 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProSPy: A Profiling-Driven SQL-Python Agentic Framework for Enterprise Text-to-SQL
Jun 04, 2026Large language models have substantially advanced Text-to-SQL systems, yet applying them to enterprise-scale databases remains challenging. Real-world databases often contain large and heterogeneous schemas, incomplete metadata, dialect-specific SQL syntax, and complex analytical questions that are difficult to solve with a single SQL query. To address these challenges, we propose ProSPy, a Profiling-driven SQL--Python agentic framework for enterprise-scale Text-to-SQL. ProSPy structures the reasoning process into four stages: it first extracts fine-grained data evidence through automatic profiling, progressively prunes large schemas into task-relevant contexts, fetches intermediate views through a dialect-agnostic SQL interface, and finally performs flexible downstream analysis with Python. This design combines the efficiency of SQL over large databases with the flexibility of Python-based analysis, while reducing reliance on unreliable metadata and improving robustness across SQL dialects. Experiments on Spider 2.0-Lite and Spider 2.0-Snow show that ProSPy consistently outperforms strong baselines with both open-source and proprietary models, achieving execution accuracies of 60.15% and 60.51% with Claude-4.5-Opus, without majority voting. Further analysis shows that ProSPy is robust to SQL dialect variations and achieves a favorable trade-off between schema recall and precision.
EviLink: Multi-Path Schema Linking with Uncertainty-Guided Evidence Acquisition for Large-Scale Text-to-SQL
May 28, 2026Schema linking is a difficult and important step in large-scale Text-to-SQL, where systems must identify a compact yet sufficient schema context from large and ambiguous databases. Existing methods often treat schema linking as deterministic selection around a single SQL path, but complex questions may admit multiple valid realizations with different schema needs. We reframe schema linking as uncertainty-aware schema-need inference over multiple plausible SQL paths, where the system distinguishes required schema items from path-dependent uncertain ones and acquires evidence only where needed. We instantiate this reframing with EviLink, which combines multi-hypothesis schema grounding with uncertainty-guided evidence acquisition. Experiments on BIRD-Dev and Spider2-Snow show that this perspective improves the balance among schema completeness, schema relevance, and token cost. On Spider2-Snow, EviLink achieves 90.15% field-level strict recall rate, uses 123.30K average tokens, and improves downstream SQL generation under a fixed generator.
A Causal Perspective for Enhancing Jailbreak Attack and Defense
Jan 31, 2026Uncovering the mechanisms behind "jailbreaks" in large language models (LLMs) is crucial for enhancing their safety and reliability, yet these mechanisms remain poorly understood. Existing studies predominantly analyze jailbreak prompts by probing latent representations, often overlooking the causal relationships between interpretable prompt features and jailbreak occurrences. In this work, we propose Causal Analyst, a framework that integrates LLMs into data-driven causal discovery to identify the direct causes of jailbreaks and leverage them for both attack and defense. We introduce a comprehensive dataset comprising 35k jailbreak attempts across seven LLMs, systematically constructed from 100 attack templates and 50 harmful queries, annotated with 37 meticulously designed human-readable prompt features. By jointly training LLM-based prompt encoding and GNN-based causal graph learning, we reconstruct causal pathways linking prompt features to jailbreak responses. Our analysis reveals that specific features, such as "Positive Character" and "Number of Task Steps", act as direct causal drivers of jailbreaks. We demonstrate the practical utility of these insights through two applications: (1) a Jailbreaking Enhancer that targets identified causal features to significantly boost attack success rates on public benchmarks, and (2) a Guardrail Advisor that utilizes the learned causal graph to extract true malicious intent from obfuscated queries. Extensive experiments, including baseline comparisons and causal structure validation, confirm the robustness of our causal analysis and its superiority over non-causal approaches. Our results suggest that analyzing jailbreak features from a causal perspective is an effective and interpretable approach for improving LLM reliability. Our code is available at https://github.com/Master-PLC/Causal-Analyst.
DataLab: A Unified Platform for LLM-Powered Business Intelligence
Dec 04, 2024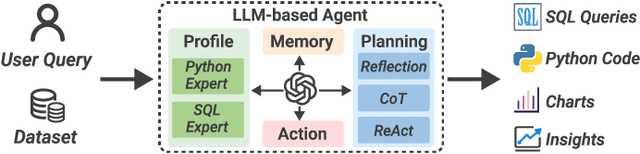
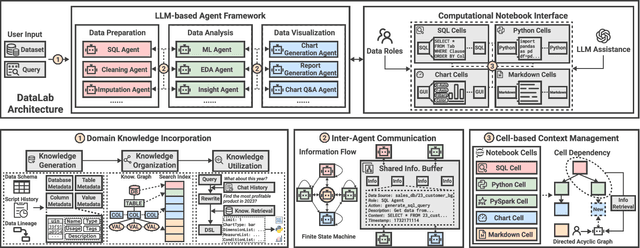
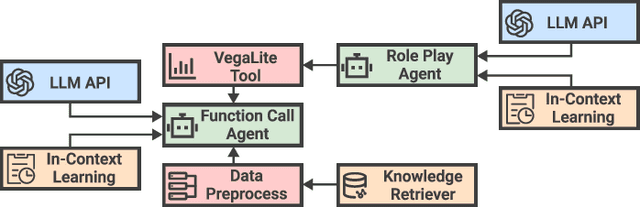
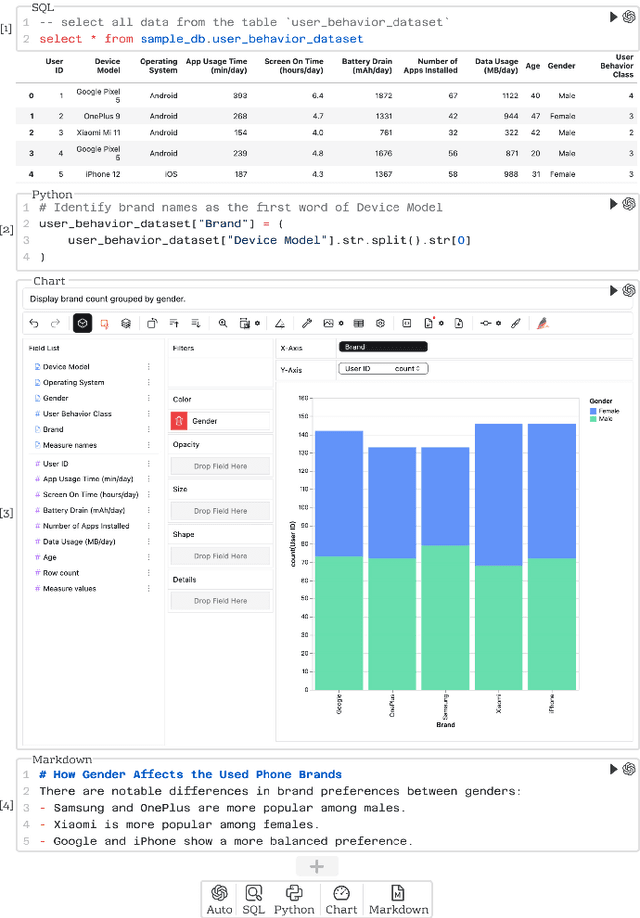
Business intelligence (BI) transforms large volumes of data within modern organizations into actionable insights for informed decision-making. Recently, large language model (LLM)-based agents have streamlined the BI workflow by automatically performing task planning, reasoning, and actions in executable environments based on natural language (NL) queries. However, existing approaches primarily focus on individual BI tasks such as NL2SQL and NL2VIS. The fragmentation of tasks across different data roles and tools lead to inefficiencies and potential errors due to the iterative and collaborative nature of BI. In this paper, we introduce DataLab, a unified BI platform that integrates a one-stop LLM-based agent framework with an augmented computational notebook interface. DataLab supports a wide range of BI tasks for different data roles by seamlessly combining LLM assistance with user customization within a single environment. To achieve this unification, we design a domain knowledge incorporation module tailored for enterprise-specific BI tasks, an inter-agent communication mechanism to facilitate information sharing across the BI workflow, and a cell-based context management strategy to enhance context utilization efficiency in BI notebooks. Extensive experiments demonstrate that DataLab achieves state-of-the-art performance on various BI tasks across popular research benchmarks. Moreover, DataLab maintains high effectiveness and efficiency on real-world datasets from Tencent, achieving up to a 58.58% increase in accuracy and a 61.65% reduction in token cost on enterprise-specific BI tasks.
DataLab: A Unifed Platform for LLM-Powered Business Intelligence
Dec 03, 2024Business intelligence (BI) transforms large volumes of data within modern organizations into actionable insights for informed decision-making. Recently, large language model (LLM)-based agents have streamlined the BI workflow by automatically performing task planning, reasoning, and actions in executable environments based on natural language (NL) queries. However, existing approaches primarily focus on individual BI tasks such as NL2SQL and NL2VIS. The fragmentation of tasks across different data roles and tools lead to inefficiencies and potential errors due to the iterative and collaborative nature of BI. In this paper, we introduce DataLab, a unified BI platform that integrates a one-stop LLM-based agent framework with an augmented computational notebook interface. DataLab supports a wide range of BI tasks for different data roles by seamlessly combining LLM assistance with user customization within a single environment. To achieve this unification, we design a domain knowledge incorporation module tailored for enterprise-specific BI tasks, an inter-agent communication mechanism to facilitate information sharing across the BI workflow, and a cell-based context management strategy to enhance context utilization efficiency in BI notebooks. Extensive experiments demonstrate that DataLab achieves state-of-the-art performance on various BI tasks across popular research benchmarks. Moreover, DataLab maintains high effectiveness and efficiency on real-world datasets from Tencent, achieving up to a 58.58% increase in accuracy and a 61.65% reduction in token cost on enterprise-specific BI tasks.
Self-Distillation Bridges Distribution Gap in Language Model Fine-Tuning
Feb 21, 2024



The surge in Large Language Models (LLMs) has revolutionized natural language processing, but fine-tuning them for specific tasks often encounters challenges in balancing performance and preserving general instruction-following abilities. In this paper, we posit that the distribution gap between task datasets and the LLMs serves as the primary underlying cause. To address the problem, we introduce Self-Distillation Fine-Tuning (SDFT), a novel approach that bridges the distribution gap by guiding fine-tuning with a distilled dataset generated by the model itself to match its original distribution. Experimental results on the Llama-2-chat model across various benchmarks demonstrate that SDFT effectively mitigates catastrophic forgetting while achieving comparable or superior performance on downstream tasks compared to the vanilla fine-tuning. Moreover, SDFT demonstrates the potential to maintain the helpfulness and safety alignment of LLMs. Our code is available at \url{https://github.com/sail-sg/sdft}.
CoSDA: Continual Source-Free Domain Adaptation
Apr 13, 2023



Without access to the source data, source-free domain adaptation (SFDA) transfers knowledge from a source-domain trained model to target domains. Recently, SFDA has gained popularity due to the need to protect the data privacy of the source domain, but it suffers from catastrophic forgetting on the source domain due to the lack of data. To systematically investigate the mechanism of catastrophic forgetting, we first reimplement previous SFDA approaches within a unified framework and evaluate them on four benchmarks. We observe that there is a trade-off between adaptation gain and forgetting loss, which motivates us to design a consistency regularization to mitigate forgetting. In particular, we propose a continual source-free domain adaptation approach named CoSDA, which employs a dual-speed optimized teacher-student model pair and is equipped with consistency learning capability. Our experiments demonstrate that CoSDA outperforms state-of-the-art approaches in continuous adaptation. Notably, our CoSDA can also be integrated with other SFDA methods to alleviate forgetting.
Does Federated Learning Really Need Backpropagation?
Jan 28, 2023Federated learning (FL) is a general principle for decentralized clients to train a server model collectively without sharing local data. FL is a promising framework with practical applications, but its standard training paradigm requires the clients to backpropagate through the model to compute gradients. Since these clients are typically edge devices and not fully trusted, executing backpropagation on them incurs computational and storage overhead as well as white-box vulnerability. In light of this, we develop backpropagation-free federated learning, dubbed BAFFLE, in which backpropagation is replaced by multiple forward processes to estimate gradients. BAFFLE is 1) memory-efficient and easily fits uploading bandwidth; 2) compatible with inference-only hardware optimization and model quantization or pruning; and 3) well-suited to trusted execution environments, because the clients in BAFFLE only execute forward propagation and return a set of scalars to the server. Empirically we use BAFFLE to train deep models from scratch or to finetune pretrained models, achieving acceptable results. Code is available in https://github.com/FengHZ/BAFFLE.
An Interactive Insight Identification and Annotation Framework for Power Grid Pixel Maps using DenseU-Hierarchical VAE
May 22, 2019
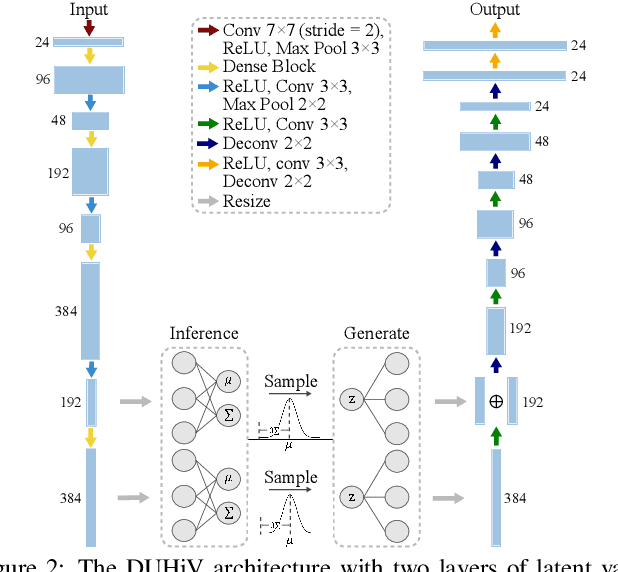


Insights in power grid pixel maps (PGPMs) refer to important facility operating states and unexpected changes in the power grid. Identifying insights helps analysts understand the collaboration of various parts of the grid so that preventive and correct operations can be taken to avoid potential accidents. Existing solutions for identifying insights in PGPMs are performed manually, which may be laborious and expertise-dependent. In this paper, we propose an interactive insight identification and annotation framework by leveraging an enhanced variational autoencoder (VAE). In particular, a new architecture, DenseU-Hierarchical VAE (DUHiV), is designed to learn representations from large-sized PGPMs, which achieves a significantly tighter evidence lower bound (ELBO) than existing Hierarchical VAEs with a Multilayer Perceptron architecture. Our approach supports modulating the derived representations in an interactive visual interface, discover potential insights and create multi-label annotations. Evaluations using real-world PGPMs datasets show that our framework outperforms the baseline models in identifying and annotating insights.