 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Structure Learning: Disentangling Shared and Specific Topology via Cross-Modal Graphical Lasso
Apr 05, 2026Learning interpretable multimodal representations inherently relies on uncovering the conditional dependencies between heterogeneous features. However, sparse graph estimation techniques, such as Graphical Lasso (GLasso), to visual-linguistic domains is severely bottlenecked by high-dimensional noise, modality misalignment, and the confounding of shared versus category-specific topologies. In this paper, we propose Cross-Modal Graphical Lasso (CM-GLasso) that overcomes these fundamental limitations. By coupling a novel text-visualization strategy with a unified vision-language encoder, we strictly align multimodal features into a shared latent space. We introduce a cross-attention distillation mechanism that condenses high-dimensional patches into explicit semantic nodes, naturally extracting spatial-aware cross-modal priors. Furthermore, we unify tailored GLasso estimation and Common-Specific Structure Learning (CSSL) into a joint objective optimized via the Alternating Direction Method of Multiplier (ADMM). This formulation guarantees the simultaneous disentanglement of invariant and class-specific precision matrices without multi-step error accumulation. Extensive experiments across eight benchmarks covering both natural and medical domains demonstrate that CM-GLasso establishes a new state-of-the-art in generative classification and dense semantic segmentation tasks.
Learning Multi-type heterogeneous interacting particle systems
Feb 03, 2026We propose a framework for the joint inference of network topology, multi-type interaction kernels, and latent type assignments in heterogeneous interacting particle systems from multi-trajectory data. This learning task is a challenging non-convex mixed-integer optimization problem, which we address through a novel three-stage approach. First, we leverage shared structure across agent interactions to recover a low-rank embedding of the system parameters via matrix sensing. Second, we identify discrete interaction types by clustering within the learned embedding. Third, we recover the network weight matrix and kernel coefficients through matrix factorization and a post-processing refinement. We provide theoretical guarantees with estimation error bounds under a Restricted Isometry Property (RIP) assumption and establish conditions for the exact recovery of interaction types based on cluster separability. Numerical experiments on synthetic datasets, including heterogeneous predator-prey systems, demonstrate that our method yields an accurate reconstruction of the underlying dynamics and is robust to noise.
Qwen3-ASR Technical Report
Jan 29, 2026In this report, we introduce Qwen3-ASR family, which includes two powerful all-in-one speech recognition models and a novel non-autoregressive speech forced alignment model. Qwen3-ASR-1.7B and Qwen3-ASR-0.6B are ASR models that support language identification and ASR for 52 languages and dialects. Both of them leverage large-scale speech training data and the strong audio understanding ability of their foundation model Qwen3-Omni. We conduct comprehensive internal evaluation besides the open-sourced benchmarks as ASR models might differ little on open-sourced benchmark scores but exhibit significant quality differences in real-world scenarios. The experiments reveal that the 1.7B version achieves SOTA performance among open-sourced ASR models and is competitive with the strongest proprietary APIs while the 0.6B version offers the best accuracy-efficiency trade-off. Qwen3-ASR-0.6B can achieve an average TTFT as low as 92ms and transcribe 2000 seconds speech in 1 second at a concurrency of 128. Qwen3-ForcedAligner-0.6B is an LLM based NAR timestamp predictor that is able to align text-speech pairs in 11 languages. Timestamp accuracy experiments show that the proposed model outperforms the three strongest force alignment models and takes more advantages in efficiency and versatility. To further accelerate the community research of ASR and audio understanding, we release these models under the Apache 2.0 license.
LLM-ForcedAligner: A Non-Autoregressive and Accurate LLM-Based Forced Aligner for Multilingual and Long-Form Speech
Jan 26, 2026Forced alignment (FA) predicts start and end timestamps for words or characters in speech, but existing methods are language-specific and prone to cumulative temporal shifts. The multilingual speech understanding and long-sequence processing abilities of speech large language models (SLLMs) make them promising for FA in multilingual, crosslingual, and long-form speech settings. However, directly applying the next-token prediction paradigm of SLLMs to FA results in hallucinations and slow inference. To bridge the gap, we propose LLM-ForcedAligner, reformulating FA as a slot-filling paradigm: timestamps are treated as discrete indices, and special timestamp tokens are inserted as slots into the transcript. Conditioned on the speech embeddings and the transcript with slots, the SLLM directly predicts the time indices at slots. During training, causal attention masking with non-shifted input and label sequences allows each slot to predict its own timestamp index based on itself and preceding context, with loss computed only at slot positions. Dynamic slot insertion enables FA at arbitrary positions. Moreover, non-autoregressive inference is supported, avoiding hallucinations and improving speed. Experiments across multilingual, crosslingual, and long-form speech scenarios show that LLM-ForcedAligner achieves a 69%~78% relative reduction in accumulated averaging shift compared with prior methods. The checkpoint and inference code will be released later.
Qwen3-TTS Technical Report
Jan 22, 2026In this report, we present the Qwen3-TTS series, a family of advanced multilingual, controllable, robust, and streaming text-to-speech models. Qwen3-TTS supports state-of-the-art 3-second voice cloning and description-based control, allowing both the creation of entirely novel voices and fine-grained manipulation over the output speech. Trained on over 5 million hours of speech data spanning 10 languages, Qwen3-TTS adopts a dual-track LM architecture for real-time synthesis, coupled with two speech tokenizers: 1) Qwen-TTS-Tokenizer-25Hz is a single-codebook codec emphasizing semantic content, which offers seamlessly integration with Qwen-Audio and enables streaming waveform reconstruction via a block-wise DiT. 2) Qwen-TTS-Tokenizer-12Hz achieves extreme bitrate reduction and ultra-low-latency streaming, enabling immediate first-packet emission ($97\,\mathrm{ms}$) through its 12.5 Hz, 16-layer multi-codebook design and a lightweight causal ConvNet. Extensive experiments indicate state-of-the-art performance across diverse objective and subjective benchmark (e.g., TTS multilingual test set, InstructTTSEval, and our long speech test set). To facilitate community research and development, we release both tokenizers and models under the Apache 2.0 license.
Real-Time Lane Detection via Efficient Feature Alignment and Covariance Optimization for Low-Power Embedded Systems
Jan 05, 2026Real-time lane detection in embedded systems encounters significant challenges due to subtle and sparse visual signals in RGB images, often constrained by limited computational resources and power consumption. Although deep learning models for lane detection categorized into segmentation-based, anchor-based, and curve-based methods there remains a scarcity of universally applicable optimization techniques tailored for low-power embedded environments. To overcome this, we propose an innovative Covariance Distribution Optimization (CDO) module specifically designed for efficient, real-time applications. The CDO module aligns lane feature distributions closely with ground-truth labels, significantly enhancing detection accuracy without increasing computational complexity. Evaluations were conducted on six diverse models across all three method categories, including two optimized for real-time applications and four state-of-the-art (SOTA) models, tested comprehensively on three major datasets: CULane, TuSimple, and LLAMAS. Experimental results demonstrate accuracy improvements ranging from 0.01% to 1.5%. The proposed CDO module is characterized by ease of integration into existing systems without structural modifications and utilizes existing model parameters to facilitate ongoing training, thus offering substantial benefits in performance, power efficiency, and operational flexibility in embedded systems.
B2LoRa: Boosting LoRa Transmission for Satellite-IoT Systems with Blind Coherent Combining
May 30, 2025With the rapid growth of Low Earth Orbit (LEO) satellite networks, satellite-IoT systems using the LoRa technique have been increasingly deployed to provide widespread Internet services to low-power and low-cost ground devices. However, the long transmission distance and adverse environments from IoT satellites to ground devices pose a huge challenge to link reliability, as evidenced by the measurement results based on our real-world setup. In this paper, we propose a blind coherent combining design named B2LoRa to boost LoRa transmission performance. The intuition behind B2LoRa is to leverage the repeated broadcasting mechanism inherent in satellite-IoT systems to achieve coherent combining under the low-power and low-cost constraints, where each re-transmission at different times is regarded as the same packet transmitted from different antenna elements within an antenna array. Then, the problem is translated into aligning these packets at a fine granularity despite the time, frequency, and phase offsets between packets in the case of frequent packet loss. To overcome this challenge, we present three designs - joint packet sniffing, frequency shift alignment, and phase drift mitigation to deal with ultra-low SNRs and Doppler shifts featured in satellite-IoT systems, respectively. Finally, experiment results based on our real-world deployments demonstrate the high efficiency of B2LoRa.
SFL-LEO: Asynchronous Split-Federated Learning Design for LEO Satellite-Ground Network Framework
Apr 18, 2025
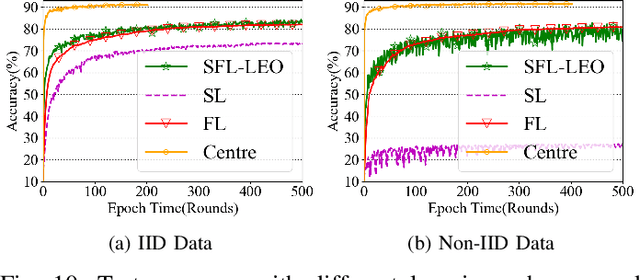
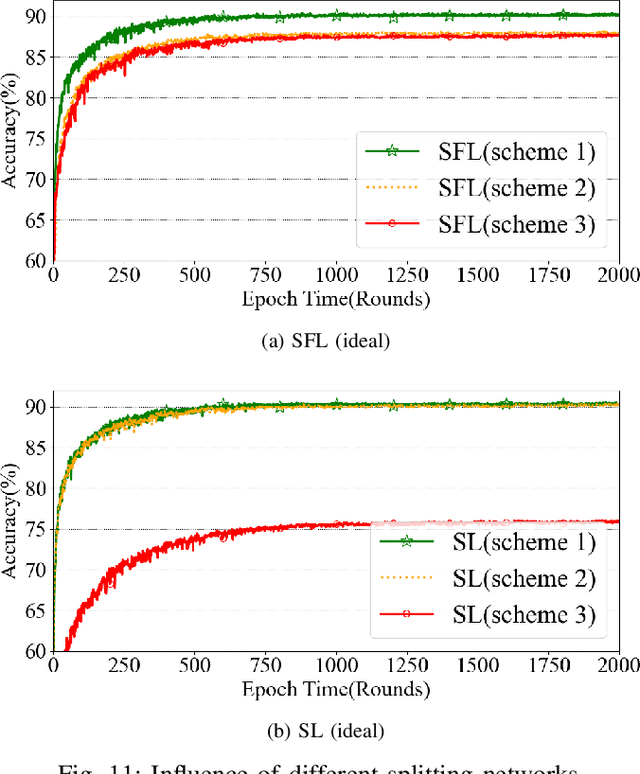
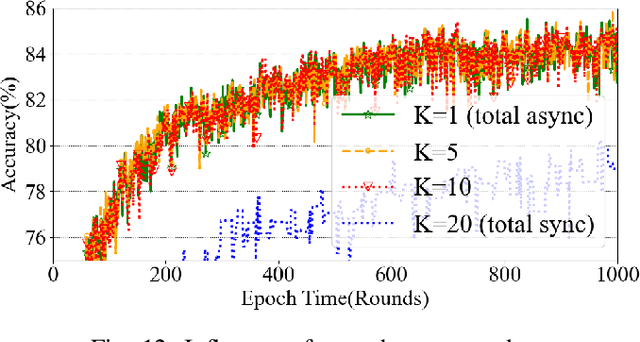
Recently, the rapid development of LEO satellite networks spurs another widespread concern-data processing at satellites. However, achieving efficient computation at LEO satellites in highly dynamic satellite networks is challenging and remains an open problem when considering the constrained computation capability of LEO satellites. For the first time, we propose a novel distributed learning framework named SFL-LEO by combining Federated Learning (FL) with Split Learning (SL) to accommodate the high dynamics of LEO satellite networks and the constrained computation capability of LEO satellites by leveraging the periodical orbit traveling feature. The proposed scheme allows training locally by introducing an asynchronous training strategy, i.e., achieving local update when LEO satellites disconnect with the ground station, to provide much more training space and thus increase the training performance. Meanwhile, it aggregates client-side sub-models at the ground station and then distributes them to LEO satellites by borrowing the idea from the federated learning scheme. Experiment results driven by satellite-ground bandwidth measured in Starlink demonstrate that SFL-LEO provides a similar accuracy performance with the conventional SL scheme because it can perform local training even within the disconnection duration.
Qwen2.5-Omni Technical Report
Mar 26, 2025



In this report, we present Qwen2.5-Omni, an end-to-end multimodal model designed to perceive diverse modalities, including text, images, audio, and video, while simultaneously generating text and natural speech responses in a streaming manner. To enable the streaming of multimodal information inputs, both audio and visual encoders utilize a block-wise processing approach. To synchronize the timestamps of video inputs with audio, we organize the audio and video sequentially in an interleaved manner and propose a novel position embedding approach, named TMRoPE(Time-aligned Multimodal RoPE). To concurrently generate text and speech while avoiding interference between the two modalities, we propose \textbf{Thinker-Talker} architecture. In this framework, Thinker functions as a large language model tasked with text generation, while Talker is a dual-track autoregressive model that directly utilizes the hidden representations from the Thinker to produce audio tokens as output. Both the Thinker and Talker models are designed to be trained and inferred in an end-to-end manner. For decoding audio tokens in a streaming manner, we introduce a sliding-window DiT that restricts the receptive field, aiming to reduce the initial package delay. Qwen2.5-Omni is comparable with the similarly sized Qwen2.5-VL and outperforms Qwen2-Audio. Furthermore, Qwen2.5-Omni achieves state-of-the-art performance on multimodal benchmarks like Omni-Bench. Notably, Qwen2.5-Omni's performance in end-to-end speech instruction following is comparable to its capabilities with text inputs, as evidenced by benchmarks such as MMLU and GSM8K. As for speech generation, Qwen2.5-Omni's streaming Talker outperforms most existing streaming and non-streaming alternatives in robustness and naturalness.
InSerter: Speech Instruction Following with Unsupervised Interleaved Pre-training
Mar 04, 2025



Recent advancements in speech large language models (SpeechLLMs) have attracted considerable attention. Nonetheless, current methods exhibit suboptimal performance in adhering to speech instructions. Notably, the intelligence of models significantly diminishes when processing speech-form input as compared to direct text-form input. Prior work has attempted to mitigate this semantic inconsistency between speech and text representations through techniques such as representation and behavior alignment, which involve the meticulous design of data pairs during the post-training phase. In this paper, we introduce a simple and scalable training method called InSerter, which stands for Interleaved Speech-Text Representation Pre-training. InSerter is designed to pre-train large-scale unsupervised speech-text sequences, where the speech is synthesized from randomly selected segments of an extensive text corpus using text-to-speech conversion. Consequently, the model acquires the ability to generate textual continuations corresponding to the provided speech segments, obviating the need for intensive data design endeavors. To systematically evaluate speech instruction-following capabilities, we introduce SpeechInstructBench, the first comprehensive benchmark specifically designed for speech-oriented instruction-following tasks. Our proposed InSerter achieves SOTA performance in SpeechInstructBench and demonstrates superior or competitive results across diverse speech processing tasks.