our study provides a landmark framework to guide method selection and tailored model design for future ERP analysis. The code is available at https://github.com/DL4mHealth/ERP-Benchmark.
Learning Enhanced Ensemble Filters
Apr 24, 2025The filtering distribution in hidden Markov models evolves according to the law of a mean-field model in state--observation space. The ensemble Kalman filter (EnKF) approximates this mean-field model with an ensemble of interacting particles, employing a Gaussian ansatz for the joint distribution of the state and observation at each observation time. These methods are robust, but the Gaussian ansatz limits accuracy. This shortcoming is addressed by approximating the mean-field evolution using a novel form of neural operator taking probability distributions as input: a Measure Neural Mapping (MNM). A MNM is used to design a novel approach to filtering, the MNM-enhanced ensemble filter (MNMEF), which is defined in both the mean-fieldlimit and for interacting ensemble particle approximations. The ensemble approach uses empirical measures as input to the MNM and is implemented using the set transformer, which is invariant to ensemble permutation and allows for different ensemble sizes. The derivation of methods from a mean-field formulation allows a single parameterization of the algorithm to be deployed at different ensemble sizes. In practice fine-tuning of a small number of parameters, for specific ensemble sizes, further enhances the accuracy of the scheme. The promise of the approach is demonstrated by its superior root-mean-square-error performance relative to leading methods in filtering the Lorenz 96 and Kuramoto-Sivashinsky models.
BizGen: Advancing Article-level Visual Text Rendering for Infographics Generation
Mar 26, 2025Recently, state-of-the-art text-to-image generation models, such as Flux and Ideogram 2.0, have made significant progress in sentence-level visual text rendering. In this paper, we focus on the more challenging scenarios of article-level visual text rendering and address a novel task of generating high-quality business content, including infographics and slides, based on user provided article-level descriptive prompts and ultra-dense layouts. The fundamental challenges are twofold: significantly longer context lengths and the scarcity of high-quality business content data. In contrast to most previous works that focus on a limited number of sub-regions and sentence-level prompts, ensuring precise adherence to ultra-dense layouts with tens or even hundreds of sub-regions in business content is far more challenging. We make two key technical contributions: (i) the construction of scalable, high-quality business content dataset, i.e., Infographics-650K, equipped with ultra-dense layouts and prompts by implementing a layer-wise retrieval-augmented infographic generation scheme; and (ii) a layout-guided cross attention scheme, which injects tens of region-wise prompts into a set of cropped region latent space according to the ultra-dense layouts, and refine each sub-regions flexibly during inference using a layout conditional CFG. We demonstrate the strong results of our system compared to previous SOTA systems such as Flux and SD3 on our BizEval prompt set. Additionally, we conduct thorough ablation experiments to verify the effectiveness of each component. We hope our constructed Infographics-650K and BizEval can encourage the broader community to advance the progress of business content generation.
GLL: A Differentiable Graph Learning Layer for Neural Networks
Dec 11, 2024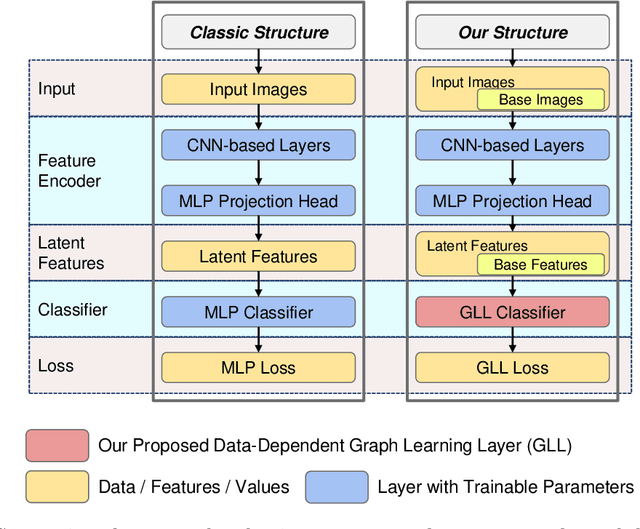
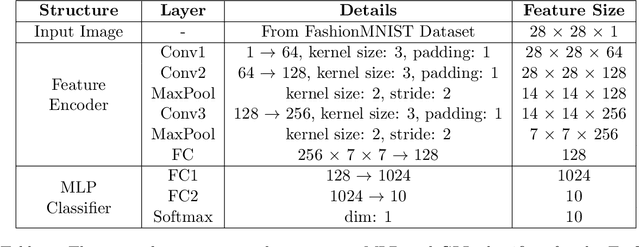


Standard deep learning architectures used for classification generate label predictions with a projection head and softmax activation function. Although successful, these methods fail to leverage the relational information between samples in the batch for generating label predictions. In recent works, graph-based learning techniques, namely Laplace learning, have been heuristically combined with neural networks for both supervised and semi-supervised learning (SSL) tasks. However, prior works approximate the gradient of the loss function with respect to the graph learning algorithm or decouple the processes; end-to-end integration with neural networks is not achieved. In this work, we derive backpropagation equations, via the adjoint method, for inclusion of a general family of graph learning layers into a neural network. This allows us to precisely integrate graph Laplacian-based label propagation into a neural network layer, replacing a projection head and softmax activation function for classification tasks. Using this new framework, our experimental results demonstrate smooth label transitions across data, improved robustness to adversarial attacks, improved generalization, and improved training dynamics compared to the standard softmax-based approach.
Narrative Analysis of True Crime Podcasts With Knowledge Graph-Augmented Large Language Models
Nov 01, 2024
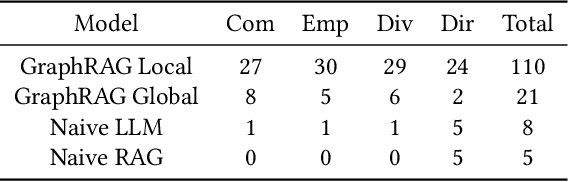

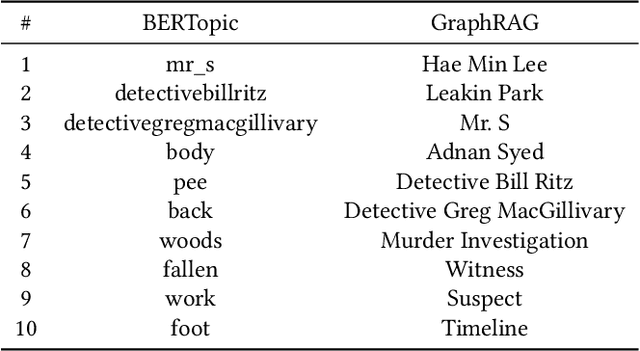
Narrative data spans all disciplines and provides a coherent model of the world to the reader or viewer. Recent advancement in machine learning and Large Language Models (LLMs) have enable great strides in analyzing natural language. However, Large language models (LLMs) still struggle with complex narrative arcs as well as narratives containing conflicting information. Recent work indicates LLMs augmented with external knowledge bases can improve the accuracy and interpretability of the resulting models. In this work, we analyze the effectiveness of applying knowledge graphs (KGs) in understanding true-crime podcast data from both classical Natural Language Processing (NLP) and LLM approaches. We directly compare KG-augmented LLMs (KGLLMs) with classical methods for KG construction, topic modeling, and sentiment analysis. Additionally, the KGLLM allows us to query the knowledge base in natural language and test its ability to factually answer questions. We examine the robustness of the model to adversarial prompting in order to test the model's ability to deal with conflicting information. Finally, we apply classical methods to understand more subtle aspects of the text such as the use of hearsay and sentiment in narrative construction and propose future directions. Our results indicate that KGLLMs outperform LLMs on a variety of metrics, are more robust to adversarial prompts, and are more capable of summarizing the text into topics.
Glyph-ByT5-v2: A Strong Aesthetic Baseline for Accurate Multilingual Visual Text Rendering
Jun 14, 2024



Recently, Glyph-ByT5 has achieved highly accurate visual text rendering performance in graphic design images. However, it still focuses solely on English and performs relatively poorly in terms of visual appeal. In this work, we address these two fundamental limitations by presenting Glyph-ByT5-v2 and Glyph-SDXL-v2, which not only support accurate visual text rendering for 10 different languages but also achieve much better aesthetic quality. To achieve this, we make the following contributions: (i) creating a high-quality multilingual glyph-text and graphic design dataset consisting of more than 1 million glyph-text pairs and 10 million graphic design image-text pairs covering nine other languages, (ii) building a multilingual visual paragraph benchmark consisting of 1,000 prompts, with 100 for each language, to assess multilingual visual spelling accuracy, and (iii) leveraging the latest step-aware preference learning approach to enhance the visual aesthetic quality. With the combination of these techniques, we deliver a powerful customized multilingual text encoder, Glyph-ByT5-v2, and a strong aesthetic graphic generation model, Glyph-SDXL-v2, that can support accurate spelling in 10 different languages. We perceive our work as a significant advancement, considering that the latest DALL-E3 and Ideogram 1.0 still struggle with the multilingual visual text rendering task.
FontStudio: Shape-Adaptive Diffusion Model for Coherent and Consistent Font Effect Generation
Jun 12, 2024



Recently, the application of modern diffusion-based text-to-image generation models for creating artistic fonts, traditionally the domain of professional designers, has garnered significant interest. Diverging from the majority of existing studies that concentrate on generating artistic typography, our research aims to tackle a novel and more demanding challenge: the generation of text effects for multilingual fonts. This task essentially requires generating coherent and consistent visual content within the confines of a font-shaped canvas, as opposed to a traditional rectangular canvas. To address this task, we introduce a novel shape-adaptive diffusion model capable of interpreting the given shape and strategically planning pixel distributions within the irregular canvas. To achieve this, we curate a high-quality shape-adaptive image-text dataset and incorporate the segmentation mask as a visual condition to steer the image generation process within the irregular-canvas. This approach enables the traditionally rectangle canvas-based diffusion model to produce the desired concepts in accordance with the provided geometric shapes. Second, to maintain consistency across multiple letters, we also present a training-free, shape-adaptive effect transfer method for transferring textures from a generated reference letter to others. The key insights are building a font effect noise prior and propagating the font effect information in a concatenated latent space. The efficacy of our FontStudio system is confirmed through user preference studies, which show a marked preference (78% win-rates on aesthetics) for our system even when compared to the latest unrivaled commercial product, Adobe Firefly.
Step-aware Preference Optimization: Aligning Preference with Denoising Performance at Each Step
Jun 06, 2024



Recently, Direct Preference Optimization (DPO) has extended its success from aligning large language models (LLMs) to aligning text-to-image diffusion models with human preferences. Unlike most existing DPO methods that assume all diffusion steps share a consistent preference order with the final generated images, we argue that this assumption neglects step-specific denoising performance and that preference labels should be tailored to each step's contribution. To address this limitation, we propose Step-aware Preference Optimization (SPO), a novel post-training approach that independently evaluates and adjusts the denoising performance at each step, using a step-aware preference model and a step-wise resampler to ensure accurate step-aware supervision. Specifically, at each denoising step, we sample a pool of images, find a suitable win-lose pair, and, most importantly, randomly select a single image from the pool to initialize the next denoising step. This step-wise resampler process ensures the next win-lose image pair comes from the same image, making the win-lose comparison independent of the previous step. To assess the preferences at each step, we train a separate step-aware preference model that can be applied to both noisy and clean images. Our experiments with Stable Diffusion v1.5 and SDXL demonstrate that SPO significantly outperforms the latest Diffusion-DPO in aligning generated images with complex, detailed prompts and enhancing aesthetics, while also achieving more than 20x times faster in training efficiency. Code and model: https://rockeycoss.github.io/spo.github.io/
AutoKG: Efficient Automated Knowledge Graph Generation for Language Models
Nov 22, 2023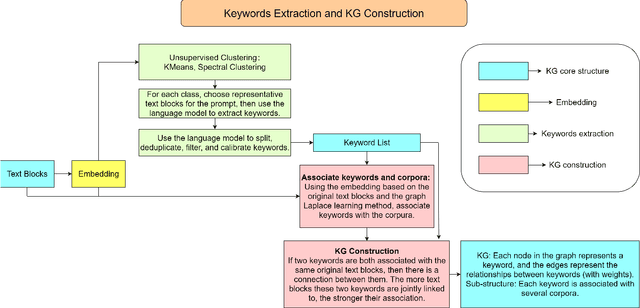


Traditional methods of linking large language models (LLMs) to knowledge bases via the semantic similarity search often fall short of capturing complex relational dynamics. To address these limitations, we introduce AutoKG, a lightweight and efficient approach for automated knowledge graph (KG) construction. For a given knowledge base consisting of text blocks, AutoKG first extracts keywords using a LLM and then evaluates the relationship weight between each pair of keywords using graph Laplace learning. We employ a hybrid search scheme combining vector similarity and graph-based associations to enrich LLM responses. Preliminary experiments demonstrate that AutoKG offers a more comprehensive and interconnected knowledge retrieval mechanism compared to the semantic similarity search, thereby enhancing the capabilities of LLMs in generating more insightful and relevant outputs.
OpsEval: A Comprehensive Task-Oriented AIOps Benchmark for Large Language Models
Oct 12, 2023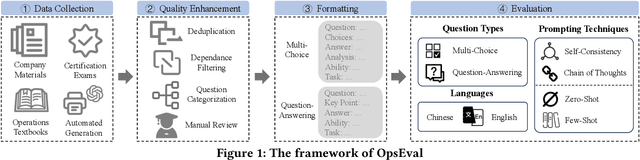
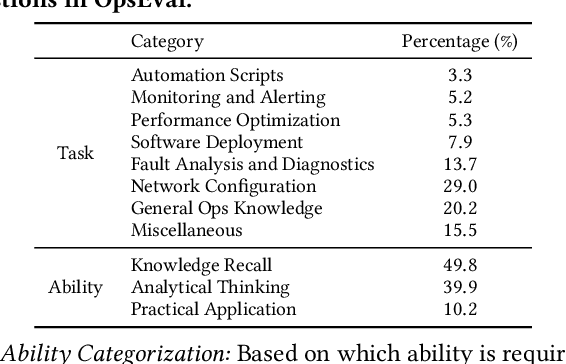

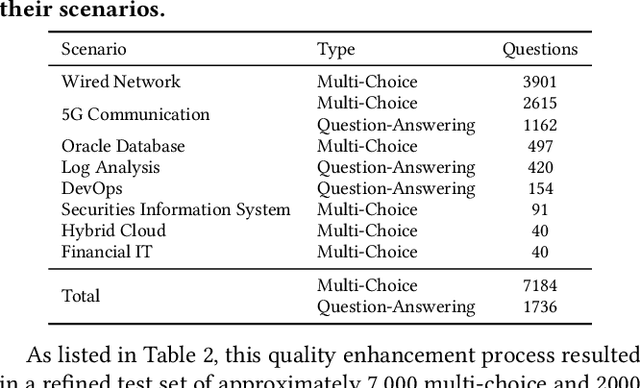
Large language models (LLMs) have exhibited remarkable capabilities in NLP-related tasks such as translation, summarizing, and generation. The application of LLMs in specific areas, notably AIOps (Artificial Intelligence for IT Operations), holds great potential due to their advanced abilities in information summarizing, report analyzing, and ability of API calling. Nevertheless, the performance of current LLMs in AIOps tasks is yet to be determined. Furthermore, a comprehensive benchmark is required to steer the optimization of LLMs tailored for AIOps. Compared with existing benchmarks that focus on evaluating specific fields like network configuration, in this paper, we present \textbf{OpsEval}, a comprehensive task-oriented AIOps benchmark designed for LLMs. For the first time, OpsEval assesses LLMs' proficiency in three crucial scenarios (Wired Network Operation, 5G Communication Operation, and Database Operation) at various ability levels (knowledge recall, analytical thinking, and practical application). The benchmark includes 7,200 questions in both multiple-choice and question-answer (QA) formats, available in English and Chinese. With quantitative and qualitative results, we show how various LLM tricks can affect the performance of AIOps, including zero-shot, chain-of-thought, and few-shot in-context learning. We find that GPT4-score is more consistent with experts than widely used Bleu and Rouge, which can be used to replace automatic metrics for large-scale qualitative evaluations.