 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTRIDE-ED: A Strategy-Grounded Stepwise Reasoning Framework for Empathetic Dialogue Systems
Apr 08, 2026Empathetic dialogue requires not only recognizing a user's emotional state but also making strategy-aware, context-sensitive decisions throughout response generation. However, the lack of a comprehensive empathy strategy framework, explicit task-aligned multi-stage reasoning, and high-quality strategy-aware data fundamentally limits existing approaches, preventing them from effectively modeling empathetic dialogue as a complex, multi-stage cognitive and decision-making process. To address these challenges, we propose STRIDE-ED, a STRategy-grounded, Interpretable, and DEep reasoning framework that models Empathetic Dialogue through structured, strategy-conditioned reasoning. To support effective learning, we develop a strategy-aware data refinement pipeline integrating LLM-based annotation, multi-model consistency-weighted evaluation, and dynamic sampling to construct high-quality training data aligned with empathetic strategies. Furthermore, we adopt a two-stage training paradigm that combines supervised fine-tuning with multi-objective reinforcement learning to better align model behaviors with target emotions, empathetic strategies, and response formats. Extensive experiments demonstrate that STRIDE-ED generalizes across diverse open-source LLMs and consistently outperforms existing methods on both automatic metrics and human evaluations.
O-ConNet: Geometry-Aware End-to-End Inference of Over-Constrained Spatial Mechanisms
Apr 02, 2026Deep learning has shown strong potential for scientific discovery, but its ability to model macroscopic rigid-body kinematic constraints remains underexplored. We study this problem on spatial over-constrained mechanisms and propose O-ConNet, an end-to-end framework that infers mechanism structural parameters from only three sparse reachable points while reconstructing the full motion trajectory, without explicitly solving constraint equations during inference. On a self-constructed Bennett 4R dataset of 42,860 valid samples, O-ConNet achieves Param-MAE 0.276 +/- 0.077 and Traj-MAE 0.145 +/- 0.018 (mean +/- std over 10 runs), outperforming the strongest sequence baseline (LSTM-Seq2Seq) by 65.1 percent and 88.2 percent, respectively. These results suggest that end-to-end learning can capture closed-loop geometric structure and provide a practical route for inverse design of spatial over-constrained mechanisms under extremely sparse observations.
Toward Temporal Causal Representation Learning with Tensor Decomposition
Jul 18, 2025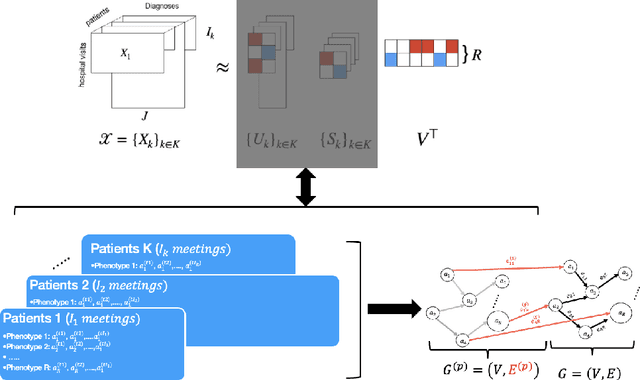
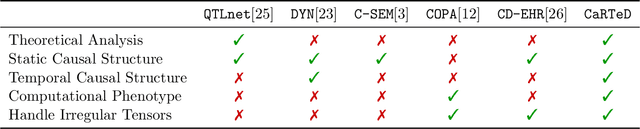
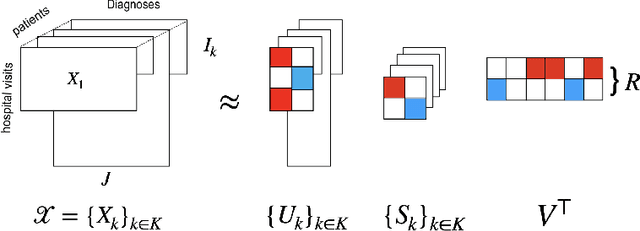
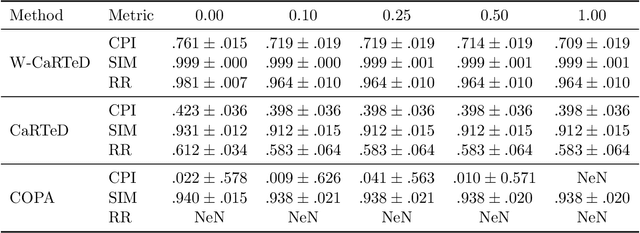
Temporal causal representation learning is a powerful tool for uncovering complex patterns in observational studies, which are often represented as low-dimensional time series. However, in many real-world applications, data are high-dimensional with varying input lengths and naturally take the form of irregular tensors. To analyze such data, irregular tensor decomposition is critical for extracting meaningful clusters that capture essential information. In this paper, we focus on modeling causal representation learning based on the transformed information. First, we present a novel causal formulation for a set of latent clusters. We then propose CaRTeD, a joint learning framework that integrates temporal causal representation learning with irregular tensor decomposition. Notably, our framework provides a blueprint for downstream tasks using the learned tensor factors, such as modeling latent structures and extracting causal information, and offers a more flexible regularization design to enhance tensor decomposition. Theoretically, we show that our algorithm converges to a stationary point. More importantly, our results fill the gap in theoretical guarantees for the convergence of state-of-the-art irregular tensor decomposition. Experimental results on synthetic and real-world electronic health record (EHR) datasets (MIMIC-III), with extensive benchmarks from both phenotyping and network recovery perspectives, demonstrate that our proposed method outperforms state-of-the-art techniques and enhances the explainability of causal representations.
Association between nutritional factors, inflammatory biomarkers and cancer types: an analysis of NHANES data using machine learning
Apr 18, 2025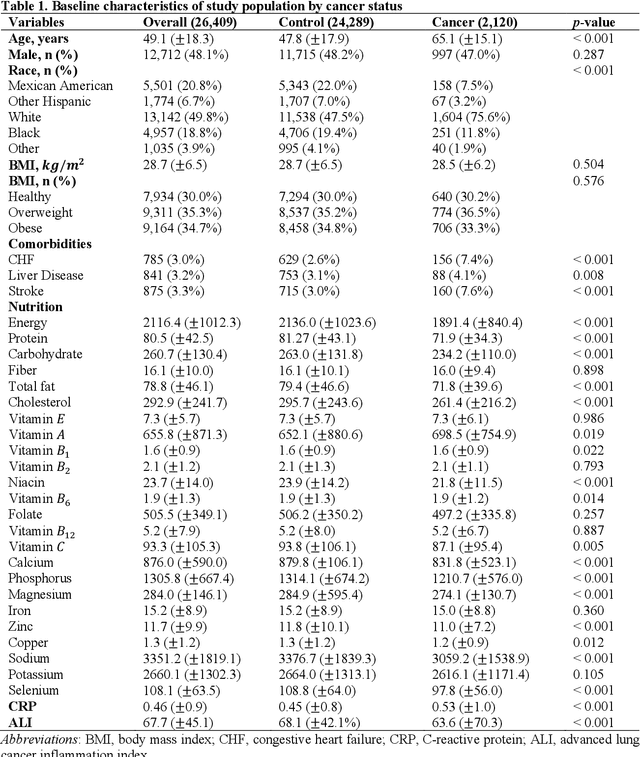
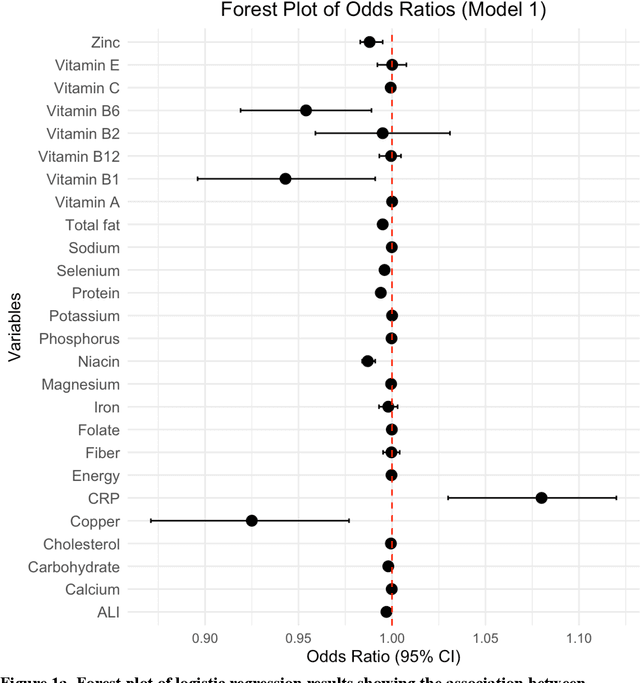
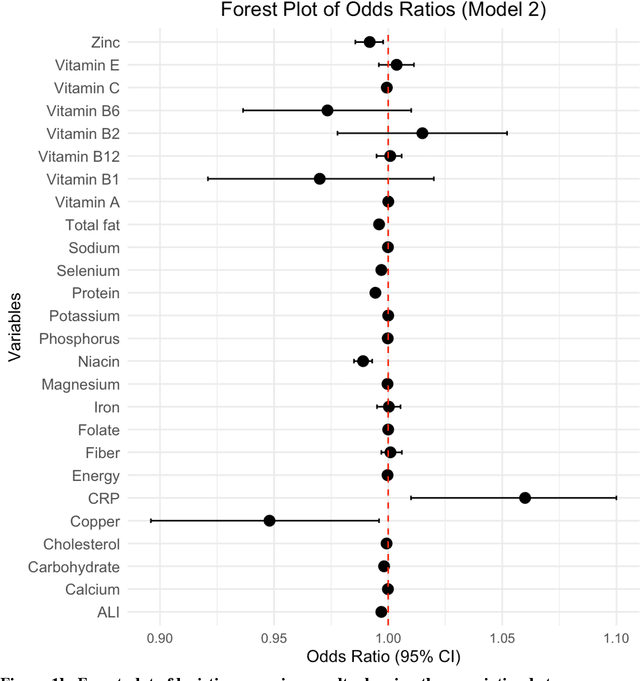

Background. Diet and inflammation are critical factors influencing cancer risk. However, the combined impact of nutritional status and inflammatory biomarkers on cancer status and type, using machine learning (ML), remains underexplored. Objectives. This study investigates the association between nutritional factors, inflammatory biomarkers, and cancer status, and whether these relationships differ across cancer types using National Health and Nutrition Examination Survey (NHANES) data. Methods. We analyzed 24 macro- and micronutrients, C-reactive protein (CRP), and the advanced lung cancer inflammation index (ALI) in 26,409 NHANES participants (2,120 with cancer). Multivariable logistic regression assessed associations with cancer prevalence. We also examined whether these features differed across the five most common cancer types. To evaluate predictive value, we applied three ML models - Logistic Regression, Random Forest, and XGBoost - on the full feature set. Results. The cohort's mean age was 49.1 years; 34.7% were obese. Comorbidities such as anemia and liver conditions, along with nutritional factors like protein and several vitamins, were key predictors of cancer status. Among the models, Random Forest performed best, achieving an accuracy of 0.72. Conclusions. Higher-quality nutritional intake and lower levels of inflammation may offer protective effects against cancer. These findings highlight the potential of combining nutritional and inflammatory markers with ML to inform cancer prevention strategies.
Selective Complementary Feature Fusion and Modal Feature Compression Interaction for Brain Tumor Segmentation
Mar 20, 2025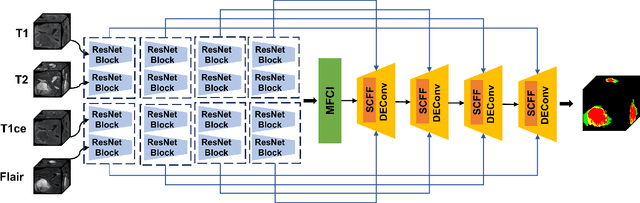
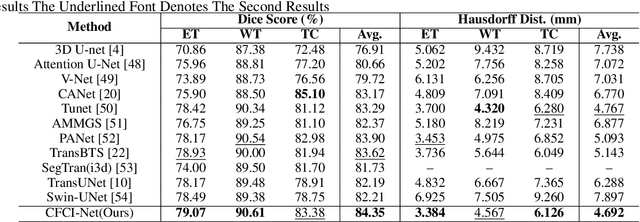
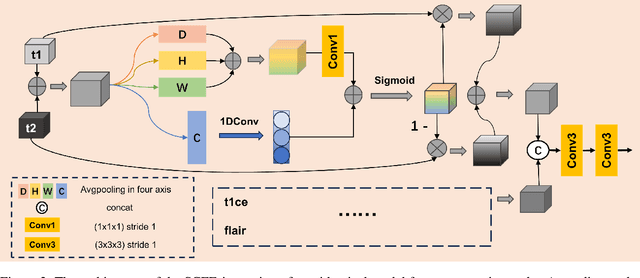
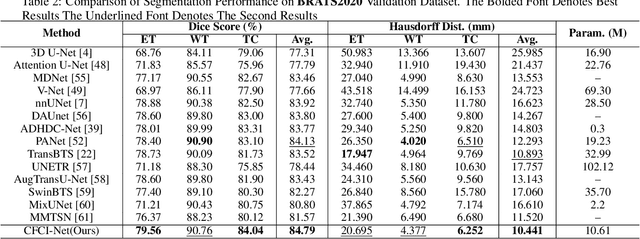
Efficient modal feature fusion strategy is the key to achieve accurate segmentation of brain glioma. However, due to the specificity of different MRI modes, it is difficult to carry out cross-modal fusion with large differences in modal features, resulting in the model ignoring rich feature information. On the other hand, the problem of multi-modal feature redundancy interaction occurs in parallel networks due to the proliferation of feature dimensions, further increase the difficulty of multi-modal feature fusion at the bottom end. In order to solve the above problems, we propose a noval complementary feature compression interaction network (CFCI-Net), which realizes the complementary fusion and compression interaction of multi-modal feature information with an efficient mode fusion strategy. Firstly, we propose a selective complementary feature fusion (SCFF) module, which adaptively fuses rich cross-modal feature information by complementary soft selection weights. Secondly, a modal feature compression interaction (MFCI) transformer is proposed to deal with the multi-mode fusion redundancy problem when the feature dimension surges. The MFCI transformer is composed of modal feature compression (MFC) and modal feature interaction (MFI) to realize redundancy feature compression and multi-mode feature interactive learning. %In MFI, we propose a hierarchical interactive attention mechanism based on multi-head attention. Evaluations on the BraTS2019 and BraTS2020 datasets demonstrate that CFCI-Net achieves superior results compared to state-of-the-art models. Code: https://github.com/CDmm0/CFCI-Net
Can xLLMs Understand the Structure of Dialog? Exploring Multilingual Response Generation in Complex Scenarios
Jan 20, 2025Multilingual research has garnered increasing attention, especially in the domain of dialogue systems. The rapid advancements in large language models (LLMs) have fueled the demand for high-performing multilingual models. However, two major challenges persist: the scarcity of high-quality multilingual datasets and the limited complexity of existing datasets in capturing realistic dialogue scenarios. To address these gaps, we introduce XMP, a high-quality parallel Multilingual dataset sourced from Multi-party Podcast dialogues. Each sample in the dataset features at least three participants discussing a wide range of topics, including society, culture, politics, and entertainment.Through extensive experiments, we uncover significant limitations in previously recognized multilingual capabilities of LLMs when applied to such complex dialogue scenarios. For instance, the widely accepted multilingual complementary ability of LLMs is notably impacted. By conducting further experiments, we explore the mechanisms of LLMs in multilingual environments from multiple perspectives, shedding new light on their performance in real-world, diverse conversational contexts.
Advancing Multi-Party Dialogue Systems with Speaker-ware Contrastive Learning
Jan 20, 2025


Dialogue response generation has made significant progress, but most research has focused on dyadic dialogue. In contrast, multi-party dialogues involve more participants, each potentially discussing different topics, making the task more complex. Current methods often rely on graph neural networks to model dialogue context, which helps capture the structural dynamics of multi-party conversations. However, these methods are heavily dependent on intricate graph structures and dataset annotations, and they often overlook the distinct speaking styles of participants. To address these challenges, we propose CMR, a Contrastive learning-based Multi-party dialogue Response generation model. CMR uses self-supervised contrastive learning to better distinguish "who says what." Additionally, by comparing speakers within the same conversation, the model captures differences in speaking styles and thematic transitions. To the best of our knowledge, this is the first approach to apply contrastive learning in multi-party dialogue generation. Experimental results show that CMR significantly outperforms state-of-the-art models in multi-party dialogue response tasks.
Let's Be Self-generated via Step by Step: A Curriculum Learning Approach to Automated Reasoning with Large Language Models
Oct 29, 2024



While Chain of Thought (CoT) prompting approaches have significantly consolidated the reasoning capabilities of large language models (LLMs), they still face limitations that require extensive human effort or have performance needs to be improved. Existing endeavors have focused on bridging these gaps; however, these approaches either hinge on external data and cannot completely eliminate manual effort, or they fall short in effectively directing LLMs to generate high-quality exemplary prompts. To address the said pitfalls, we propose a novel prompt approach for automatic reasoning named \textbf{LBS3}, inspired by curriculum learning which better reflects human learning habits. Specifically, LBS3 initially steers LLMs to recall easy-to-hard proxy queries that are pertinent to the target query. Following this, it invokes a progressive strategy that utilizes exemplary prompts stemmed from easy-proxy queries to direct LLMs in solving hard-proxy queries, enabling the high-quality of the proxy solutions. Finally, our extensive experiments in various reasoning-intensive tasks with varying open- and closed-source LLMs show that LBS3 achieves strongly competitive performance compared to the SOTA baselines.
Self-Supervised State Space Model for Real-Time Traffic Accident Prediction Using eKAN Networks
Sep 09, 2024Accurate prediction of traffic accidents across different times and regions is vital for public safety. However, existing methods face two key challenges: 1) Generalization: Current models rely heavily on manually constructed multi-view structures, like POI distributions and road network densities, which are labor-intensive and difficult to scale across cities. 2) Real-Time Performance: While some methods improve accuracy with complex architectures, they often incur high computational costs, limiting their real-time applicability. To address these challenges, we propose SSL-eKamba, an efficient self-supervised framework for traffic accident prediction. To enhance generalization, we design two self-supervised auxiliary tasks that adaptively improve traffic pattern representation through spatiotemporal discrepancy awareness. For real-time performance, we introduce eKamba, an efficient model that redesigns the Kolmogorov-Arnold Network (KAN) architecture. This involves using learnable univariate functions for input activation and applying a selective mechanism (Selective SSM) to capture multi-variate correlations, thereby improving computational efficiency. Extensive experiments on two real-world datasets demonstrate that SSL-eKamba consistently outperforms state-of-the-art baselines. This framework may also offer new insights for other spatiotemporal tasks. Our source code is publicly available at http://github.com/KevinT618/SSL-eKamba.
VITA: Towards Open-Source Interactive Omni Multimodal LLM
Aug 09, 2024



The remarkable multimodal capabilities and interactive experience of GPT-4o underscore their necessity in practical applications, yet open-source models rarely excel in both areas. In this paper, we introduce VITA, the first-ever open-source Multimodal Large Language Model (MLLM) adept at simultaneous processing and analysis of Video, Image, Text, and Audio modalities, and meanwhile has an advanced multimodal interactive experience. Starting from Mixtral 8x7B as a language foundation, we expand its Chinese vocabulary followed by bilingual instruction tuning. We further endow the language model with visual and audio capabilities through two-stage multi-task learning of multimodal alignment and instruction tuning. VITA demonstrates robust foundational capabilities of multilingual, vision, and audio understanding, as evidenced by its strong performance across a range of both unimodal and multimodal benchmarks. Beyond foundational capabilities, we have made considerable progress in enhancing the natural multimodal human-computer interaction experience. To the best of our knowledge, we are the first to exploit non-awakening interaction and audio interrupt in MLLM. VITA is the first step for the open-source community to explore the seamless integration of multimodal understanding and interaction. While there is still lots of work to be done on VITA to get close to close-source counterparts, we hope that its role as a pioneer can serve as a cornerstone for subsequent research. Project Page: https://vita-home.github.io.