 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelayed-KD: Delayed Knowledge Distillation based CTC for Low-Latency Streaming ASR
May 28, 2025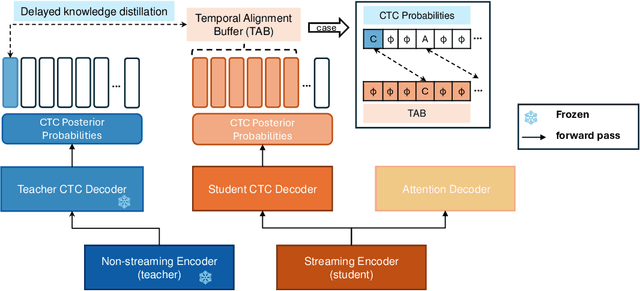

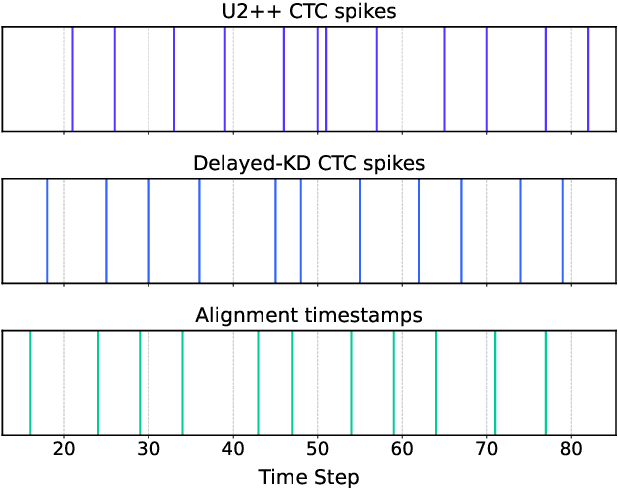
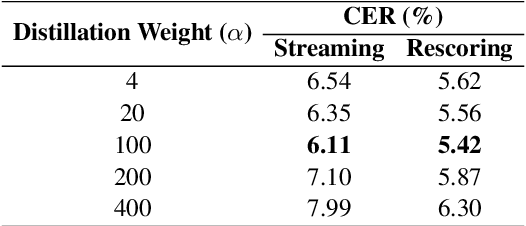
CTC-based streaming ASR has gained significant attention in real-world applications but faces two main challenges: accuracy degradation in small chunks and token emission latency. To mitigate these challenges, we propose Delayed-KD, which applies delayed knowledge distillation on CTC posterior probabilities from a non-streaming to a streaming model. Specifically, with a tiny chunk size, we introduce a Temporal Alignment Buffer (TAB) that defines a relative delay range compared to the non-streaming teacher model to align CTC outputs and mitigate non-blank token mismatches. Additionally, TAB enables fine-grained control over token emission delay. Experiments on 178-hour AISHELL-1 and 10,000-hour WenetSpeech Mandarin datasets show consistent superiority of Delayed-KD. Impressively, Delayed-KD at 40 ms latency achieves a lower character error rate (CER) of 5.42% on AISHELL-1, comparable to the competitive U2++ model running at 320 ms latency.
VITA-1.5: Towards GPT-4o Level Real-Time Vision and Speech Interaction
Jan 03, 2025



Recent Multimodal Large Language Models (MLLMs) have typically focused on integrating visual and textual modalities, with less emphasis placed on the role of speech in enhancing interaction. However, speech plays a crucial role in multimodal dialogue systems, and implementing high-performance in both vision and speech tasks remains a significant challenge due to the fundamental modality differences. In this paper, we propose a carefully designed multi-stage training methodology that progressively trains LLM to understand both visual and speech information, ultimately enabling fluent vision and speech interaction. Our approach not only preserves strong vision-language capacity, but also enables efficient speech-to-speech dialogue capabilities without separate ASR and TTS modules, significantly accelerating multimodal end-to-end response speed. By comparing our method against state-of-the-art counterparts across benchmarks for image, video, and speech tasks, we demonstrate that our model is equipped with both strong visual and speech capabilities, making near real-time vision and speech interaction.
Freeze-Omni: A Smart and Low Latency Speech-to-speech Dialogue Model with Frozen LLM
Nov 01, 2024



The rapid development of large language models has brought many new smart applications, especially the excellent multimodal human-computer interaction in GPT-4o has brought impressive experience to users. In this background, researchers have proposed many multimodal LLMs that can achieve speech-to-speech dialogue recently. In this paper, we propose a speech-text multimodal LLM architecture called Freeze-Omni. Our main contribution is the speech input and output modalities can connected to the LLM while keeping the LLM frozen throughout the training process. We designed 3-stage training strategies both for the modeling of speech input and output, enabling Freeze-Omni to obtain speech-to-speech dialogue ability using text-speech paired data (such as ASR and TTS data) and only 60,000 multi-round text Q&A data on 8 GPUs. Moreover, we can effectively ensure that the intelligence of the Freeze-Omni in the speech modality is at the same level compared with that in the text modality of its backbone LLM, while the end-to-end latency of the spoken response achieves a low level. In addition, we also designed a method to achieve duplex dialogue ability through multi-task training, making Freeze-Omni have a more natural style of dialogue ability between the users. Freeze-Omni mainly provides a possibility for researchers to conduct multimodal LLM under the condition of a frozen LLM, avoiding various impacts caused by the catastrophic forgetting of LLM caused by fewer data and training resources.
A Transcription Prompt-based Efficient Audio Large Language Model for Robust Speech Recognition
Aug 18, 2024Audio-LLM introduces audio modality into a large language model (LLM) to enable a powerful LLM to recognize, understand, and generate audio. However, during speech recognition in noisy environments, we observed the presence of illusions and repetition issues in audio-LLM, leading to substitution and insertion errors. This paper proposes a transcription prompt-based audio-LLM by introducing an ASR expert as a transcription tokenizer and a hybrid Autoregressive (AR) Non-autoregressive (NAR) decoding approach to solve the above problems. Experiments on 10k-hour WenetSpeech Mandarin corpus show that our approach decreases 12.2% and 9.6% CER relatively on Test_Net and Test_Meeting evaluation sets compared with baseline. Notably, we reduce the decoding repetition rate on the evaluation set to zero, showing that the decoding repetition problem has been solved fundamentally.
MMGER: Multi-modal and Multi-granularity Generative Error Correction with LLM for Joint Accent and Speech Recognition
May 06, 2024



Despite notable advancements in automatic speech recognition (ASR), performance tends to degrade when faced with adverse conditions. Generative error correction (GER) leverages the exceptional text comprehension capabilities of large language models (LLM), delivering impressive performance in ASR error correction, where N-best hypotheses provide valuable information for transcription prediction. However, GER encounters challenges such as fixed N-best hypotheses, insufficient utilization of acoustic information, and limited specificity to multi-accent scenarios. In this paper, we explore the application of GER in multi-accent scenarios. Accents represent deviations from standard pronunciation norms, and the multi-task learning framework for simultaneous ASR and accent recognition (AR) has effectively addressed the multi-accent scenarios, making it a prominent solution. In this work, we propose a unified ASR-AR GER model, named MMGER, leveraging multi-modal correction, and multi-granularity correction. Multi-task ASR-AR learning is employed to provide dynamic 1-best hypotheses and accent embeddings. Multi-modal correction accomplishes fine-grained frame-level correction by force-aligning the acoustic features of speech with the corresponding character-level 1-best hypothesis sequence. Multi-granularity correction supplements the global linguistic information by incorporating regular 1-best hypotheses atop fine-grained multi-modal correction to achieve coarse-grained utterance-level correction. MMGER effectively mitigates the limitations of GER and tailors LLM-based ASR error correction for the multi-accent scenarios. Experiments conducted on the multi-accent Mandarin KeSpeech dataset demonstrate the efficacy of MMGER, achieving a 26.72% relative improvement in AR accuracy and a 27.55% relative reduction in ASR character error rate, compared to a well-established standard baseline.
Unveiling the Potential of LLM-Based ASR on Chinese Open-Source Datasets
May 06, 2024



Large Language Models (LLMs) have demonstrated unparalleled effectiveness in various NLP tasks, and integrating LLMs with automatic speech recognition (ASR) is becoming a mainstream paradigm. Building upon this momentum, our research delves into an in-depth examination of this paradigm on a large open-source Chinese dataset. Specifically, our research aims to evaluate the impact of various configurations of speech encoders, LLMs, and projector modules in the context of the speech foundation encoder-LLM ASR paradigm. Furthermore, we introduce a three-stage training approach, expressly developed to enhance the model's ability to align auditory and textual information. The implementation of this approach, alongside the strategic integration of ASR components, enabled us to achieve the SOTA performance on the AISHELL-1, Test_Net, and Test_Meeting test sets. Our analysis presents an empirical foundation for future research in LLM-based ASR systems and offers insights into optimizing performance using Chinese datasets. We will publicly release all scripts used for data preparation, training, inference, and scoring, as well as pre-trained models and training logs to promote reproducible research.
SA-Paraformer: Non-autoregressive End-to-End Speaker-Attributed ASR
Oct 07, 2023



Joint modeling of multi-speaker ASR and speaker diarization has recently shown promising results in speaker-attributed automatic speech recognition (SA-ASR).Although being able to obtain state-of-the-art (SOTA) performance, most of the studies are based on an autoregressive (AR) decoder which generates tokens one-by-one and results in a large real-time factor (RTF). To speed up inference, we introduce a recently proposed non-autoregressive model Paraformer as an acoustic model in the SA-ASR model.Paraformer uses a single-step decoder to enable parallel generation, obtaining comparable performance to the SOTA AR transformer models. Besides, we propose a speaker-filling strategy to reduce speaker identification errors and adopt an inter-CTC strategy to enhance the encoder's ability in acoustic modeling. Experiments on the AliMeeting corpus show that our model outperforms the cascaded SA-ASR model by a 6.1% relative speaker-dependent character error rate (SD-CER) reduction on the test set. Moreover, our model achieves a comparable SD-CER of 34.8% with only 1/10 RTF compared with the SOTA joint AR SA-ASR model.
The second multi-channel multi-party meeting transcription challenge 2.0): A benchmark for speaker-attributed ASR
Sep 24, 2023



With the success of the first Multi-channel Multi-party Meeting Transcription challenge (M2MeT), the second M2MeT challenge (M2MeT 2.0) held in ASRU2023 particularly aims to tackle the complex task of speaker-attributed ASR (SA-ASR), which directly addresses the practical and challenging problem of "who spoke what at when" at typical meeting scenario. We particularly established two sub-tracks. 1) The fixed training condition sub-track, where the training data is constrained to predetermined datasets, but participants can use any open-source pre-trained model. 2) The open training condition sub-track, which allows for the use of all available data and models. In addition, we release a new 10-hour test set for challenge ranking. This paper provides an overview of the dataset, track settings, results, and analysis of submitted systems, as a benchmark to show the current state of speaker-attributed ASR.
BA-SOT: Boundary-Aware Serialized Output Training for Multi-Talker ASR
May 23, 2023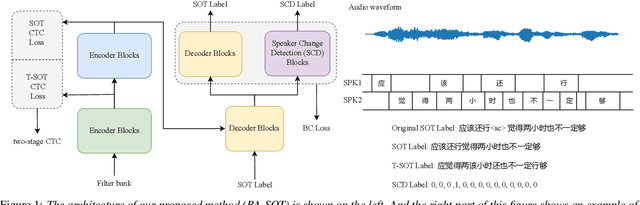
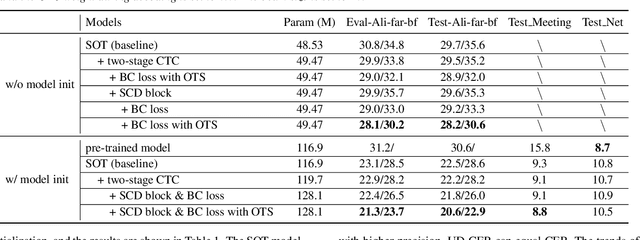
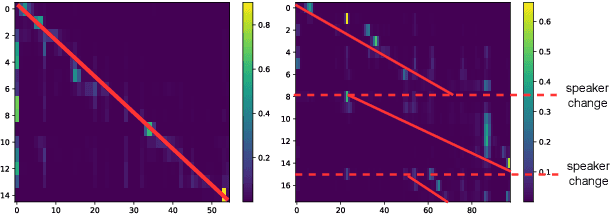
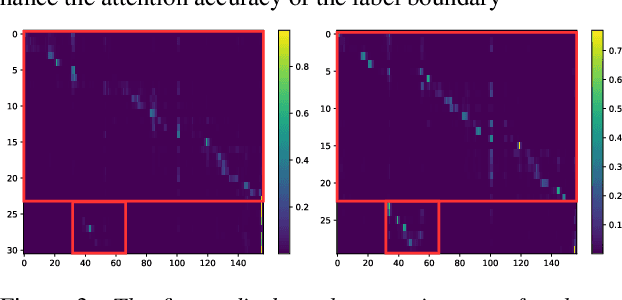
The recently proposed serialized output training (SOT) simplifies multi-talker automatic speech recognition (ASR) by generating speaker transcriptions separated by a special token. However, frequent speaker changes can make speaker change prediction difficult. To address this, we propose boundary-aware serialized output training (BA-SOT), which explicitly incorporates boundary knowledge into the decoder via a speaker change detection task and boundary constraint loss. We also introduce a two-stage connectionist temporal classification (CTC) strategy that incorporates token-level SOT CTC to restore temporal context information. Besides typical character error rate (CER), we introduce utterance-dependent character error rate (UD-CER) to further measure the precision of speaker change prediction. Compared to original SOT, BA-SOT reduces CER/UD-CER by 5.1%/14.0%, and leveraging a pre-trained ASR model for BA-SOT model initialization further reduces CER/UD-CER by 8.4%/19.9%.
CASA-ASR: Context-Aware Speaker-Attributed ASR
May 21, 2023



Recently, speaker-attributed automatic speech recognition (SA-ASR) has attracted a wide attention, which aims at answering the question ``who spoke what''. Different from modular systems, end-to-end (E2E) SA-ASR minimizes the speaker-dependent recognition errors directly and shows a promising applicability. In this paper, we propose a context-aware SA-ASR (CASA-ASR) model by enhancing the contextual modeling ability of E2E SA-ASR. Specifically, in CASA-ASR, a contextual text encoder is involved to aggregate the semantic information of the whole utterance, and a context-dependent scorer is employed to model the speaker discriminability by contrasting with speakers in the context. In addition, a two-pass decoding strategy is further proposed to fully leverage the contextual modeling ability resulting in a better recognition performance. Experimental results on AliMeeting corpus show that the proposed CASA-ASR model outperforms the original E2E SA-ASR system with a relative improvement of 11.76% in terms of speaker-dependent character error rate.