 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Informed Neural Network with Adaptive Clustering Learning Mechanism for Information Popularity Prediction
Mar 20, 2026With society entering the Internet era, the volume and speed of data and information have been increasing. Predicting the popularity of information cascades can help with high-value information delivery and public opinion monitoring on the internet platforms. The current state-of-the-art models for predicting information popularity utilize deep learning methods such as graph convolution networks (GCNs) and recurrent neural networks (RNNs) to capture early cascades and temporal features to predict their popularity increments. However, these previous methods mainly focus on the micro features of information cascades, neglecting their general macroscopic patterns. Furthermore, they also lack consideration of the impact of information heterogeneity on spread popularity. To overcome these limitations, we propose a physics-informed neural network with adaptive clustering learning mechanism, PIACN, for predicting the popularity of information cascades. Our proposed model not only models the macroscopic patterns of information dissemination through physics-informed approach for the first time but also considers the influence of information heterogeneity through an adaptive clustering learning mechanism. Extensive experimental results on three real-world datasets demonstrate that our model significantly outperforms other state-of-the-art methods in predicting information popularity.
Covo-Audio Technical Report
Feb 10, 2026In this work, we present Covo-Audio, a 7B-parameter end-to-end LALM that directly processes continuous audio inputs and generates audio outputs within a single unified architecture. Through large-scale curated pretraining and targeted post-training, Covo-Audio achieves state-of-the-art or competitive performance among models of comparable scale across a broad spectrum of tasks, including speech-text modeling, spoken dialogue, speech understanding, audio understanding, and full-duplex voice interaction. Extensive evaluations demonstrate that the pretrained foundation model exhibits strong speech-text comprehension and semantic reasoning capabilities on multiple benchmarks, outperforming representative open-source models of comparable scale. Furthermore, Covo-Audio-Chat, the dialogue-oriented variant, demonstrates strong spoken conversational abilities, including understanding, contextual reasoning, instruction following, and generating contextually appropriate and empathetic responses, validating its applicability to real-world conversational assistant scenarios. Covo-Audio-Chat-FD, the evolved full-duplex model, achieves substantially superior performance on both spoken dialogue capabilities and full-duplex interaction behaviors, demonstrating its competence in practical robustness. To mitigate the high cost of deploying end-to-end LALMs for natural conversational systems, we propose an intelligence-speaker decoupling strategy that separates dialogue intelligence from voice rendering, enabling flexible voice customization with minimal text-to-speech (TTS) data while preserving dialogue performance. Overall, our results highlight the strong potential of 7B-scale models to integrate sophisticated audio intelligence with high-level semantic reasoning, and suggest a scalable path toward more capable and versatile LALMs.
DSCD-Nav: Dual-Stance Cooperative Debate for Object Navigation
Jan 29, 2026Adaptive navigation in unfamiliar indoor environments is crucial for household service robots. Despite advances in zero-shot perception and reasoning from vision-language models, existing navigation systems still rely on single-pass scoring at the decision layer, leading to overconfident long-horizon errors and redundant exploration. To tackle these problems, we propose Dual-Stance Cooperative Debate Navigation (DSCD-Nav), a decision mechanism that replaces one-shot scoring with stance-based cross-checking and evidence-aware arbitration to improve action reliability under partial observability. Specifically, given the same observation and candidate action set, we explicitly construct two stances by conditioning the evaluation on diverse and complementary objectives: a Task-Scene Understanding (TSU) stance that prioritizes goal progress from scene-layout cues, and a Safety-Information Balancing (SIB) stance that emphasizes risk and information value. The stances conduct a cooperative debate and make policy by cross-checking their top candidates with cue-grounded arguments. Then, a Navigation Consensus Arbitration (NCA) agent is employed to consolidate both sides' reasons and evidence, optionally triggering lightweight micro-probing to verify uncertain choices, preserving NCA's primary intent while disambiguating. Experiments on HM3Dv1, HM3Dv2, and MP3D demonstrate consistent improvements in success and path efficiency while reducing exploration redundancy.
LVD-GS: Gaussian Splatting SLAM for Dynamic Scenes via Hierarchical Explicit-Implicit Representation Collaboration Rendering
Oct 26, 20253D Gaussian Splatting SLAM has emerged as a widely used technique for high-fidelity mapping in spatial intelligence. However, existing methods often rely on a single representation scheme, which limits their performance in large-scale dynamic outdoor scenes and leads to cumulative pose errors and scale ambiguity. To address these challenges, we propose \textbf{LVD-GS}, a novel LiDAR-Visual 3D Gaussian Splatting SLAM system. Motivated by the human chain-of-thought process for information seeking, we introduce a hierarchical collaborative representation module that facilitates mutual reinforcement for mapping optimization, effectively mitigating scale drift and enhancing reconstruction robustness. Furthermore, to effectively eliminate the influence of dynamic objects, we propose a joint dynamic modeling module that generates fine-grained dynamic masks by fusing open-world segmentation with implicit residual constraints, guided by uncertainty estimates from DINO-Depth features. Extensive evaluations on KITTI, nuScenes, and self-collected datasets demonstrate that our approach achieves state-of-the-art performance compared to existing methods.
DAIEN-TTS: Disentangled Audio Infilling for Environment-Aware Text-to-Speech Synthesis
Sep 18, 2025


This paper presents DAIEN-TTS, a zero-shot text-to-speech (TTS) framework that enables ENvironment-aware synthesis through Disentangled Audio Infilling. By leveraging separate speaker and environment prompts, DAIEN-TTS allows independent control over the timbre and the background environment of the synthesized speech. Built upon F5-TTS, the proposed DAIEN-TTS first incorporates a pretrained speech-environment separation (SES) module to disentangle the environmental speech into mel-spectrograms of clean speech and environment audio. Two random span masks of varying lengths are then applied to both mel-spectrograms, which, together with the text embedding, serve as conditions for infilling the masked environmental mel-spectrogram, enabling the simultaneous continuation of personalized speech and time-varying environmental audio. To further enhance controllability during inference, we adopt dual class-free guidance (DCFG) for the speech and environment components and introduce a signal-to-noise ratio (SNR) adaptation strategy to align the synthesized speech with the environment prompt. Experimental results demonstrate that DAIEN-TTS generates environmental personalized speech with high naturalness, strong speaker similarity, and high environmental fidelity.
Efficient Scaling for LLM-based ASR
Aug 06, 2025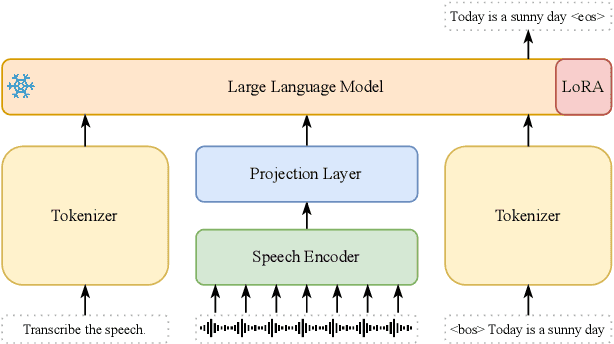
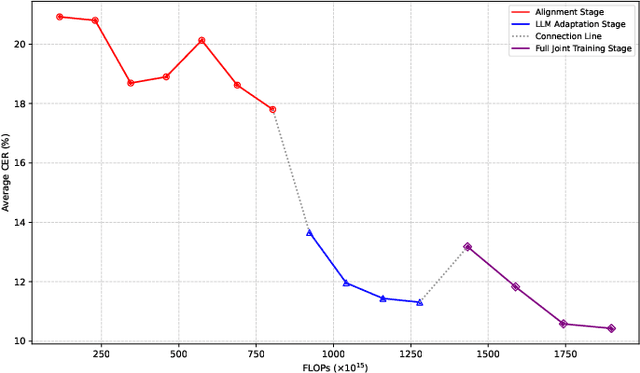
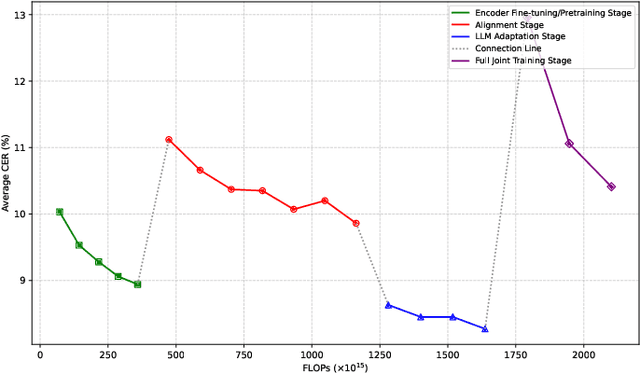
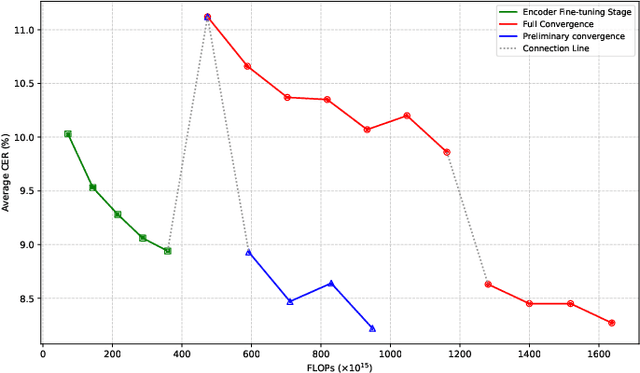
Large language model (LLM)-based automatic speech recognition (ASR) achieves strong performance but often incurs high computational costs. This work investigates how to obtain the best LLM-ASR performance efficiently. Through comprehensive and controlled experiments, we find that pretraining the speech encoder before integrating it with the LLM leads to significantly better scaling efficiency than the standard practice of joint post-training of LLM-ASR. Based on this insight, we propose a new multi-stage LLM-ASR training strategy, EFIN: Encoder First Integration. Among all training strategies evaluated, EFIN consistently delivers better performance (relative to 21.1% CERR) with significantly lower computation budgets (49.9% FLOPs). Furthermore, we derive a scaling law that approximates ASR error rates as a computation function, providing practical guidance for LLM-ASR scaling.
HDMoLE: Mixture of LoRA Experts with Hierarchical Routing and Dynamic Thresholds for Fine-Tuning LLM-based ASR Models
Sep 30, 2024



Recent advancements in integrating Large Language Models (LLM) with automatic speech recognition (ASR) have performed remarkably in general domains. While supervised fine-tuning (SFT) of all model parameters is often employed to adapt pre-trained LLM-based ASR models to specific domains, it imposes high computational costs and notably reduces their performance in general domains. In this paper, we propose a novel parameter-efficient multi-domain fine-tuning method for adapting pre-trained LLM-based ASR models to multi-accent domains without catastrophic forgetting named \textit{HDMoLE}, which leverages hierarchical routing and dynamic thresholds based on combining low-rank adaptation (LoRA) with the mixer of experts (MoE) and can be generalized to any linear layer. Hierarchical routing establishes a clear correspondence between LoRA experts and accent domains, improving cross-domain collaboration among the LoRA experts. Unlike the static Top-K strategy for activating LoRA experts, dynamic thresholds can adaptively activate varying numbers of LoRA experts at each MoE layer. Experiments on the multi-accent and standard Mandarin datasets demonstrate the efficacy of HDMoLE. Applying HDMoLE to an LLM-based ASR model projector module achieves similar performance to full fine-tuning in the target multi-accent domains while using only 9.6% of the trainable parameters required for full fine-tuning and minimal degradation in the source general domain.
Ideal-LLM: Integrating Dual Encoders and Language-Adapted LLM for Multilingual Speech-to-Text
Sep 17, 2024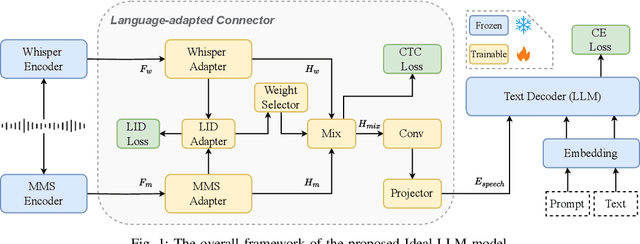
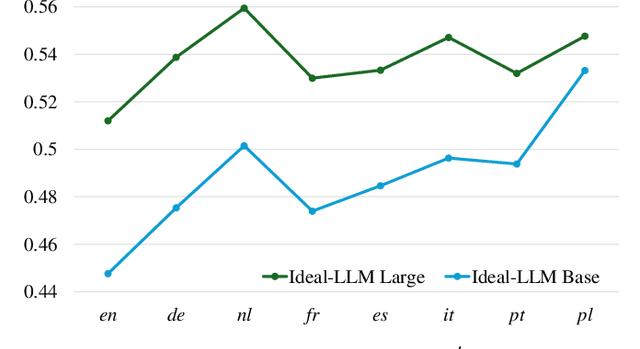
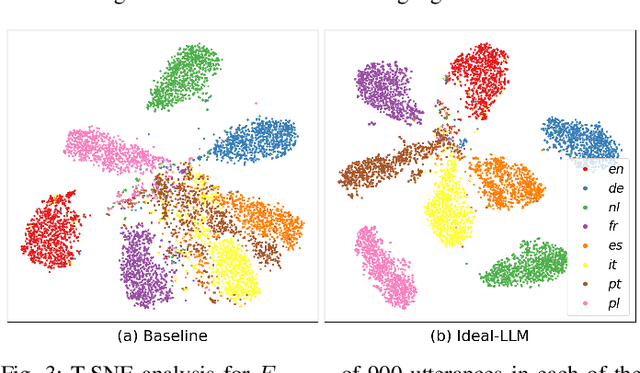

Integrating audio encoders with LLMs through connectors has enabled these models to process and comprehend audio modalities, significantly enhancing speech-to-text tasks, including automatic speech recognition (ASR) and automatic speech translation (AST). However, these methods often overlook the critical aspect of language adaptation in multilingual settings, relying instead on multilingual data without adequately addressing language differences. To address this gap, we propose the Ideal-LLM model, which employs dual multilingual encoders to enrich language feature information and utilizes a language-adapted connector to target the adaptation of each language specifically. By leveraging the complementary strengths of Whisper and MMS encoders, our approach ensures richer multilingual representations. Additionally, the language-adapted connector enhances modal transformation via a language weight selector tailored for each language. Experimental results demonstrate that Ideal-LLM significantly improves ASR performance, achieving a 32.6% relative reduction in average word error rates compared to the standard speech encoder integrated with LLMs and yields an average BLEU score of 36.78 for AST task.
Advancing Multi-talker ASR Performance with Large Language Models
Aug 30, 2024



Recognizing overlapping speech from multiple speakers in conversational scenarios is one of the most challenging problem for automatic speech recognition (ASR). Serialized output training (SOT) is a classic method to address multi-talker ASR, with the idea of concatenating transcriptions from multiple speakers according to the emission times of their speech for training. However, SOT-style transcriptions, derived from concatenating multiple related utterances in a conversation, depend significantly on modeling long contexts. Therefore, compared to traditional methods that primarily emphasize encoder performance in attention-based encoder-decoder (AED) architectures, a novel approach utilizing large language models (LLMs) that leverages the capabilities of pre-trained decoders may be better suited for such complex and challenging scenarios. In this paper, we propose an LLM-based SOT approach for multi-talker ASR, leveraging pre-trained speech encoder and LLM, fine-tuning them on multi-talker dataset using appropriate strategies. Experimental results demonstrate that our approach surpasses traditional AED-based methods on the simulated dataset LibriMix and achieves state-of-the-art performance on the evaluation set of the real-world dataset AMI, outperforming the AED model trained with 1000 times more supervised data in previous works.
Unveiling the Potential of LLM-Based ASR on Chinese Open-Source Datasets
May 06, 2024



Large Language Models (LLMs) have demonstrated unparalleled effectiveness in various NLP tasks, and integrating LLMs with automatic speech recognition (ASR) is becoming a mainstream paradigm. Building upon this momentum, our research delves into an in-depth examination of this paradigm on a large open-source Chinese dataset. Specifically, our research aims to evaluate the impact of various configurations of speech encoders, LLMs, and projector modules in the context of the speech foundation encoder-LLM ASR paradigm. Furthermore, we introduce a three-stage training approach, expressly developed to enhance the model's ability to align auditory and textual information. The implementation of this approach, alongside the strategic integration of ASR components, enabled us to achieve the SOTA performance on the AISHELL-1, Test_Net, and Test_Meeting test sets. Our analysis presents an empirical foundation for future research in LLM-based ASR systems and offers insights into optimizing performance using Chinese datasets. We will publicly release all scripts used for data preparation, training, inference, and scoring, as well as pre-trained models and training logs to promote reproducible research.