 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Membership Inference in Intermediate Representations via Layer-wise MIA-risk-aware DP-SGD
Feb 26, 2026In Embedding-as-an-Interface (EaaI) settings, pre-trained models are queried for Intermediate Representations (IRs). The distributional properties of IRs can leak training-set membership signals, enabling Membership Inference Attacks (MIAs) whose strength varies across layers. Although Differentially Private Stochastic Gradient Descent (DP-SGD) mitigates such leakage, existing implementations employ per-example gradient clipping and a uniform, layer-agnostic noise multiplier, ignoring heterogeneous layer-wise MIA vulnerability. This paper introduces Layer-wise MIA-risk-aware DP-SGD (LM-DP-SGD), which adaptively allocates privacy protection across layers in proportion to their MIA risk. Specifically, LM-DP-SGD trains a shadow model on a public shadow dataset, extracts per-layer IRs from its train/test splits, and fits layer-specific MIA adversaries, using their attack error rates as MIA-risk estimates. Leveraging the cross-dataset transferability of MIAs, these estimates are then used to reweight each layer's contribution to the globally clipped gradient during private training, providing layer-appropriate protection under a fixed noise magnitude. We further establish theoretical guarantees on both privacy and convergence of LM-DP-SGD. Extensive experiments show that, under the same privacy budget, LM-DP-SGD reduces the peak IR-level MIA risk while preserving utility, yielding a superior privacy-utility trade-off.
DP-aware AdaLN-Zero: Taming Conditioning-Induced Heavy-Tailed Gradients in Differentially Private Diffusion
Feb 26, 2026Condition injection enables diffusion models to generate context-aware outputs, which is essential for many time-series tasks. However, heterogeneous conditional contexts (e.g., observed history, missingness patterns or outlier covariates) can induce heavy-tailed per-example gradients. Under Differentially Private Stochastic Gradient Descent (DP-SGD), these rare conditioning-driven heavy-tailed gradients disproportionately trigger global clipping, resulting in outlier-dominated updates, larger clipping bias, and degraded utility under a fixed privacy budget. In this paper, we propose DP-aware AdaLN-Zero, a drop-in sensitivity-aware conditioning mechanism for conditional diffusion transformers that limits conditioning-induced gain without modifying the DP-SGD mechanism. DP-aware AdaLN-Zero jointly constrains conditioning representation magnitude and AdaLN modulation parameters via bounded re-parameterization, suppressing extreme gradient tail events before gradient clipping and noise injection. Empirically, DP-SGD equipped with DP-aware AdaLN-Zero improves interpolation/imputation and forecasting under matched privacy settings. We observe consistent gains on a real-world power dataset and two public ETT benchmarks over vanilla DP-SGD. Moreover, gradient diagnostics attribute these improvements to conditioning-specific tail reshaping and reduced clipping distortion, while preserving expressiveness in non-private training. Overall, these results show that sensitivity-aware conditioning can substantially improve private conditional diffusion training without sacrificing standard performance.
Real-Time Privacy Risk Measurement with Privacy Tokens for Gradient Leakage
Feb 07, 2025



The widespread deployment of deep learning models in privacy-sensitive domains has amplified concerns regarding privacy risks, particularly those stemming from gradient leakage during training. Current privacy assessments primarily rely on post-training attack simulations. However, these methods are inherently reactive, unable to encompass all potential attack scenarios, and often based on idealized adversarial assumptions. These limitations underscore the need for proactive approaches to privacy risk assessment during the training process. To address this gap, we propose the concept of privacy tokens, which are derived directly from private gradients during training. Privacy tokens encapsulate gradient features and, when combined with data features, offer valuable insights into the extent of private information leakage from training data, enabling real-time measurement of privacy risks without relying on adversarial attack simulations. Additionally, we employ Mutual Information (MI) as a robust metric to quantify the relationship between training data and gradients, providing precise and continuous assessments of privacy leakage throughout the training process. Extensive experiments validate our framework, demonstrating the effectiveness of privacy tokens and MI in identifying and quantifying privacy risks. This proactive approach marks a significant advancement in privacy monitoring, promoting the safer deployment of deep learning models in sensitive applications.
Privacy Token: Surprised to Find Out What You Accidentally Revealed
Feb 06, 2025The widespread deployment of deep learning models in privacy-sensitive domains has amplified concerns regarding privacy risks, particularly those stemming from gradient leakage during training. Current privacy assessments primarily rely on post-training attack simulations. However, these methods are inherently reactive, unable to encompass all potential attack scenarios, and often based on idealized adversarial assumptions. These limitations underscore the need for proactive approaches to privacy risk assessment during the training process. To address this gap, we propose the concept of privacy tokens, which are derived directly from private gradients during training. Privacy tokens encapsulate gradient features and, when combined with data features, offer valuable insights into the extent of private information leakage from training data, enabling real-time measurement of privacy risks without relying on adversarial attack simulations. Additionally, we employ Mutual Information (MI) as a robust metric to quantify the relationship between training data and gradients, providing precise and continuous assessments of privacy leakage throughout the training process. Extensive experiments validate our framework, demonstrating the effectiveness of privacy tokens and MI in identifying and quantifying privacy risks. This proactive approach marks a significant advancement in privacy monitoring, promoting the safer deployment of deep learning models in sensitive applications.
TIV-Diffusion: Towards Object-Centric Movement for Text-driven Image to Video Generation
Dec 13, 2024



Text-driven Image to Video Generation (TI2V) aims to generate controllable video given the first frame and corresponding textual description. The primary challenges of this task lie in two parts: (i) how to identify the target objects and ensure the consistency between the movement trajectory and the textual description. (ii) how to improve the subjective quality of generated videos. To tackle the above challenges, we propose a new diffusion-based TI2V framework, termed TIV-Diffusion, via object-centric textual-visual alignment, intending to achieve precise control and high-quality video generation based on textual-described motion for different objects. Concretely, we enable our TIV-Diffuion model to perceive the textual-described objects and their motion trajectory by incorporating the fused textual and visual knowledge through scale-offset modulation. Moreover, to mitigate the problems of object disappearance and misaligned objects and motion, we introduce an object-centric textual-visual alignment module, which reduces the risk of misaligned objects/motion by decoupling the objects in the reference image and aligning textual features with each object individually. Based on the above innovations, our TIV-Diffusion achieves state-of-the-art high-quality video generation compared with existing TI2V methods.
DataLab: A Unified Platform for LLM-Powered Business Intelligence
Dec 04, 2024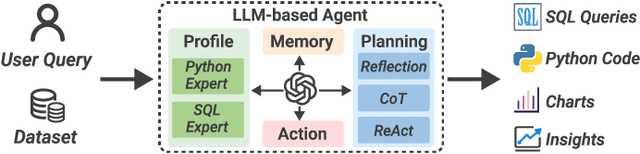
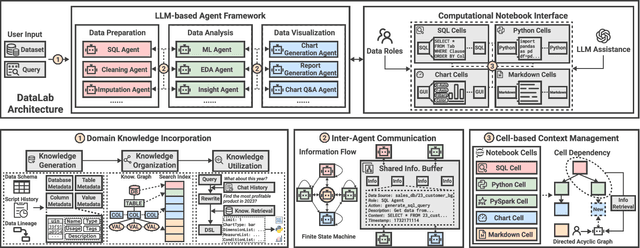
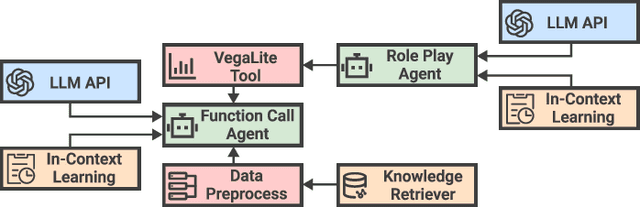
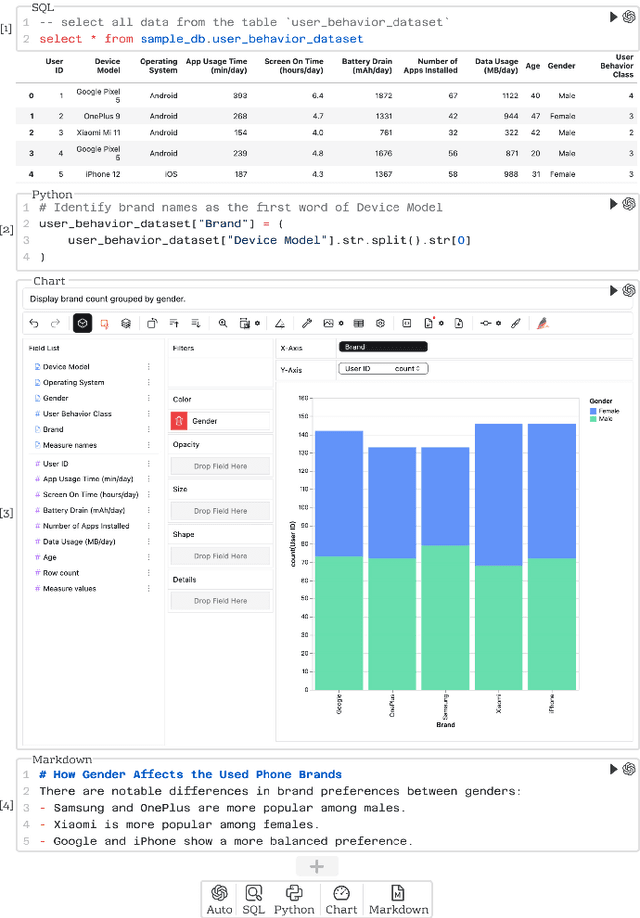
Business intelligence (BI) transforms large volumes of data within modern organizations into actionable insights for informed decision-making. Recently, large language model (LLM)-based agents have streamlined the BI workflow by automatically performing task planning, reasoning, and actions in executable environments based on natural language (NL) queries. However, existing approaches primarily focus on individual BI tasks such as NL2SQL and NL2VIS. The fragmentation of tasks across different data roles and tools lead to inefficiencies and potential errors due to the iterative and collaborative nature of BI. In this paper, we introduce DataLab, a unified BI platform that integrates a one-stop LLM-based agent framework with an augmented computational notebook interface. DataLab supports a wide range of BI tasks for different data roles by seamlessly combining LLM assistance with user customization within a single environment. To achieve this unification, we design a domain knowledge incorporation module tailored for enterprise-specific BI tasks, an inter-agent communication mechanism to facilitate information sharing across the BI workflow, and a cell-based context management strategy to enhance context utilization efficiency in BI notebooks. Extensive experiments demonstrate that DataLab achieves state-of-the-art performance on various BI tasks across popular research benchmarks. Moreover, DataLab maintains high effectiveness and efficiency on real-world datasets from Tencent, achieving up to a 58.58% increase in accuracy and a 61.65% reduction in token cost on enterprise-specific BI tasks.
DataLab: A Unifed Platform for LLM-Powered Business Intelligence
Dec 03, 2024Business intelligence (BI) transforms large volumes of data within modern organizations into actionable insights for informed decision-making. Recently, large language model (LLM)-based agents have streamlined the BI workflow by automatically performing task planning, reasoning, and actions in executable environments based on natural language (NL) queries. However, existing approaches primarily focus on individual BI tasks such as NL2SQL and NL2VIS. The fragmentation of tasks across different data roles and tools lead to inefficiencies and potential errors due to the iterative and collaborative nature of BI. In this paper, we introduce DataLab, a unified BI platform that integrates a one-stop LLM-based agent framework with an augmented computational notebook interface. DataLab supports a wide range of BI tasks for different data roles by seamlessly combining LLM assistance with user customization within a single environment. To achieve this unification, we design a domain knowledge incorporation module tailored for enterprise-specific BI tasks, an inter-agent communication mechanism to facilitate information sharing across the BI workflow, and a cell-based context management strategy to enhance context utilization efficiency in BI notebooks. Extensive experiments demonstrate that DataLab achieves state-of-the-art performance on various BI tasks across popular research benchmarks. Moreover, DataLab maintains high effectiveness and efficiency on real-world datasets from Tencent, achieving up to a 58.58% increase in accuracy and a 61.65% reduction in token cost on enterprise-specific BI tasks.
Training-free Camera Control for Video Generation
Jun 14, 2024
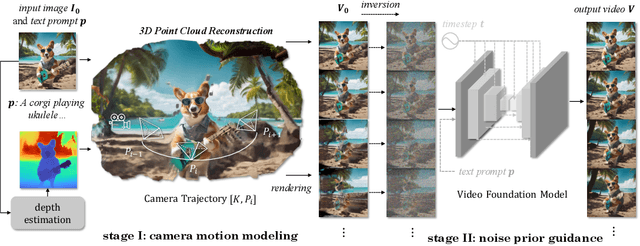
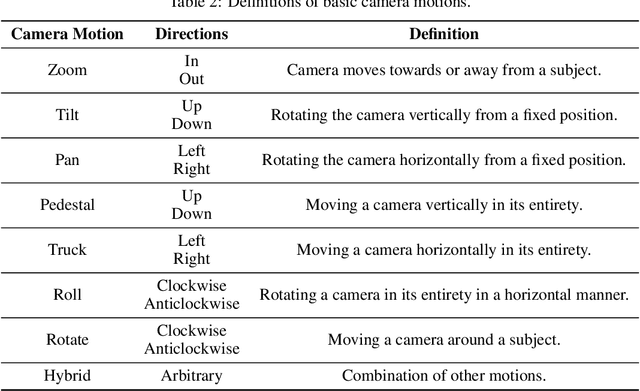
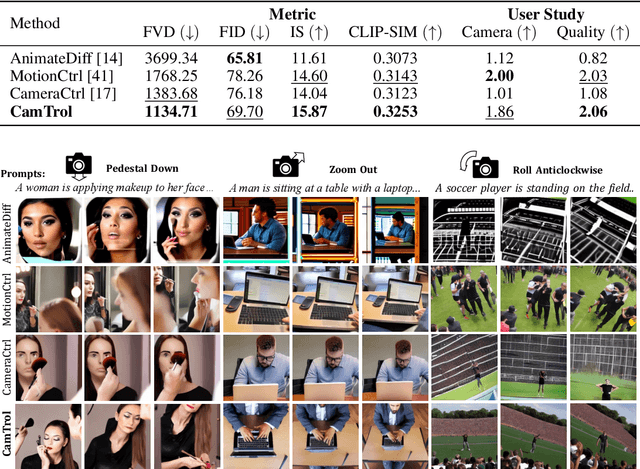
We propose a training-free and robust solution to offer camera movement control for off-the-shelf video diffusion models. Unlike previous work, our method does not require any supervised finetuning on camera-annotated datasets or self-supervised training via data augmentation. Instead, it can be plugged and played with most pretrained video diffusion models and generate camera controllable videos with a single image or text prompt as input. The inspiration of our work comes from the layout prior that intermediate latents hold towards generated results, thus rearranging noisy pixels in them will make output content reallocated as well. As camera move could also be seen as a kind of pixel rearrangement caused by perspective change, videos could be reorganized following specific camera motion if their noisy latents change accordingly. Established on this, we propose our method CamTrol, which enables robust camera control for video diffusion models. It is achieved by a two-stage process. First, we model image layout rearrangement through explicit camera movement in 3D point cloud space. Second, we generate videos with camera motion using layout prior of noisy latents formed by a series of rearranged images. Extensive experiments have demonstrated the robustness our method holds in controlling camera motion of generated videos. Furthermore, we show that our method can produce impressive results in generating 3D rotation videos with dynamic content. Project page at https://lifedecoder.github.io/CamTrol/.
High-Fidelity Diffusion-based Image Editing
Jan 04, 2024
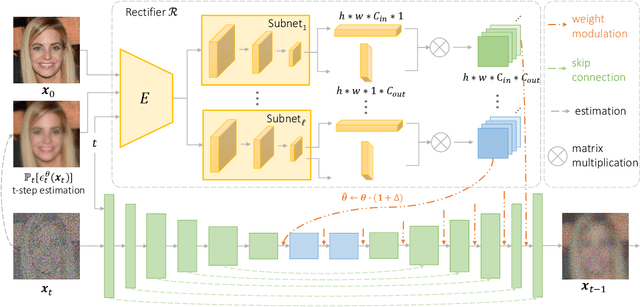

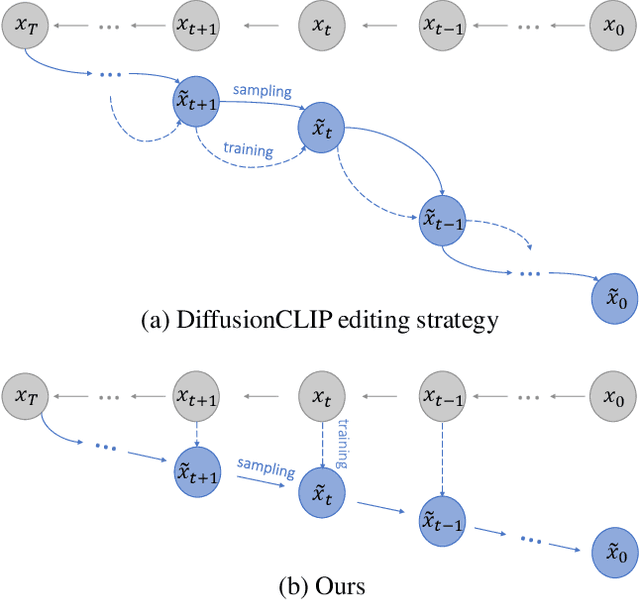
Diffusion models have attained remarkable success in the domains of image generation and editing. It is widely recognized that employing larger inversion and denoising steps in diffusion model leads to improved image reconstruction quality. However, the editing performance of diffusion models tends to be no more satisfactory even with increasing denoising steps. The deficiency in editing could be attributed to the conditional Markovian property of the editing process, where errors accumulate throughout denoising steps. To tackle this challenge, we first propose an innovative framework where a rectifier module is incorporated to modulate diffusion model weights with residual features, thereby providing compensatory information to bridge the fidelity gap. Furthermore, we introduce a novel learning paradigm aimed at minimizing error propagation during the editing process, which trains the editing procedure in a manner similar to denoising score-matching. Extensive experiments demonstrate that our proposed framework and training strategy achieve high-fidelity reconstruction and editing results across various levels of denoising steps, meanwhile exhibits exceptional performance in terms of both quantitative metric and qualitative assessments. Moreover, we explore our model's generalization through several applications like image-to-image translation and out-of-domain image editing.
Adaptive Hypergraph Convolutional Network for No-Reference 360-degree Image Quality Assessment
May 19, 2021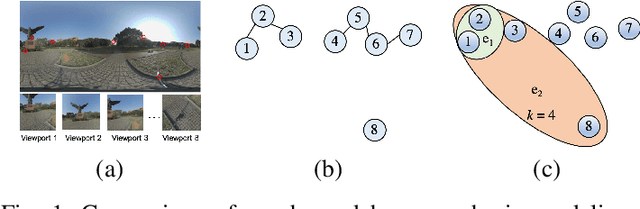
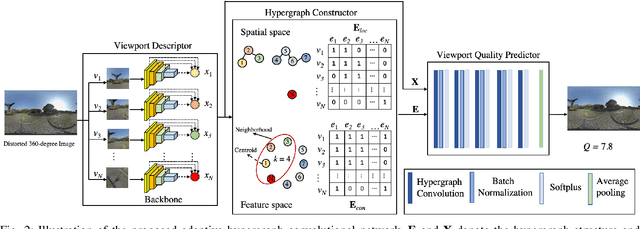
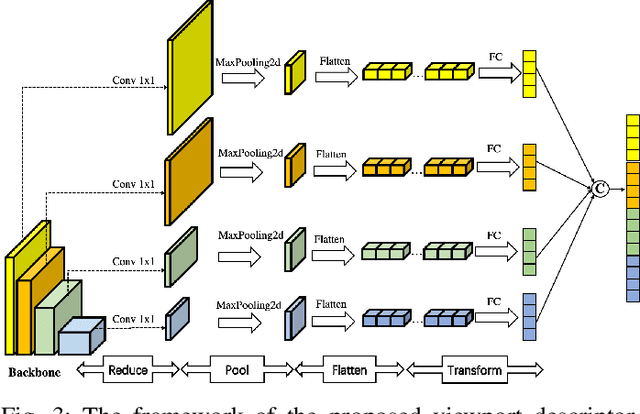
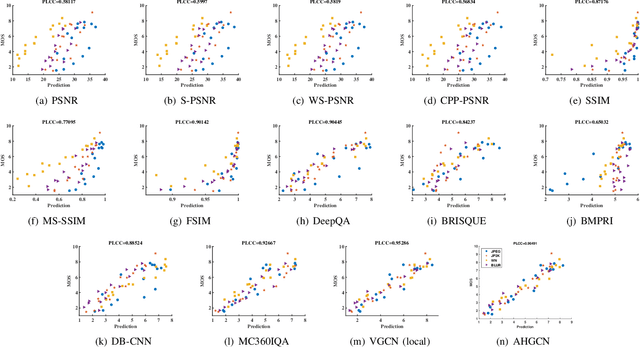
In no-reference 360-degree image quality assessment (NR 360IQA), graph convolutional networks (GCNs), which model interactions between viewports through graphs, have achieved impressive performance. However, prevailing GCN-based NR 360IQA methods suffer from three main limitations. First, they only use high-level features of the distorted image to regress the quality score, while the human visual system (HVS) scores the image based on hierarchical features. Second, they simplify complex high-order interactions between viewports in a pairwise fashion through graphs. Third, in the graph construction, they only consider spatial locations of viewports, ignoring its content characteristics. Accordingly, to address these issues, we propose an adaptive hypergraph convolutional network for NR 360IQA, denoted as AHGCN. Specifically, we first design a multi-level viewport descriptor for extracting hierarchical representations from viewports. Then, we model interactions between viewports through hypergraphs, where each hyperedge connects two or more viewports. In the hypergraph construction, we build a location-based hyperedge and a content-based hyperedge for each viewport. Experimental results on two public 360IQA databases demonstrate that our proposed approach has a clear advantage over state-of-the-art full-reference and no-reference IQA models.