 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-preserving Feature Alignment for Old Photo Colorization
Aug 18, 2025Deep learning techniques have made significant advancements in reference-based colorization by training on large-scale datasets. However, directly applying these methods to the task of colorizing old photos is challenging due to the lack of ground truth and the notorious domain gap between natural gray images and old photos. To address this issue, we propose a novel CNN-based algorithm called SFAC, i.e., Structure-preserving Feature Alignment Colorizer. SFAC is trained on only two images for old photo colorization, eliminating the reliance on big data and allowing direct processing of the old photo itself to overcome the domain gap problem. Our primary objective is to establish semantic correspondence between the two images, ensuring that semantically related objects have similar colors. We achieve this through a feature distribution alignment loss that remains robust to different metric choices. However, utilizing robust semantic correspondence to transfer color from the reference to the old photo can result in inevitable structure distortions. To mitigate this, we introduce a structure-preserving mechanism that incorporates a perceptual constraint at the feature level and a frozen-updated pyramid at the pixel level. Extensive experiments demonstrate the effectiveness of our method for old photo colorization, as confirmed by qualitative and quantitative metrics.
CLIP-DQA: Blindly Evaluating Dehazed Images from Global and Local Perspectives Using CLIP
Feb 03, 2025Blind dehazed image quality assessment (BDQA), which aims to accurately predict the visual quality of dehazed images without any reference information, is essential for the evaluation, comparison, and optimization of image dehazing algorithms. Existing learning-based BDQA methods have achieved remarkable success, while the small scale of DQA datasets limits their performance. To address this issue, in this paper, we propose to adapt Contrastive Language-Image Pre-Training (CLIP), pre-trained on large-scale image-text pairs, to the BDQA task. Specifically, inspired by the fact that the human visual system understands images based on hierarchical features, we take global and local information of the dehazed image as the input of CLIP. To accurately map the input hierarchical information of dehazed images into the quality score, we tune both the vision branch and language branch of CLIP with prompt learning. Experimental results on two authentic DQA datasets demonstrate that our proposed approach, named CLIP-DQA, achieves more accurate quality predictions over existing BDQA methods. The code is available at https://github.com/JunFu1995/CLIP-DQA.
Vision-Language Consistency Guided Multi-modal Prompt Learning for Blind AI Generated Image Quality Assessment
Jun 24, 2024Recently, textual prompt tuning has shown inspirational performance in adapting Contrastive Language-Image Pre-training (CLIP) models to natural image quality assessment. However, such uni-modal prompt learning method only tunes the language branch of CLIP models. This is not enough for adapting CLIP models to AI generated image quality assessment (AGIQA) since AGIs visually differ from natural images. In addition, the consistency between AGIs and user input text prompts, which correlates with the perceptual quality of AGIs, is not investigated to guide AGIQA. In this letter, we propose vision-language consistency guided multi-modal prompt learning for blind AGIQA, dubbed CLIP-AGIQA. Specifically, we introduce learnable textual and visual prompts in language and vision branches of CLIP models, respectively. Moreover, we design a text-to-image alignment quality prediction task, whose learned vision-language consistency knowledge is used to guide the optimization of the above multi-modal prompts. Experimental results on two public AGIQA datasets demonstrate that the proposed method outperforms state-of-the-art quality assessment models. The source code is available at https://github.com/JunFu1995/CLIP-AGIQA.
Variational Disentangled Graph Auto-Encoders for Link Prediction
Jun 20, 2023



With the explosion of graph-structured data, link prediction has emerged as an increasingly important task. Embedding methods for link prediction utilize neural networks to generate node embeddings, which are subsequently employed to predict links between nodes. However, the existing embedding methods typically take a holistic strategy to learn node embeddings and ignore the entanglement of latent factors. As a result, entangled embeddings fail to effectively capture the underlying information and are vulnerable to irrelevant information, leading to unconvincing and uninterpretable link prediction results. To address these challenges, this paper proposes a novel framework with two variants, the disentangled graph auto-encoder (DGAE) and the variational disentangled graph auto-encoder (VDGAE). Our work provides a pioneering effort to apply the disentanglement strategy to link prediction. The proposed framework infers the latent factors that cause edges in the graph and disentangles the representation into multiple channels corresponding to unique latent factors, which contributes to improving the performance of link prediction. To further encourage the embeddings to capture mutually exclusive latent factors, we introduce mutual information regularization to enhance the independence among different channels. Extensive experiments on various real-world benchmarks demonstrate that our proposed methods achieve state-of-the-art results compared to a variety of strong baselines on link prediction tasks. Qualitative analysis on the synthetic dataset also illustrates that the proposed methods can capture distinct latent factors that cause links, providing empirical evidence that our models are able to explain the results of link prediction to some extent. All code will be made publicly available upon publication of the paper.
Contrastive Disentangled Learning on Graph for Node Classification
Jun 20, 2023
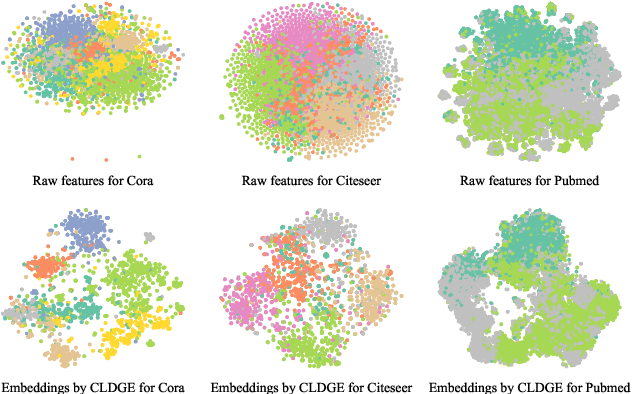

Contrastive learning methods have attracted considerable attention due to their remarkable success in analyzing graph-structured data. Inspired by the success of contrastive learning, we propose a novel framework for contrastive disentangled learning on graphs, employing a disentangled graph encoder and two carefully crafted self-supervision signals. Specifically, we introduce a disentangled graph encoder to enforce the framework to distinguish various latent factors corresponding to underlying semantic information and learn the disentangled node embeddings. Moreover, to overcome the heavy reliance on labels, we design two self-supervision signals, namely node specificity and channel independence, which capture informative knowledge without the need for labeled data, thereby guiding the automatic disentanglement of nodes. Finally, we perform node classification tasks on three citation networks by using the disentangled node embeddings, and the relevant analysis is provided. Experimental results validate the effectiveness of the proposed framework compared with various baselines.
Scale Guided Hypernetwork for Blind Super-Resolution Image Quality Assessment
Jun 04, 2023



With the emergence of image super-resolution (SR) algorithm, how to blindly evaluate the quality of super-resolution images has become an urgent task. However, existing blind SR image quality assessment (IQA) metrics merely focus on visual characteristics of super-resolution images, ignoring the available scale information. In this paper, we reveal that the scale factor has a statistically significant impact on subjective quality scores of SR images, indicating that the scale information can be used to guide the task of blind SR IQA. Motivated by this, we propose a scale guided hypernetwork framework that evaluates SR image quality in a scale-adaptive manner. Specifically, the blind SR IQA procedure is divided into three stages, i.e., content perception, evaluation rule generation, and quality prediction. After content perception, a hypernetwork generates the evaluation rule used in quality prediction based on the scale factor of the SR image. We apply the proposed scale guided hypernetwork framework to existing representative blind IQA metrics, and experimental results show that the proposed framework not only boosts the performance of these IQA metrics but also enhances their generalization abilities. Source code will be available at https://github.com/JunFu1995/SGH.
RTN: Reinforced Transformer Network for Coronary CT Angiography Vessel-level Image Quality Assessment
Jul 13, 2022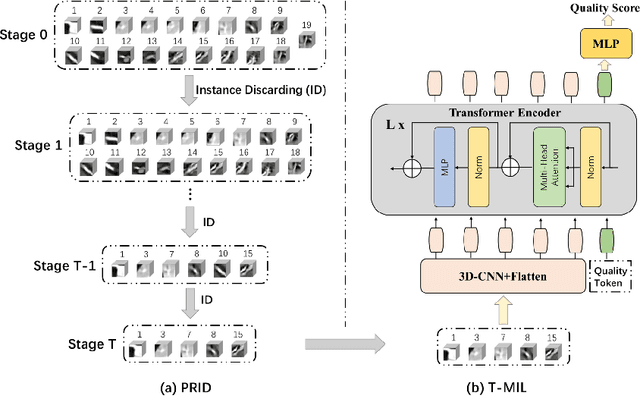
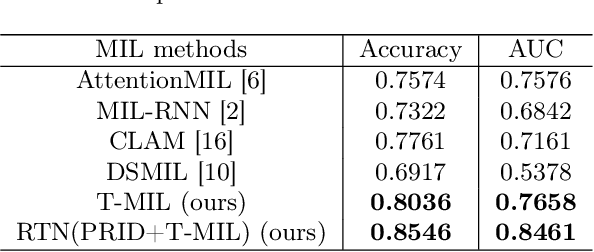
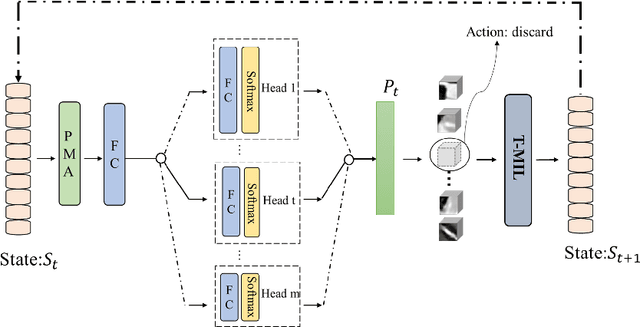

Coronary CT Angiography (CCTA) is susceptible to various distortions (e.g., artifacts and noise), which severely compromise the exact diagnosis of cardiovascular diseases. The appropriate CCTA Vessel-level Image Quality Assessment (CCTA VIQA) algorithm can be used to reduce the risk of error diagnosis. The primary challenges of CCTA VIQA are that the local part of coronary that determines final quality is hard to locate. To tackle the challenge, we formulate CCTA VIQA as a multiple-instance learning (MIL) problem, and exploit Transformer-based MIL backbone (termed as T-MIL) to aggregate the multiple instances along the coronary centerline into the final quality. However, not all instances are informative for final quality. There are some quality-irrelevant/negative instances intervening the exact quality assessment(e.g., instances covering only background or the coronary in instances is not identifiable). Therefore, we propose a Progressive Reinforcement learning based Instance Discarding module (termed as PRID) to progressively remove quality-irrelevant/negative instances for CCTA VIQA. Based on the above two modules, we propose a Reinforced Transformer Network (RTN) for automatic CCTA VIQA based on end-to-end optimization. Extensive experimental results demonstrate that our proposed method achieves the state-of-the-art performance on the real-world CCTA dataset, exceeding previous MIL methods by a large margin.
Parotid Gland MRI Segmentation Based on Swin-Unet and Multimodal Images
Jun 07, 2022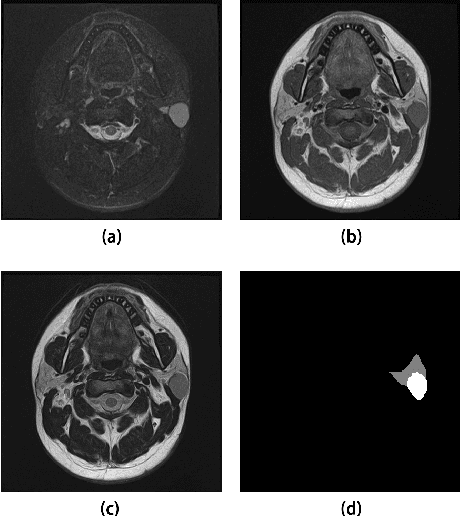
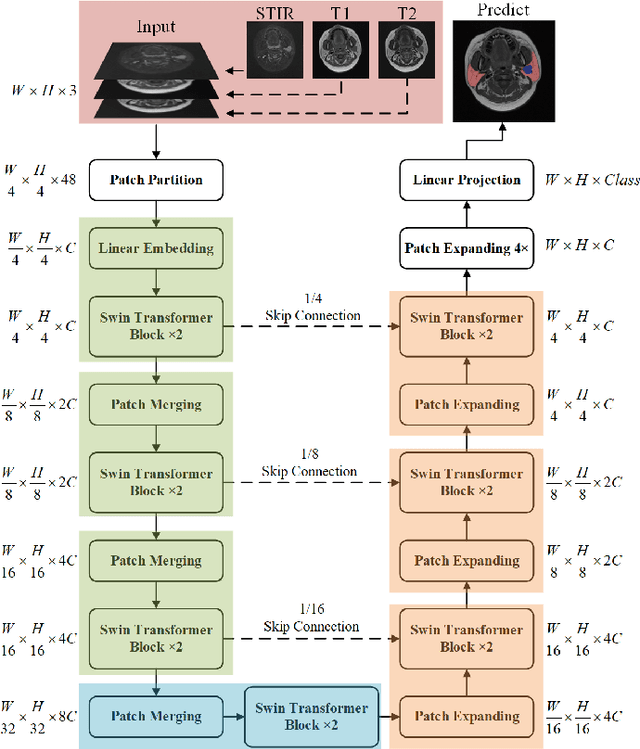
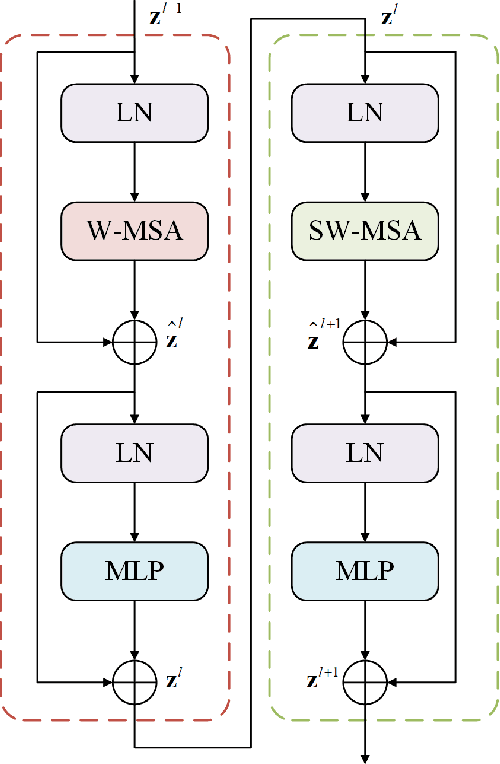
Parotid gland tumors account for approximately 2% to 10% of head and neck tumors. Preoperative tumor localization, differential diagnosis, and subsequent selection of appropriate treatment for parotid gland tumors is critical. However, the relative rarity of these tumors and the highly dispersed tissue types have left an unmet need for a subtle differential diagnosis of such neoplastic lesions based on preoperative radiomics. Recently, deep learning methods have developed rapidly, especially Transformer beats the traditional convolutional neural network in computer vision. Many new Transformer-based networks have been proposed for computer vision tasks. In this study, multicenter multimodal parotid gland MRI images were collected. The Swin-Unet which was based on Transformer was used. MRI images of STIR, T1 and T2 modalities were combined into a three-channel data to train the network. We achieved segmentation of the region of interest for parotid gland and tumor. The DSC of the model on the test set was 88.63%, MPA was 99.31%, MIoU was 83.99%, and HD was 3.04. Then a series of comparison experiments were designed in this paper to further validate the segmentation performance of the algorithm.
Mutual Attention-based Hybrid Dimensional Network for Multimodal Imaging Computer-aided Diagnosis
Jan 24, 2022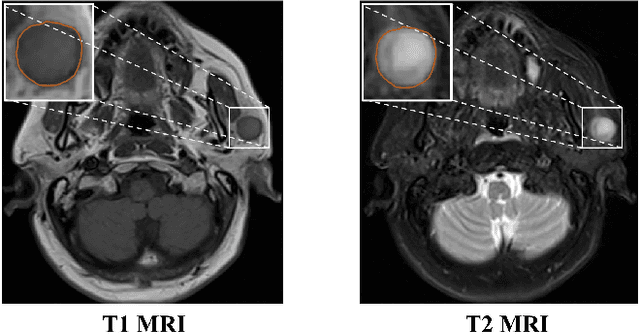
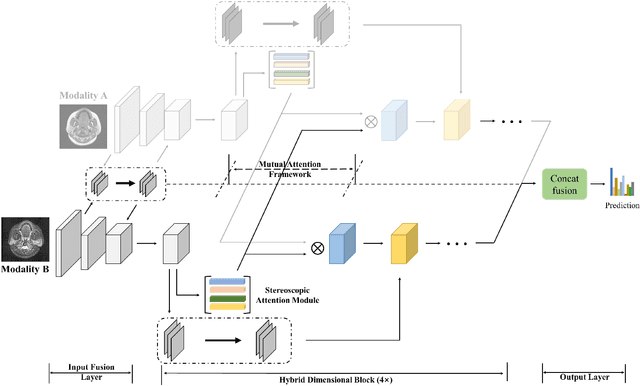
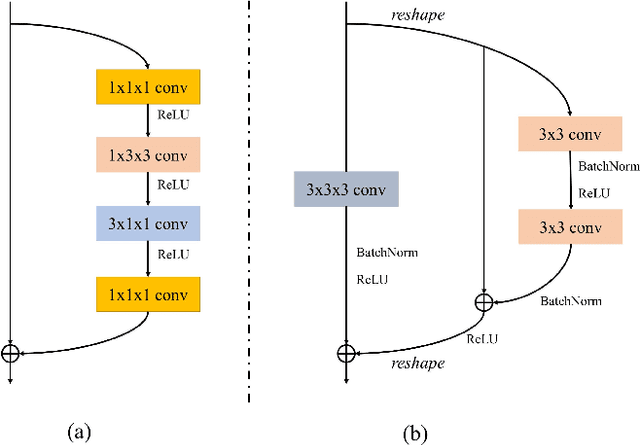
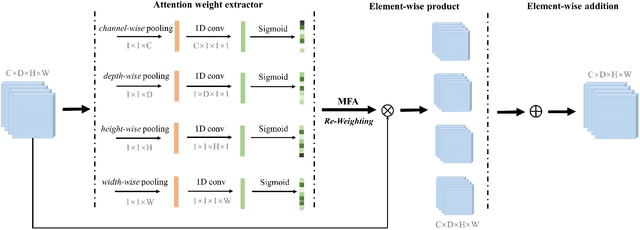
Recent works on Multimodal 3D Computer-aided diagnosis have demonstrated that obtaining a competitive automatic diagnosis model when a 3D convolution neural network (CNN) brings more parameters and medical images are scarce remains nontrivial and challenging. Considering both consistencies of regions of interest in multimodal images and diagnostic accuracy, we propose a novel mutual attention-based hybrid dimensional network for MultiModal 3D medical image classification (MMNet). The hybrid dimensional network integrates 2D CNN with 3D convolution modules to generate deeper and more informative feature maps, and reduce the training complexity of 3D fusion. Besides, the pre-trained model of ImageNet can be used in 2D CNN, which improves the performance of the model. The stereoscopic attention is focused on building rich contextual interdependencies of the region in 3D medical images. To improve the regional correlation of pathological tissues in multimodal medical images, we further design a mutual attention framework in the network to build the region-wise consistency in similar stereoscopic regions of different image modalities, providing an implicit manner to instruct the network to focus on pathological tissues. MMNet outperforms many previous solutions and achieves results competitive to the state-of-the-art on three multimodal imaging datasets, i.e., Parotid Gland Tumor (PGT) dataset, the MRNet dataset, and the PROSTATEx dataset, and its advantages are validated by extensive experiments.
ImageSubject: A Large-scale Dataset for Subject Detection
Jan 09, 2022
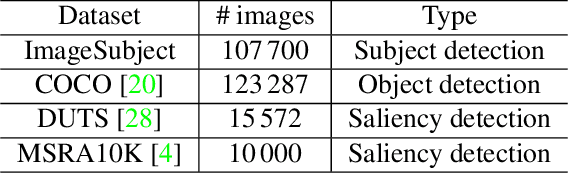

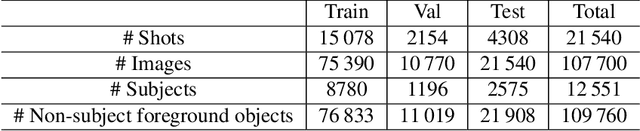
Main subjects usually exist in the images or videos, as they are the objects that the photographer wants to highlight. Human viewers can easily identify them but algorithms often confuse them with other objects. Detecting the main subjects is an important technique to help machines understand the content of images and videos. We present a new dataset with the goal of training models to understand the layout of the objects and the context of the image then to find the main subjects among them. This is achieved in three aspects. By gathering images from movie shots created by directors with professional shooting skills, we collect the dataset with strong diversity, specifically, it contains 107\,700 images from 21\,540 movie shots. We labeled them with the bounding box labels for two classes: subject and non-subject foreground object. We present a detailed analysis of the dataset and compare the task with saliency detection and object detection. ImageSubject is the first dataset that tries to localize the subject in an image that the photographer wants to highlight. Moreover, we find the transformer-based detection model offers the best result among other popular model architectures. Finally, we discuss the potential applications and conclude with the importance of the dataset.