 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProSPy: A Profiling-Driven SQL-Python Agentic Framework for Enterprise Text-to-SQL
Jun 04, 2026Large language models have substantially advanced Text-to-SQL systems, yet applying them to enterprise-scale databases remains challenging. Real-world databases often contain large and heterogeneous schemas, incomplete metadata, dialect-specific SQL syntax, and complex analytical questions that are difficult to solve with a single SQL query. To address these challenges, we propose ProSPy, a Profiling-driven SQL--Python agentic framework for enterprise-scale Text-to-SQL. ProSPy structures the reasoning process into four stages: it first extracts fine-grained data evidence through automatic profiling, progressively prunes large schemas into task-relevant contexts, fetches intermediate views through a dialect-agnostic SQL interface, and finally performs flexible downstream analysis with Python. This design combines the efficiency of SQL over large databases with the flexibility of Python-based analysis, while reducing reliance on unreliable metadata and improving robustness across SQL dialects. Experiments on Spider 2.0-Lite and Spider 2.0-Snow show that ProSPy consistently outperforms strong baselines with both open-source and proprietary models, achieving execution accuracies of 60.15% and 60.51% with Claude-4.5-Opus, without majority voting. Further analysis shows that ProSPy is robust to SQL dialect variations and achieves a favorable trade-off between schema recall and precision.
EviLink: Multi-Path Schema Linking with Uncertainty-Guided Evidence Acquisition for Large-Scale Text-to-SQL
May 28, 2026Schema linking is a difficult and important step in large-scale Text-to-SQL, where systems must identify a compact yet sufficient schema context from large and ambiguous databases. Existing methods often treat schema linking as deterministic selection around a single SQL path, but complex questions may admit multiple valid realizations with different schema needs. We reframe schema linking as uncertainty-aware schema-need inference over multiple plausible SQL paths, where the system distinguishes required schema items from path-dependent uncertain ones and acquires evidence only where needed. We instantiate this reframing with EviLink, which combines multi-hypothesis schema grounding with uncertainty-guided evidence acquisition. Experiments on BIRD-Dev and Spider2-Snow show that this perspective improves the balance among schema completeness, schema relevance, and token cost. On Spider2-Snow, EviLink achieves 90.15% field-level strict recall rate, uses 123.30K average tokens, and improves downstream SQL generation under a fixed generator.
Can Vision Language Models Assess Graphic Design Aesthetics? A Benchmark, Evaluation, and Dataset Perspective
Mar 01, 2026Assessing the aesthetic quality of graphic design is central to visual communication, yet remains underexplored in vision language models (VLMs). We investigate whether VLMs can evaluate design aesthetics in ways comparable to humans. Prior work faces three key limitations: benchmarks restricted to narrow principles and coarse evaluation protocols, a lack of systematic VLM comparisons, and limited training data for model improvement. In this work, we introduce AesEval-Bench, a comprehensive benchmark spanning four dimensions, twelve indicators, and three fully quantifiable tasks: aesthetic judgment, region selection, and precise localization. Then, we systematically evaluate proprietary, open-source, and reasoning-augmented VLMs, revealing clear performance gaps against the nuanced demands of aesthetic assessment. Moreover, we construct a training dataset to fine-tune VLMs for this domain, leveraging human-guided VLM labeling to produce task labels at scale and indicator-grounded reasoning to tie abstract indicators to concrete design regions.Together, our work establishes the first systematic framework for aesthetic quality assessment in graphic design. Our code and dataset will be released at: \href{https://github.com/arctanxarc/AesEval-Bench}{https://github.com/arctanxarc/AesEval-Bench}
ReLayout: Versatile and Structure-Preserving Design Layout Editing via Relation-Aware Design Reconstruction
Feb 01, 2026Automated redesign without manual adjustments marks a key step forward in the design workflow. In this work, we focus on a foundational redesign task termed design layout editing, which seeks to autonomously modify the geometric composition of a design based on user intents. To overcome the ambiguity of user needs expressed in natural language, we introduce four basic and important editing actions and standardize the format of editing operations. The underexplored task presents a unique challenge: satisfying specified editing operations while simultaneously preserving the layout structure of unedited elements. Besides, the scarcity of triplet (original design, editing operation, edited design) samples poses another formidable challenge. To this end, we present ReLayout, a novel framework for versatile and structure-preserving design layout editing that operates without triplet data. Specifically, ReLayout first introduces the relation graph, which contains the position and size relationships among unedited elements, as the constraint for layout structure preservation. Then, relation-aware design reconstruction (RADR) is proposed to bypass the data challenge. By learning to reconstruct a design from its elements, a relation graph, and a synthesized editing operation, RADR effectively emulates the editing process in a self-supervised manner. A multi-modal large language model serves as the backbone for RADR, unifying multiple editing actions within a single model and thus achieving versatile editing after fine-tuning. Qualitative, quantitative results and user studies show that ReLayout significantly outperforms the baseline models in terms of editing quality, accuracy, and layout structure preservation.
BizGen: Advancing Article-level Visual Text Rendering for Infographics Generation
Mar 26, 2025Recently, state-of-the-art text-to-image generation models, such as Flux and Ideogram 2.0, have made significant progress in sentence-level visual text rendering. In this paper, we focus on the more challenging scenarios of article-level visual text rendering and address a novel task of generating high-quality business content, including infographics and slides, based on user provided article-level descriptive prompts and ultra-dense layouts. The fundamental challenges are twofold: significantly longer context lengths and the scarcity of high-quality business content data. In contrast to most previous works that focus on a limited number of sub-regions and sentence-level prompts, ensuring precise adherence to ultra-dense layouts with tens or even hundreds of sub-regions in business content is far more challenging. We make two key technical contributions: (i) the construction of scalable, high-quality business content dataset, i.e., Infographics-650K, equipped with ultra-dense layouts and prompts by implementing a layer-wise retrieval-augmented infographic generation scheme; and (ii) a layout-guided cross attention scheme, which injects tens of region-wise prompts into a set of cropped region latent space according to the ultra-dense layouts, and refine each sub-regions flexibly during inference using a layout conditional CFG. We demonstrate the strong results of our system compared to previous SOTA systems such as Flux and SD3 on our BizEval prompt set. Additionally, we conduct thorough ablation experiments to verify the effectiveness of each component. We hope our constructed Infographics-650K and BizEval can encourage the broader community to advance the progress of business content generation.
From Elements to Design: A Layered Approach for Automatic Graphic Design Composition
Dec 27, 2024In this work, we investigate automatic design composition from multimodal graphic elements. Although recent studies have developed various generative models for graphic design, they usually face the following limitations: they only focus on certain subtasks and are far from achieving the design composition task; they do not consider the hierarchical information of graphic designs during the generation process. To tackle these issues, we introduce the layered design principle into Large Multimodal Models (LMMs) and propose a novel approach, called LaDeCo, to accomplish this challenging task. Specifically, LaDeCo first performs layer planning for a given element set, dividing the input elements into different semantic layers according to their contents. Based on the planning results, it subsequently predicts element attributes that control the design composition in a layer-wise manner, and includes the rendered image of previously generated layers into the context. With this insightful design, LaDeCo decomposes the difficult task into smaller manageable steps, making the generation process smoother and clearer. The experimental results demonstrate the effectiveness of LaDeCo in design composition. Furthermore, we show that LaDeCo enables some interesting applications in graphic design, such as resolution adjustment, element filling, design variation, etc. In addition, it even outperforms the specialized models in some design subtasks without any task-specific training.
DataLab: A Unified Platform for LLM-Powered Business Intelligence
Dec 04, 2024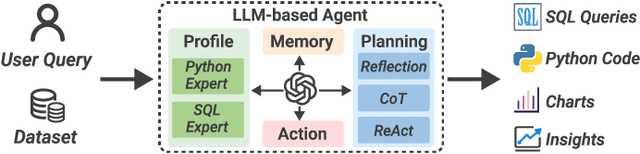
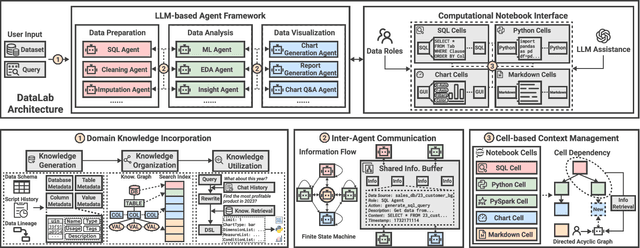
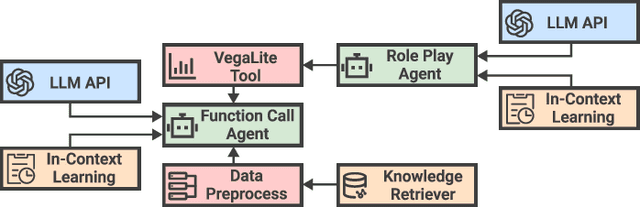
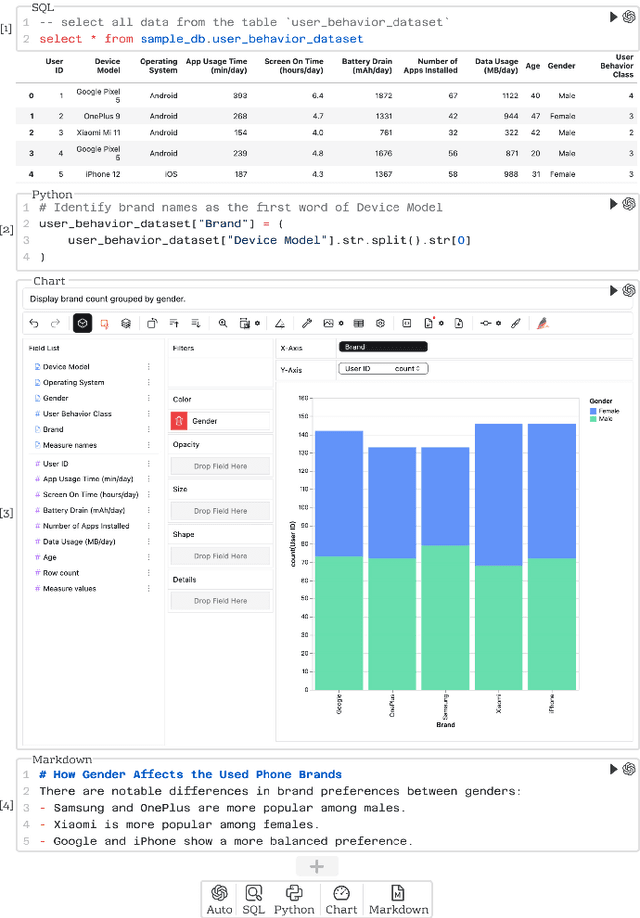
Business intelligence (BI) transforms large volumes of data within modern organizations into actionable insights for informed decision-making. Recently, large language model (LLM)-based agents have streamlined the BI workflow by automatically performing task planning, reasoning, and actions in executable environments based on natural language (NL) queries. However, existing approaches primarily focus on individual BI tasks such as NL2SQL and NL2VIS. The fragmentation of tasks across different data roles and tools lead to inefficiencies and potential errors due to the iterative and collaborative nature of BI. In this paper, we introduce DataLab, a unified BI platform that integrates a one-stop LLM-based agent framework with an augmented computational notebook interface. DataLab supports a wide range of BI tasks for different data roles by seamlessly combining LLM assistance with user customization within a single environment. To achieve this unification, we design a domain knowledge incorporation module tailored for enterprise-specific BI tasks, an inter-agent communication mechanism to facilitate information sharing across the BI workflow, and a cell-based context management strategy to enhance context utilization efficiency in BI notebooks. Extensive experiments demonstrate that DataLab achieves state-of-the-art performance on various BI tasks across popular research benchmarks. Moreover, DataLab maintains high effectiveness and efficiency on real-world datasets from Tencent, achieving up to a 58.58% increase in accuracy and a 61.65% reduction in token cost on enterprise-specific BI tasks.
DataLab: A Unifed Platform for LLM-Powered Business Intelligence
Dec 03, 2024Business intelligence (BI) transforms large volumes of data within modern organizations into actionable insights for informed decision-making. Recently, large language model (LLM)-based agents have streamlined the BI workflow by automatically performing task planning, reasoning, and actions in executable environments based on natural language (NL) queries. However, existing approaches primarily focus on individual BI tasks such as NL2SQL and NL2VIS. The fragmentation of tasks across different data roles and tools lead to inefficiencies and potential errors due to the iterative and collaborative nature of BI. In this paper, we introduce DataLab, a unified BI platform that integrates a one-stop LLM-based agent framework with an augmented computational notebook interface. DataLab supports a wide range of BI tasks for different data roles by seamlessly combining LLM assistance with user customization within a single environment. To achieve this unification, we design a domain knowledge incorporation module tailored for enterprise-specific BI tasks, an inter-agent communication mechanism to facilitate information sharing across the BI workflow, and a cell-based context management strategy to enhance context utilization efficiency in BI notebooks. Extensive experiments demonstrate that DataLab achieves state-of-the-art performance on various BI tasks across popular research benchmarks. Moreover, DataLab maintains high effectiveness and efficiency on real-world datasets from Tencent, achieving up to a 58.58% increase in accuracy and a 61.65% reduction in token cost on enterprise-specific BI tasks.
DesignProbe: A Graphic Design Benchmark for Multimodal Large Language Models
Apr 23, 2024A well-executed graphic design typically achieves harmony in two levels, from the fine-grained design elements (color, font and layout) to the overall design. This complexity makes the comprehension of graphic design challenging, for it needs the capability to both recognize the design elements and understand the design. With the rapid development of Multimodal Large Language Models (MLLMs), we establish the DesignProbe, a benchmark to investigate the capability of MLLMs in design. Our benchmark includes eight tasks in total, across both the fine-grained element level and the overall design level. At design element level, we consider both the attribute recognition and semantic understanding tasks. At overall design level, we include style and metaphor. 9 MLLMs are tested and we apply GPT-4 as evaluator. Besides, further experiments indicates that refining prompts can enhance the performance of MLLMs. We first rewrite the prompts by different LLMs and found increased performances appear in those who self-refined by their own LLMs. We then add extra task knowledge in two different ways (text descriptions and image examples), finding that adding images boost much more performance over texts.
Desigen: A Pipeline for Controllable Design Template Generation
Mar 14, 2024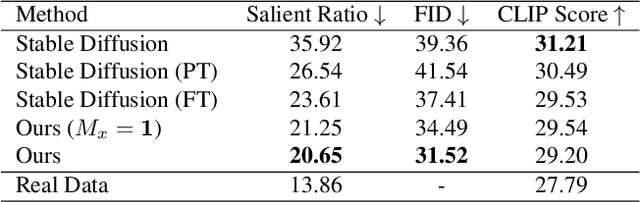
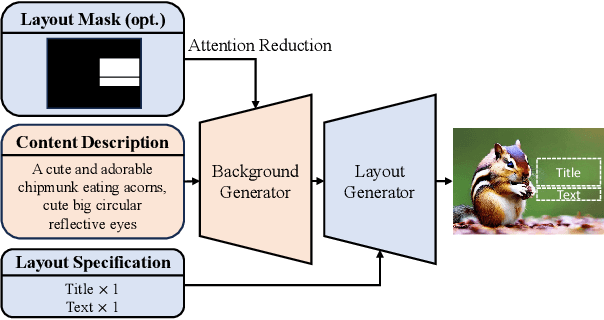
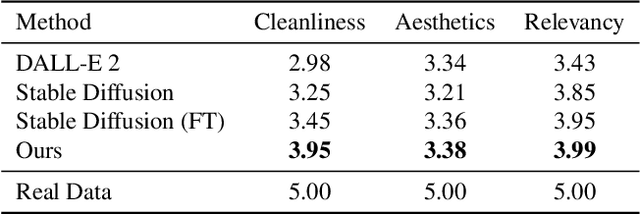
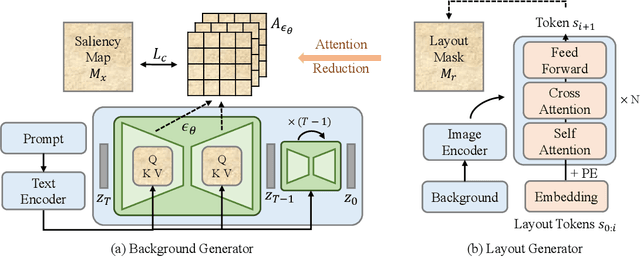
Templates serve as a good starting point to implement a design (e.g., banner, slide) but it takes great effort from designers to manually create. In this paper, we present Desigen, an automatic template creation pipeline which generates background images as well as harmonious layout elements over the background. Different from natural images, a background image should preserve enough non-salient space for the overlaying layout elements. To equip existing advanced diffusion-based models with stronger spatial control, we propose two simple but effective techniques to constrain the saliency distribution and reduce the attention weight in desired regions during the background generation process. Then conditioned on the background, we synthesize the layout with a Transformer-based autoregressive generator. To achieve a more harmonious composition, we propose an iterative inference strategy to adjust the synthesized background and layout in multiple rounds. We constructed a design dataset with more than 40k advertisement banners to verify our approach. Extensive experiments demonstrate that the proposed pipeline generates high-quality templates comparable to human designers. More than a single-page design, we further show an application of presentation generation that outputs a set of theme-consistent slides. The data and code are available at https://whaohan.github.io/desigen.