 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS3CE-Net: Spike-guided Spatiotemporal Semantic Coupling and Expansion Network for Long Sequence Event Re-Identification
May 30, 2025In this paper, we leverage the advantages of event cameras to resist harsh lighting conditions, reduce background interference, achieve high time resolution, and protect facial information to study the long-sequence event-based person re-identification (Re-ID) task. To this end, we propose a simple and efficient long-sequence event Re-ID model, namely the Spike-guided Spatiotemporal Semantic Coupling and Expansion Network (S3CE-Net). To better handle asynchronous event data, we build S3CE-Net based on spiking neural networks (SNNs). The S3CE-Net incorporates the Spike-guided Spatial-temporal Attention Mechanism (SSAM) and the Spatiotemporal Feature Sampling Strategy (STFS). The SSAM is designed to carry out semantic interaction and association in both spatial and temporal dimensions, leveraging the capabilities of SNNs. The STFS involves sampling spatial feature subsequences and temporal feature subsequences from the spatiotemporal dimensions, driving the Re-ID model to perceive broader and more robust effective semantics. Notably, the STFS introduces no additional parameters and is only utilized during the training stage. Therefore, S3CE-Net is a low-parameter and high-efficiency model for long-sequence event-based person Re-ID. Extensive experiments have verified that our S3CE-Net achieves outstanding performance on many mainstream long-sequence event-based person Re-ID datasets. Code is available at:https://github.com/Mhsunshine/SC3E_Net.
Multi-modal Collaborative Optimization and Expansion Network for Event-assisted Single-eye Expression Recognition
May 17, 2025In this paper, we proposed a Multi-modal Collaborative Optimization and Expansion Network (MCO-E Net), to use event modalities to resist challenges such as low light, high exposure, and high dynamic range in single-eye expression recognition tasks. The MCO-E Net introduces two innovative designs: Multi-modal Collaborative Optimization Mamba (MCO-Mamba) and Heterogeneous Collaborative and Expansion Mixture-of-Experts (HCE-MoE). MCO-Mamba, building upon Mamba, leverages dual-modal information to jointly optimize the model, facilitating collaborative interaction and fusion of modal semantics. This approach encourages the model to balance the learning of both modalities and harness their respective strengths. HCE-MoE, on the other hand, employs a dynamic routing mechanism to distribute structurally varied experts (deep, attention, and focal), fostering collaborative learning of complementary semantics. This heterogeneous architecture systematically integrates diverse feature extraction paradigms to comprehensively capture expression semantics. Extensive experiments demonstrate that our proposed network achieves competitive performance in the task of single-eye expression recognition, especially under poor lighting conditions.
MAP-based Problem-Agnostic diffusion model for Inverse Problems
Jan 25, 2025



Diffusion models have indeed shown great promise in solving inverse problems in image processing. In this paper, we propose a novel, problem-agnostic diffusion model called the maximum a posteriori (MAP)-based guided term estimation method for inverse problems. We divide the conditional score function into two terms according to Bayes' rule: the unconditional score function and the guided term. We design the MAP-based guided term estimation method, while the unconditional score function is approximated by an existing score network. To estimate the guided term, we base on the assumption that the space of clean natural images is inherently smooth, and introduce a MAP estimate of the $t$-th latent variable. We then substitute this estimation into the expression of the inverse problem and obtain the approximation of the guided term. We evaluate our method extensively on super-resolution, inpainting, and denoising tasks, and demonstrate comparable performance to DDRM, DMPS, DPS and $\Pi$GDM.
Spectrum-guided Feature Enhancement Network for Event Person Re-Identification
Feb 02, 2024As a cutting-edge biosensor, the event camera holds significant potential in the field of computer vision, particularly regarding privacy preservation. However, compared to traditional cameras, event streams often contain noise and possess extremely sparse semantics, posing a formidable challenge for event-based person re-identification (event Re-ID). To address this, we introduce a novel event person re-identification network: the Spectrum-guided Feature Enhancement Network (SFE-Net). This network consists of two innovative components: the Multi-grain Spectrum Attention Mechanism (MSAM) and the Consecutive Patch Dropout Module (CPDM). MSAM employs a fourier spectrum transform strategy to filter event noise, while also utilizing an event-guided multi-granularity attention strategy to enhance and capture discriminative person semantics. CPDM employs a consecutive patch dropout strategy to generate multiple incomplete feature maps, encouraging the deep Re-ID model to equally perceive each effective region of the person's body and capture robust person descriptors. Extensive experiments on Event Re-ID datasets demonstrate that our SFE-Net achieves the best performance in this task.
Fine-grained Text and Image Guided Point Cloud Completion with CLIP Model
Aug 17, 2023



This paper focuses on the recently popular task of point cloud completion guided by multimodal information. Although existing methods have achieved excellent performance by fusing auxiliary images, there are still some deficiencies, including the poor generalization ability of the model and insufficient fine-grained semantic information for extracted features. In this work, we propose a novel multimodal fusion network for point cloud completion, which can simultaneously fuse visual and textual information to predict the semantic and geometric characteristics of incomplete shapes effectively. Specifically, to overcome the lack of prior information caused by the small-scale dataset, we employ a pre-trained vision-language model that is trained with a large amount of image-text pairs. Therefore, the textual and visual encoders of this large-scale model have stronger generalization ability. Then, we propose a multi-stage feature fusion strategy to fuse the textual and visual features into the backbone network progressively. Meanwhile, to further explore the effectiveness of fine-grained text descriptions for point cloud completion, we also build a text corpus with fine-grained descriptions, which can provide richer geometric details for 3D shapes. The rich text descriptions can be used for training and evaluating our network. Extensive quantitative and qualitative experiments demonstrate the superior performance of our method compared to state-of-the-art point cloud completion networks.
ALR-GAN: Adaptive Layout Refinement for Text-to-Image Synthesis
Apr 13, 2023We propose a novel Text-to-Image Generation Network, Adaptive Layout Refinement Generative Adversarial Network (ALR-GAN), to adaptively refine the layout of synthesized images without any auxiliary information. The ALR-GAN includes an Adaptive Layout Refinement (ALR) module and a Layout Visual Refinement (LVR) loss. The ALR module aligns the layout structure (which refers to locations of objects and background) of a synthesized image with that of its corresponding real image. In ALR module, we proposed an Adaptive Layout Refinement (ALR) loss to balance the matching of hard and easy features, for more efficient layout structure matching. Based on the refined layout structure, the LVR loss further refines the visual representation within the layout area. Experimental results on two widely-used datasets show that ALR-GAN performs competitively at the Text-to-Image generation task.
DR-GAN: Distribution Regularization for Text-to-Image Generation
Apr 17, 2022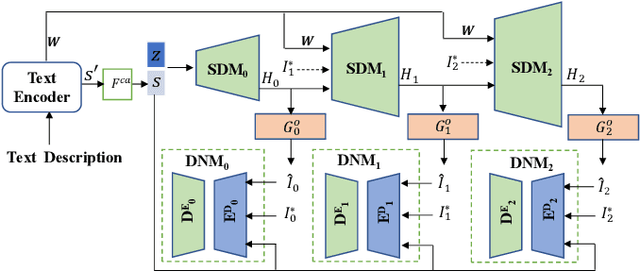
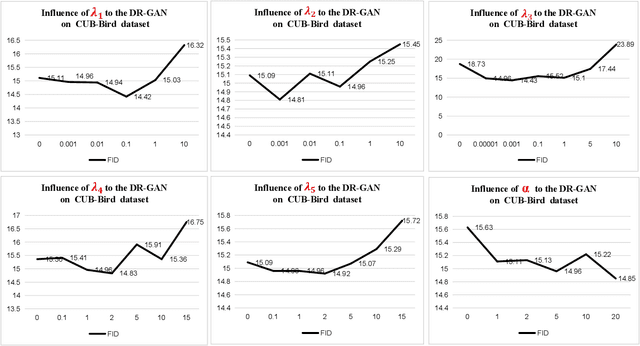

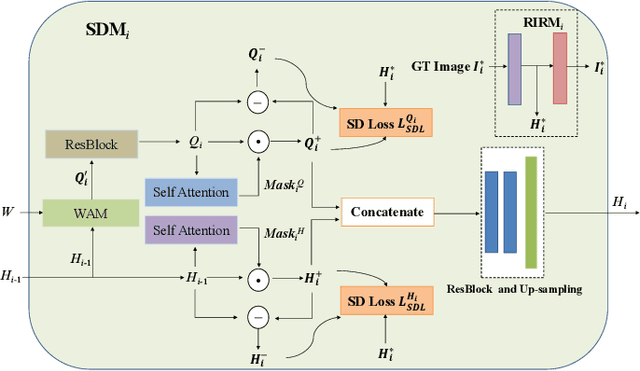
This paper presents a new Text-to-Image generation model, named Distribution Regularization Generative Adversarial Network (DR-GAN), to generate images from text descriptions from improved distribution learning. In DR-GAN, we introduce two novel modules: a Semantic Disentangling Module (SDM) and a Distribution Normalization Module (DNM). SDM combines the spatial self-attention mechanism and a new Semantic Disentangling Loss (SDL) to help the generator distill key semantic information for the image generation. DNM uses a Variational Auto-Encoder (VAE) to normalize and denoise the image latent distribution, which can help the discriminator better distinguish synthesized images from real images. DNM also adopts a Distribution Adversarial Loss (DAL) to guide the generator to align with normalized real image distributions in the latent space. Extensive experiments on two public datasets demonstrated that our DR-GAN achieved a competitive performance in the Text-to-Image task.
Incomplete Descriptor Mining with Elastic Loss for Person Re-Identification
Aug 17, 2020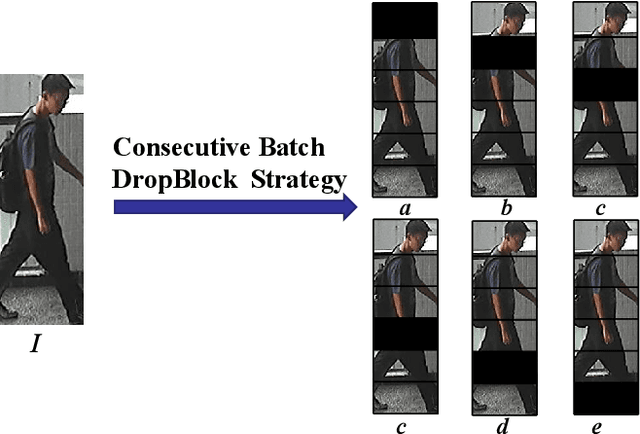
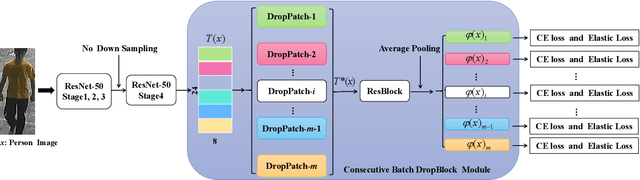
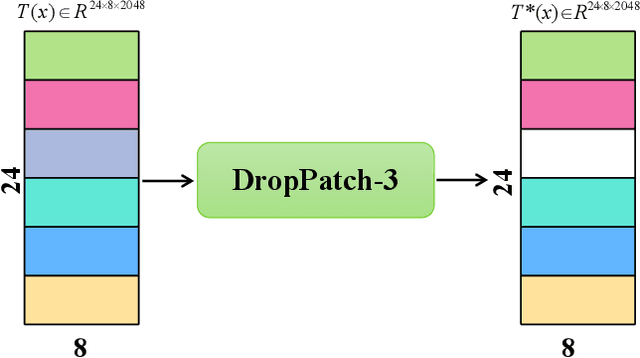
In this paper, we propose a novel person Re-ID model, Consecutive Batch DropBlock Network (CBDB-Net), to help the person Re-ID model to capture the attentive and robust person descriptor. The CBDB-Net contains two novel modules: the Consecutive Batch DropBlock Module (CBDBM) and the Elastic Loss. In the Consecutive Batch DropBlock Module (CBDBM), it firstly conducts uniform partition on the feature maps. And then, the CBDBM independently and continuously drops each patch from top to bottom on the feature maps, which outputs multiple incomplete features to push the model to capture the robust person descriptor. In the Elastic Loss, we design a novel weight control item to help the deep model adaptively balance hard sample pairs and easy sample pairs in the whole training process. Through an extensive set of ablation studies, we verify that the Consecutive Batch DropBlock Module (CBDBM) and the Elastic Loss each contribute to the performance boosts of CBDB-Net. We demonstrate that our CBDB-Net can achieve the competitive performance on the three generic person Re-ID datasets (the Market-1501, the DukeMTMC-Re-ID, and the CUHK03 dataset), three occlusion Person Re-ID datasets (the Occluded DukeMTMC, the Partial-REID, and the Partial iLIDS dataset), and the other image retrieval dataset (In-Shop Clothes Retrieval dataset).
MHSA-Net: Multi-Head Self-Attention Network for Occluded Person Re-Identification
Aug 14, 2020
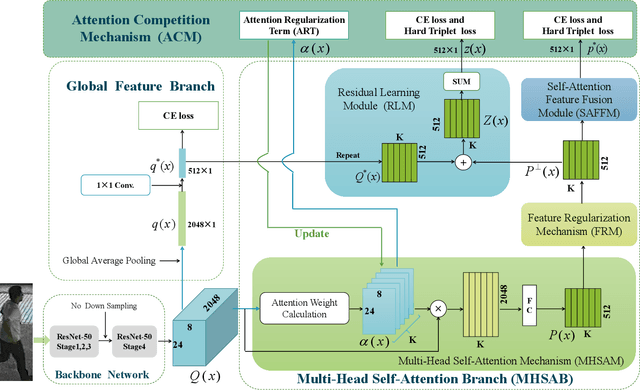
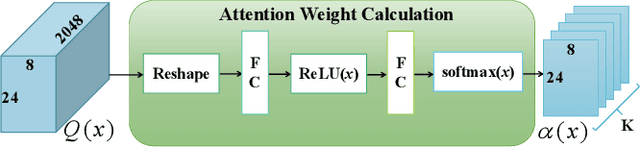

This paper presents a novel person re-identification model, named Multi-Head Self-Attention Network (MHSA-Net), to prune unimportant information and capture key local information from person images. MHSA-Net contains two main novel components: Multi-Head Self-Attention Branch (MHSAB) and Attention Competition Mechanism (ACM). The MHSAM adaptively captures key local person information, and then produces effective diversity embeddings of an image for the person matching. The ACM further helps filter out attention noise and non-key information. Through extensive ablation studies, we verified that the Structured Self-Attention Branch and Attention Competition Mechanism both contribute to the performance improvement of the MHSA-Net. Our MHSA-Net achieves state-of-the-art performance especially on images with occlusions. We have released our models (and will release the source codes after the paper is accepted) on https://github.com/hongchenphd/MHSA-Net.