 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-LLM Query Optimization
Mar 24, 2026Deploying multiple large language models (LLMs) in parallel to classify an unknown ground-truth label is a common practice, yet the problem of optimally allocating queries across heterogeneous models remains poorly understood. In this paper, we formulate a robust, offline query-planning problem that minimizes total query cost subject to statewise error constraints which guarantee reliability for every possible ground-truth label. We first establish that this problem is NP-hard via a reduction from the minimum-weight set cover problem. To overcome this intractability, we develop a surrogate by combining a union bound decomposition of the multi-class error into pairwise comparisons with Chernoff-type concentration bounds. The resulting surrogate admits a closed-form, multiplicatively separable expression in the query counts and is guaranteed to be feasibility-preserving. We further show that the surrogate is asymptotically tight at the optimization level: the ratio of surrogate-optimal cost to true optimal cost converges to one as error tolerances shrink, with an explicit rate of $O\left(\log\log(1/α_{\min}) / \log(1/α_{\min})\right)$. Finally, we design an asymptotic fully polynomial-time approximation scheme (AFPTAS) that returns a surrogate-feasible query plan within a $(1+\varepsilon)$ factor of the surrogate optimum.
Exploring the Temporal Consistency for Point-Level Weakly-Supervised Temporal Action Localization
Feb 05, 2026Point-supervised Temporal Action Localization (PTAL) adopts a lightly frame-annotated paradigm (\textit{i.e.}, labeling only a single frame per action instance) to train a model to effectively locate action instances within untrimmed videos. Most existing approaches design the task head of models with only a point-supervised snippet-level classification, without explicit modeling of understanding temporal relationships among frames of an action. However, understanding the temporal relationships of frames is crucial because it can help a model understand how an action is defined and therefore benefits localizing the full frames of an action. To this end, in this paper, we design a multi-task learning framework that fully utilizes point supervision to boost the model's temporal understanding capability for action localization. Specifically, we design three self-supervised temporal understanding tasks: (i) Action Completion, (ii) Action Order Understanding, and (iii) Action Regularity Understanding. These tasks help a model understand the temporal consistency of actions across videos. To the best of our knowledge, this is the first attempt to explicitly explore temporal consistency for point supervision action localization. Extensive experimental results on four benchmark datasets demonstrate the effectiveness of the proposed method compared to several state-of-the-art approaches.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Boosting Point-supervised Temporal Action Localization via Text Refinement and Alignment
Feb 01, 2026Recently, point-supervised temporal action localization has gained significant attention for its effective balance between labeling costs and localization accuracy. However, current methods only consider features from visual inputs, neglecting helpful semantic information from the text side. To address this issue, we propose a Text Refinement and Alignment (TRA) framework that effectively utilizes textual features from visual descriptions to complement the visual features as they are semantically rich. This is achieved by designing two new modules for the original point-supervised framework: a Point-based Text Refinement module (PTR) and a Point-based Multimodal Alignment module (PMA). Specifically, we first generate descriptions for video frames using a pre-trained multimodal model. Next, PTR refines the initial descriptions by leveraging point annotations together with multiple pre-trained models. PMA then projects all features into a unified semantic space and leverages a point-level multimodal feature contrastive learning to reduce the gap between visual and linguistic modalities. Last, the enhanced multi-modal features are fed into the action detector for precise localization. Extensive experimental results on five widely used benchmarks demonstrate the favorable performance of our proposed framework compared to several state-of-the-art methods. Moreover, our computational overhead analysis shows that the framework can run on a single 24 GB RTX 3090 GPU, indicating its practicality and scalability.
How Close Are We? Limitations and Progress of AI Models in Banff Lesion Scoring
Oct 31, 2025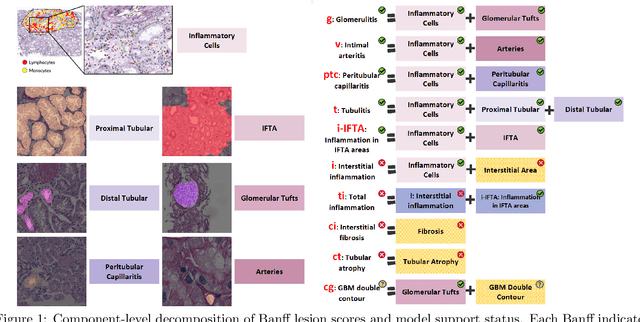
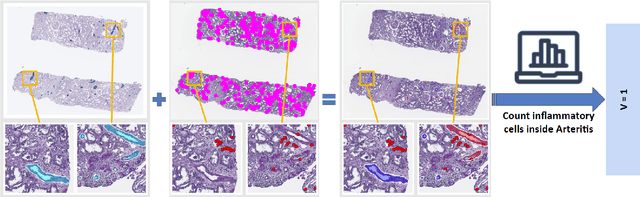
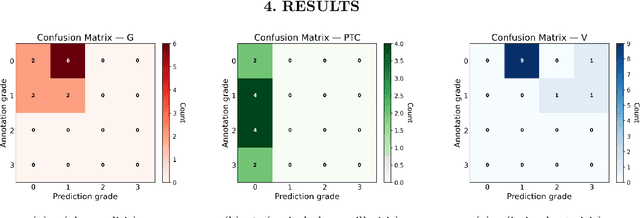
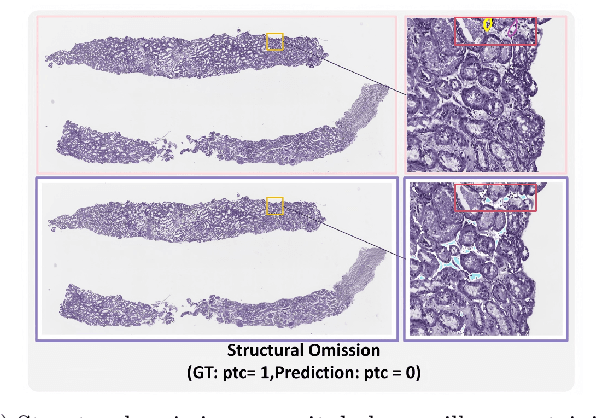
The Banff Classification provides the global standard for evaluating renal transplant biopsies, yet its semi-quantitative nature, complex criteria, and inter-observer variability present significant challenges for computational replication. In this study, we explore the feasibility of approximating Banff lesion scores using existing deep learning models through a modular, rule-based framework. We decompose each Banff indicator - such as glomerulitis (g), peritubular capillaritis (ptc), and intimal arteritis (v) - into its constituent structural and inflammatory components, and assess whether current segmentation and detection tools can support their computation. Model outputs are mapped to Banff scores using heuristic rules aligned with expert guidelines, and evaluated against expert-annotated ground truths. Our findings highlight both partial successes and critical failure modes, including structural omission, hallucination, and detection ambiguity. Even when final scores match expert annotations, inconsistencies in intermediate representations often undermine interpretability. These results reveal the limitations of current AI pipelines in replicating computational expert-level grading, and emphasize the importance of modular evaluation and computational Banff grading standard in guiding future model development for transplant pathology.
Cold-Start Recommendation with Knowledge-Guided Retrieval-Augmented Generation
May 27, 2025Cold-start items remain a persistent challenge in recommender systems due to their lack of historical user interactions, which collaborative models rely on. While recent zero-shot methods leverage large language models (LLMs) to address this, they often struggle with sparse metadata and hallucinated or incomplete knowledge. We propose ColdRAG, a retrieval-augmented generation approach that builds a domain-specific knowledge graph dynamically to enhance LLM-based recommendation in cold-start scenarios, without requiring task-specific fine-tuning. ColdRAG begins by converting structured item attributes into rich natural-language profiles, from which it extracts entities and relationships to construct a unified knowledge graph capturing item semantics. Given a user's interaction history, it scores edges in the graph using an LLM, retrieves candidate items with supporting evidence, and prompts the LLM to rank them. By enabling multi-hop reasoning over this graph, ColdRAG grounds recommendations in verifiable evidence, reducing hallucinations and strengthening semantic connections. Experiments on three public benchmarks demonstrate that ColdRAG surpasses existing zero-shot baselines in both Recall and NDCG. This framework offers a practical solution to cold-start recommendation by combining knowledge-graph reasoning with retrieval-augmented LLM generation.
Association between nutritional factors, inflammatory biomarkers and cancer types: an analysis of NHANES data using machine learning
Apr 18, 2025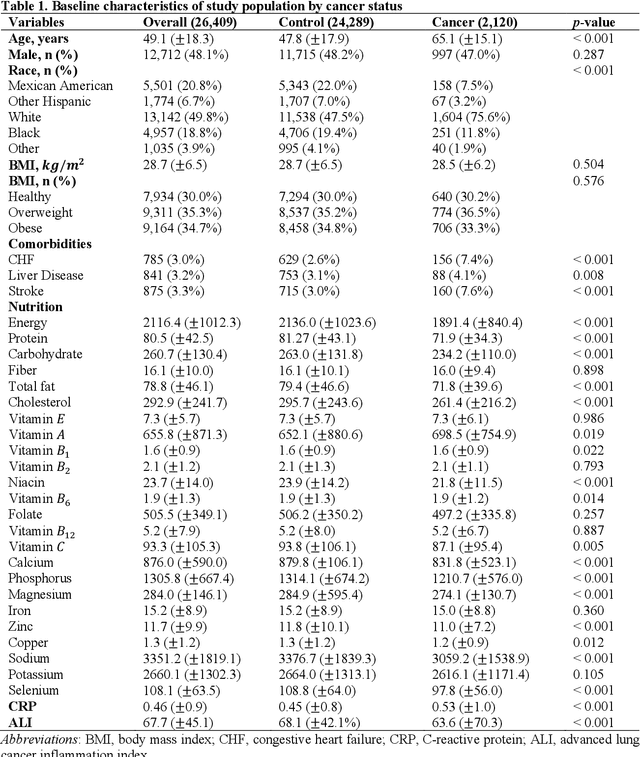
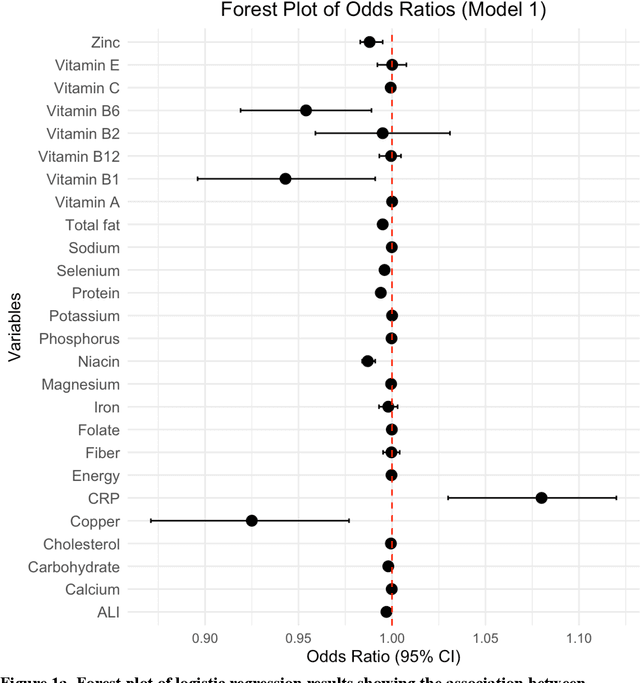
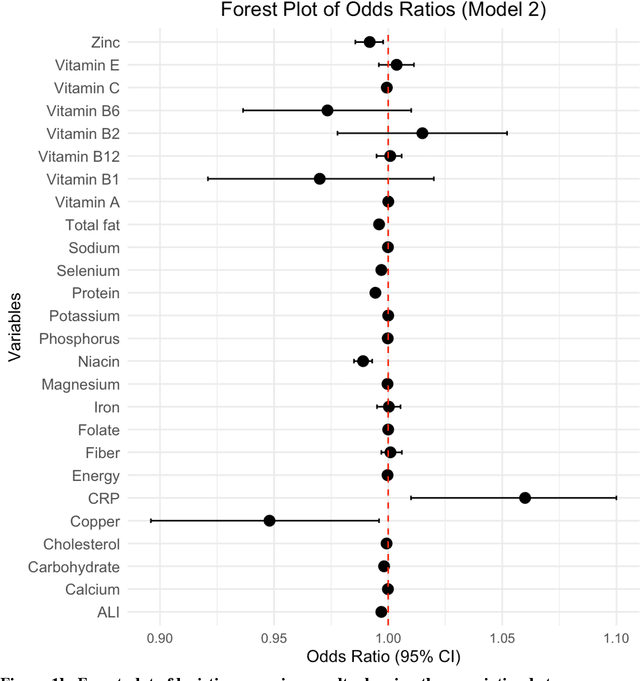

Background. Diet and inflammation are critical factors influencing cancer risk. However, the combined impact of nutritional status and inflammatory biomarkers on cancer status and type, using machine learning (ML), remains underexplored. Objectives. This study investigates the association between nutritional factors, inflammatory biomarkers, and cancer status, and whether these relationships differ across cancer types using National Health and Nutrition Examination Survey (NHANES) data. Methods. We analyzed 24 macro- and micronutrients, C-reactive protein (CRP), and the advanced lung cancer inflammation index (ALI) in 26,409 NHANES participants (2,120 with cancer). Multivariable logistic regression assessed associations with cancer prevalence. We also examined whether these features differed across the five most common cancer types. To evaluate predictive value, we applied three ML models - Logistic Regression, Random Forest, and XGBoost - on the full feature set. Results. The cohort's mean age was 49.1 years; 34.7% were obese. Comorbidities such as anemia and liver conditions, along with nutritional factors like protein and several vitamins, were key predictors of cancer status. Among the models, Random Forest performed best, achieving an accuracy of 0.72. Conclusions. Higher-quality nutritional intake and lower levels of inflammation may offer protective effects against cancer. These findings highlight the potential of combining nutritional and inflammatory markers with ML to inform cancer prevention strategies.
LLMInit: A Free Lunch from Large Language Models for Selective Initialization of Recommendation
Mar 03, 2025Collaborative filtering models, particularly graph-based approaches, have demonstrated strong performance in capturing user-item interactions for recommendation systems. However, they continue to struggle in cold-start and data-sparse scenarios. The emergence of large language models (LLMs) like GPT and LLaMA presents new possibilities for enhancing recommendation performance, especially in cold-start settings. Despite their promise, LLMs pose challenges related to scalability and efficiency due to their high computational demands and limited ability to model complex user-item relationships effectively. In this work, we introduce a novel perspective on leveraging LLMs for CF model initialization. Through experiments, we uncover an embedding collapse issue when scaling CF models to larger embedding dimensions. To effectively harness large-scale LLM embeddings, we propose innovative selective initialization strategies utilizing random, uniform, and variance-based index sampling. Our comprehensive evaluation on multiple real-world datasets demonstrates significant performance gains across various CF models while maintaining a lower computational cost compared to existing LLM-based recommendation approaches.
Affine Frequency Division Multiplexing: Extending OFDM for Scenario-Flexibility and Resilience
Feb 07, 2025



Next-generation wireless networks are conceived to provide reliable and high-data-rate communication services for diverse scenarios, such as vehicle-to-vehicle, unmanned aerial vehicles, and satellite networks. The severe Doppler spreads in the underlying time-varying channels induce destructive inter-carrier interference (ICI) in the extensively adopted orthogonal frequency division multiplexing (OFDM) waveform, leading to severe performance degradation. This calls for a new air interface design that can accommodate the severe delay-Doppler spreads in highly dynamic channels while possessing sufficient flexibility to cater to various applications. This article provides a comprehensive overview of a promising chirp-based waveform named affine frequency division multiplexing (AFDM). It is featured with two tunable parameters and achieves optimal diversity order in doubly dispersive channels (DDC). We study the fundamental principle of AFDM, illustrating its intrinsic suitability for DDC. Based on that, several potential applications of AFDM are explored. Furthermore, the major challenges and the corresponding solutions of AFDM are presented, followed by several future research directions. Finally, we draw some instructive conclusions about AFDM, hoping to provide useful inspiration for its development.
Graph-Sequential Alignment and Uniformity: Toward Enhanced Recommendation Systems
Dec 05, 2024



Graph-based and sequential methods are two popular recommendation paradigms, each excelling in its domain but lacking the ability to leverage signals from the other. To address this, we propose a novel method that integrates both approaches for enhanced performance. Our framework uses Graph Neural Network (GNN)-based and sequential recommenders as separate submodules while sharing a unified embedding space optimized jointly. To enable positive knowledge transfer, we design a loss function that enforces alignment and uniformity both within and across submodules. Experiments on three real-world datasets demonstrate that the proposed method significantly outperforms using either approach alone and achieves state-of-the-art results. Our implementations are publicly available at https://github.com/YuweiCao-UIC/GSAU.git.