 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptual Quality Optimization of Image Super-Resolution
Feb 25, 2026Single-image super-resolution (SR) has achieved remarkable progress with deep learning, yet most approaches rely on distortion-oriented losses or heuristic perceptual priors, which often lead to a trade-off between fidelity and visual quality. To address this issue, we propose an \textit{Efficient Perceptual Bi-directional Attention Network (Efficient-PBAN)} that explicitly optimizes SR towards human-preferred quality. Unlike patch-based quality models, Efficient-PBAN avoids extensive patch sampling and enables efficient image-level perception. The proposed framework is trained on our self-constructed SR quality dataset that covers a wide range of state-of-the-art SR methods with corresponding human opinion scores. Using this dataset, Efficient-PBAN learns to predict perceptual quality in a way that correlates strongly with subjective judgments. The learned metric is further integrated into SR training as a differentiable perceptual loss, enabling closed-loop alignment between reconstruction and perceptual assessment. Extensive experiments demonstrate that our approach delivers superior perceptual quality. Code is publicly available at https://github.com/Lighting-YXLI/Efficient-PBAN.
PhysLab: A Benchmark Dataset for Multi-Granularity Visual Parsing of Physics Experiments
Jun 07, 2025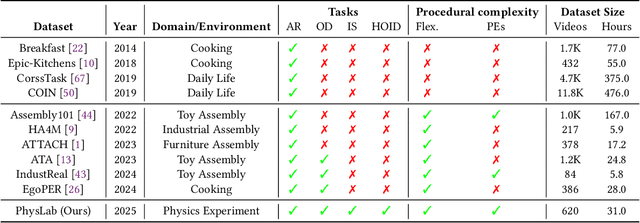

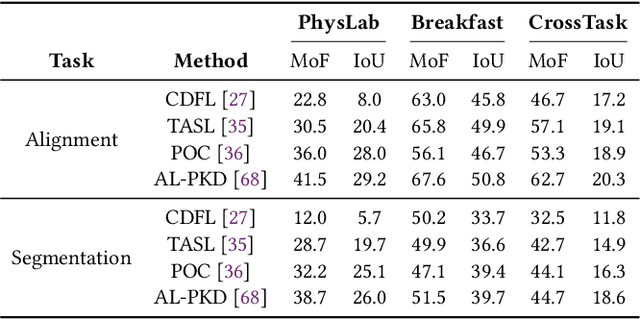
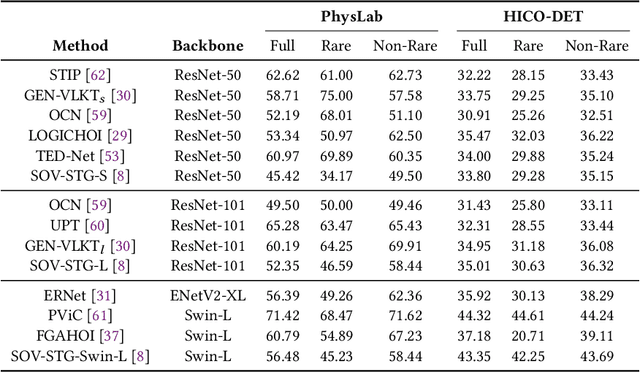
Visual parsing of images and videos is critical for a wide range of real-world applications. However, progress in this field is constrained by limitations of existing datasets: (1) insufficient annotation granularity, which impedes fine-grained scene understanding and high-level reasoning; (2) limited coverage of domains, particularly a lack of datasets tailored for educational scenarios; and (3) lack of explicit procedural guidance, with minimal logical rules and insufficient representation of structured task process. To address these gaps, we introduce PhysLab, the first video dataset that captures students conducting complex physics experiments. The dataset includes four representative experiments that feature diverse scientific instruments and rich human-object interaction (HOI) patterns. PhysLab comprises 620 long-form videos and provides multilevel annotations that support a variety of vision tasks, including action recognition, object detection, HOI analysis, etc. We establish strong baselines and perform extensive evaluations to highlight key challenges in the parsing of procedural educational videos. We expect PhysLab to serve as a valuable resource for advancing fine-grained visual parsing, facilitating intelligent classroom systems, and fostering closer integration between computer vision and educational technologies. The dataset and the evaluation toolkit are publicly available at https://github.com/ZMH-SDUST/PhysLab.
S3CE-Net: Spike-guided Spatiotemporal Semantic Coupling and Expansion Network for Long Sequence Event Re-Identification
May 30, 2025In this paper, we leverage the advantages of event cameras to resist harsh lighting conditions, reduce background interference, achieve high time resolution, and protect facial information to study the long-sequence event-based person re-identification (Re-ID) task. To this end, we propose a simple and efficient long-sequence event Re-ID model, namely the Spike-guided Spatiotemporal Semantic Coupling and Expansion Network (S3CE-Net). To better handle asynchronous event data, we build S3CE-Net based on spiking neural networks (SNNs). The S3CE-Net incorporates the Spike-guided Spatial-temporal Attention Mechanism (SSAM) and the Spatiotemporal Feature Sampling Strategy (STFS). The SSAM is designed to carry out semantic interaction and association in both spatial and temporal dimensions, leveraging the capabilities of SNNs. The STFS involves sampling spatial feature subsequences and temporal feature subsequences from the spatiotemporal dimensions, driving the Re-ID model to perceive broader and more robust effective semantics. Notably, the STFS introduces no additional parameters and is only utilized during the training stage. Therefore, S3CE-Net is a low-parameter and high-efficiency model for long-sequence event-based person Re-ID. Extensive experiments have verified that our S3CE-Net achieves outstanding performance on many mainstream long-sequence event-based person Re-ID datasets. Code is available at:https://github.com/Mhsunshine/SC3E_Net.
CLIP-DQA: Blindly Evaluating Dehazed Images from Global and Local Perspectives Using CLIP
Feb 03, 2025Blind dehazed image quality assessment (BDQA), which aims to accurately predict the visual quality of dehazed images without any reference information, is essential for the evaluation, comparison, and optimization of image dehazing algorithms. Existing learning-based BDQA methods have achieved remarkable success, while the small scale of DQA datasets limits their performance. To address this issue, in this paper, we propose to adapt Contrastive Language-Image Pre-Training (CLIP), pre-trained on large-scale image-text pairs, to the BDQA task. Specifically, inspired by the fact that the human visual system understands images based on hierarchical features, we take global and local information of the dehazed image as the input of CLIP. To accurately map the input hierarchical information of dehazed images into the quality score, we tune both the vision branch and language branch of CLIP with prompt learning. Experimental results on two authentic DQA datasets demonstrate that our proposed approach, named CLIP-DQA, achieves more accurate quality predictions over existing BDQA methods. The code is available at https://github.com/JunFu1995/CLIP-DQA.
Vision-Language Consistency Guided Multi-modal Prompt Learning for Blind AI Generated Image Quality Assessment
Jun 24, 2024Recently, textual prompt tuning has shown inspirational performance in adapting Contrastive Language-Image Pre-training (CLIP) models to natural image quality assessment. However, such uni-modal prompt learning method only tunes the language branch of CLIP models. This is not enough for adapting CLIP models to AI generated image quality assessment (AGIQA) since AGIs visually differ from natural images. In addition, the consistency between AGIs and user input text prompts, which correlates with the perceptual quality of AGIs, is not investigated to guide AGIQA. In this letter, we propose vision-language consistency guided multi-modal prompt learning for blind AGIQA, dubbed CLIP-AGIQA. Specifically, we introduce learnable textual and visual prompts in language and vision branches of CLIP models, respectively. Moreover, we design a text-to-image alignment quality prediction task, whose learned vision-language consistency knowledge is used to guide the optimization of the above multi-modal prompts. Experimental results on two public AGIQA datasets demonstrate that the proposed method outperforms state-of-the-art quality assessment models. The source code is available at https://github.com/JunFu1995/CLIP-AGIQA.
Reduced-Reference Quality Assessment of Point Clouds via Content-Oriented Saliency Projection
Jan 18, 2023Many dense 3D point clouds have been exploited to represent visual objects instead of traditional images or videos. To evaluate the perceptual quality of various point clouds, in this letter, we propose a novel and efficient Reduced-Reference quality metric for point clouds, which is based on Content-oriented sAliency Projection (RR-CAP). Specifically, we make the first attempt to simplify reference and distorted point clouds into projected saliency maps with a downsampling operation. Through this process, we tackle the issue of transmitting large-volume original point clouds to user-ends for quality assessment. Then, motivated by the characteristics of the human visual system (HVS), the objective quality scores of distorted point clouds are produced by combining content-oriented similarity and statistical correlation measurements. Finally, extensive experiments are conducted on SJTU-PCQA and WPC databases. The experimental results demonstrate that our proposed algorithm outperforms existing reduced-reference and no-reference quality metrics, and significantly reduces the performance gap between state-of-the-art full-reference quality assessment methods. In addition, we show the performance variation of each proposed technical component by ablation tests.
Dehazed Image Quality Evaluation: From Partial Discrepancy to Blind Perception
Nov 22, 2022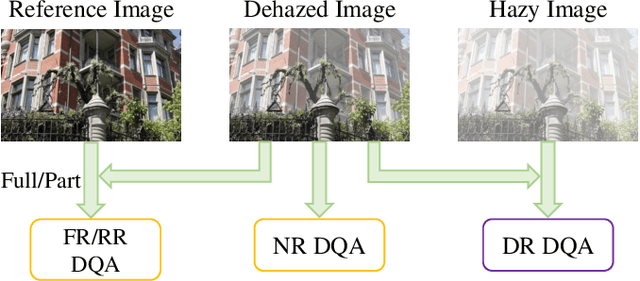

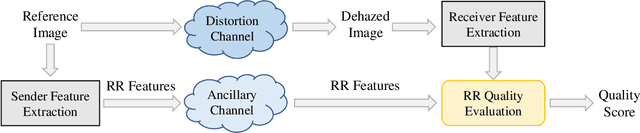
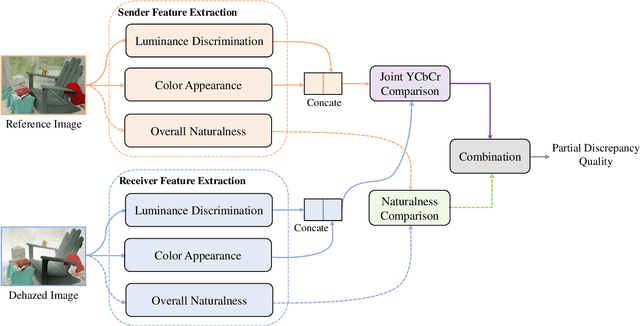
Image dehazing aims to restore spatial details from hazy images. There have emerged a number of image dehazing algorithms, designed to increase the visibility of those hazy images. However, much less work has been focused on evaluating the visual quality of dehazed images. In this paper, we propose a Reduced-Reference dehazed image quality evaluation approach based on Partial Discrepancy (RRPD) and then extend it to a No-Reference quality assessment metric with Blind Perception (NRBP). Specifically, inspired by the hierarchical characteristics of the human perceiving dehazed images, we introduce three groups of features: luminance discrimination, color appearance, and overall naturalness. In the proposed RRPD, the combined distance between a set of sender and receiver features is adopted to quantify the perceptually dehazed image quality. By integrating global and local channels from dehazed images, the RRPD is converted to NRBP which does not rely on any information from the references. Extensive experiment results on several dehazed image quality databases demonstrate that our proposed methods outperform state-of-the-art full-reference, reduced-reference, and no-reference quality assessment models. Furthermore, we show that the proposed dehazed image quality evaluation methods can be effectively applied to tune parameters for potential image dehazing algorithms.
Going the Extra Mile in Face Image Quality Assessment: A Novel Database and Model
Jul 11, 2022
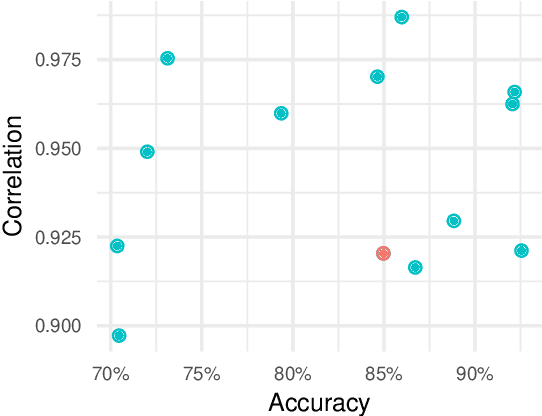

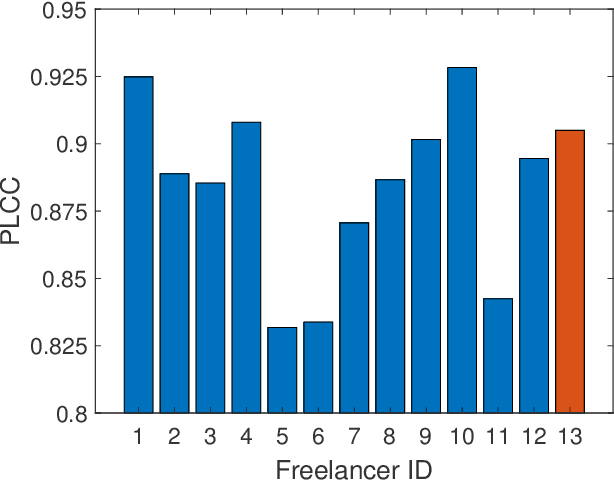
Computer vision models for image quality assessment (IQA) predict the subjective effect of generic image degradation, such as artefacts, blurs, bad exposure, or colors. The scarcity of face images in existing IQA datasets (below 10\%) is limiting the precision of IQA required for accurately filtering low-quality face images or guiding CV models for face image processing, such as super-resolution, image enhancement, and generation. In this paper, we first introduce the largest annotated IQA database to date that contains 20,000 human faces (an order of magnitude larger than all existing rated datasets of faces), of diverse individuals, in highly varied circumstances, quality levels, and distortion types. Based on the database, we further propose a novel deep learning model, which re-purposes generative prior features for predicting subjective face quality. By exploiting rich statistics encoded in well-trained generative models, we obtain generative prior information of the images and serve them as latent references to facilitate the blind IQA task. Experimental results demonstrate the superior prediction accuracy of the proposed model on the face IQA task.
TranSalNet: Visual saliency prediction using transformers
Oct 07, 2021



Convolutional neural networks (CNNs) have significantly advanced computational modeling for saliency prediction. However, the inherent inductive biases of convolutional architectures cause insufficient long-range contextual encoding capacity, which potentially makes a saliency model less humanlike. Transformers have shown great potential in encoding long-range information by leveraging the self-attention mechanism. In this paper, we propose a novel saliency model integrating transformer components to CNNs to capture the long-range contextual information. Experimental results show that the new components make improvements, and the proposed model achieves promising results in predicting saliency.
Cuid: A new study of perceived image quality and its subjective assessment
Sep 28, 2020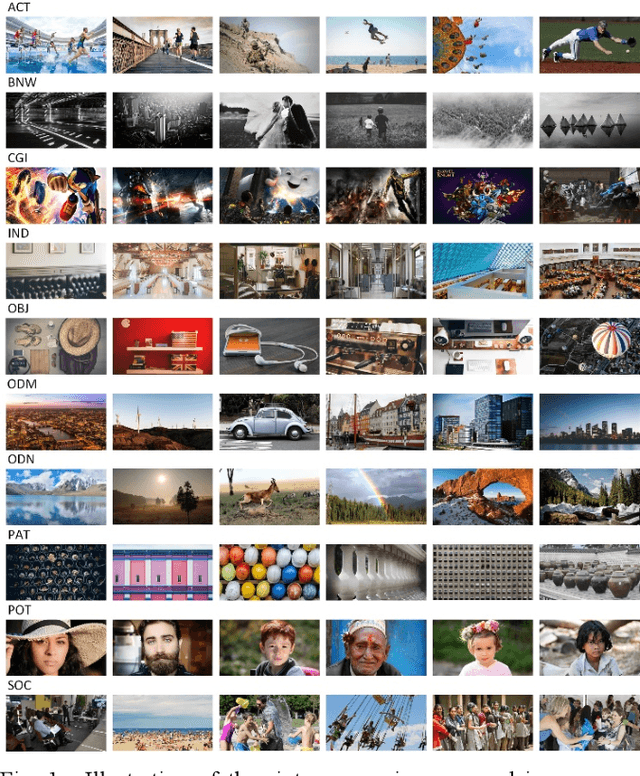


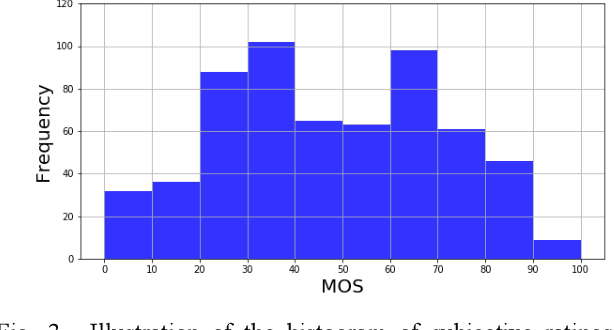
Research on image quality assessment (IQA) remains limited mainly due to our incomplete knowledge about human visual perception. Existing IQA algorithms have been designed or trained with insufficient subjective data with a small degree of stimulus variability. This has led to challenges for those algorithms to handle complexity and diversity of real-world digital content. Perceptual evidence from human subjects serves as a grounding for the development of advanced IQA algorithms. It is thus critical to acquire reliable subjective data with controlled perception experiments that faithfully reflect human behavioural responses to distortions in visual signals. In this paper, we present a new study of image quality perception where subjective ratings were collected in a controlled lab environment. We investigate how quality perception is affected by a combination of different categories of images and different types and levels of distortions. The database will be made publicly available to facilitate calibration and validation of IQA algorithms.