 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIPI 2024 Challenge on Demosaic for HybridEVS Camera: Methods and Results
May 08, 2024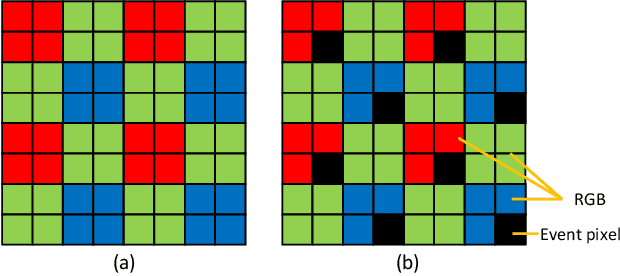
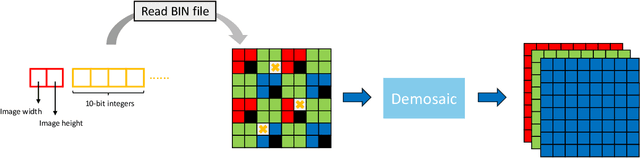

The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.
Real-Time 4K Super-Resolution of Compressed AVIF Images. AIS 2024 Challenge Survey
Apr 25, 2024
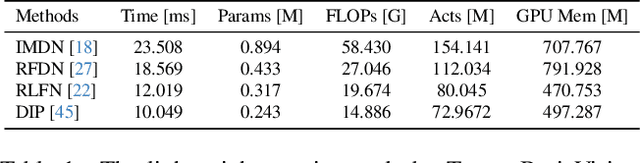
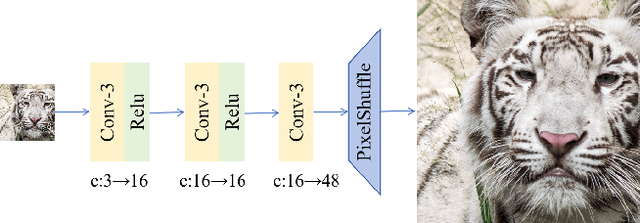
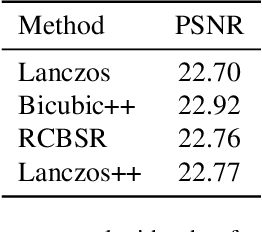
This paper introduces a novel benchmark as part of the AIS 2024 Real-Time Image Super-Resolution (RTSR) Challenge, which aims to upscale compressed images from 540p to 4K resolution (4x factor) in real-time on commercial GPUs. For this, we use a diverse test set containing a variety of 4K images ranging from digital art to gaming and photography. The images are compressed using the modern AVIF codec, instead of JPEG. All the proposed methods improve PSNR fidelity over Lanczos interpolation, and process images under 10ms. Out of the 160 participants, 25 teams submitted their code and models. The solutions present novel designs tailored for memory-efficiency and runtime on edge devices. This survey describes the best solutions for real-time SR of compressed high-resolution images.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024



This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
CMP: Cooperative Motion Prediction with Multi-Agent Communication
Mar 26, 2024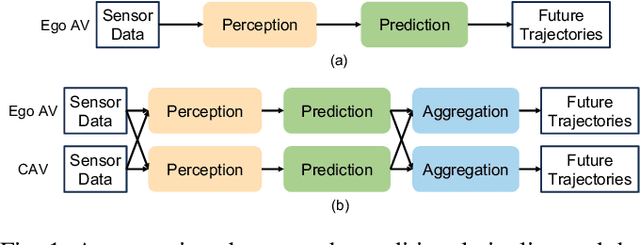
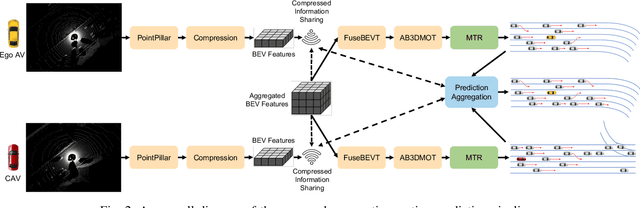
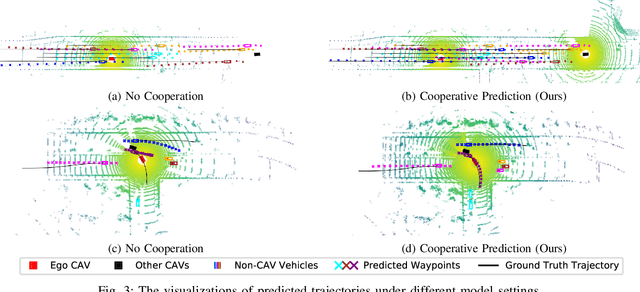
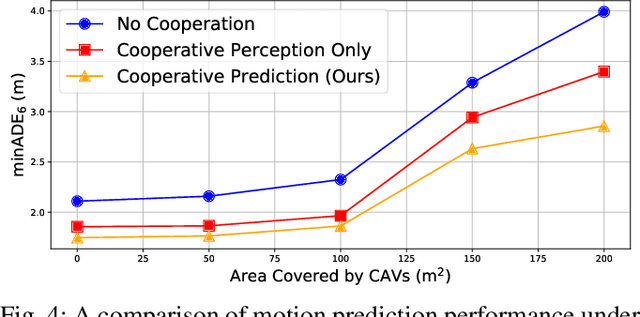
The confluence of the advancement of Autonomous Vehicles (AVs) and the maturity of Vehicle-to-Everything (V2X) communication has enabled the capability of cooperative connected and automated vehicles (CAVs). Building on top of cooperative perception, this paper explores the feasibility and effectiveness of cooperative motion prediction. Our method, CMP, takes LiDAR signals as input to enhance tracking and prediction capabilities. Unlike previous work that focuses separately on either cooperative perception or motion prediction, our framework, to the best of our knowledge, is the first to address the unified problem where CAVs share information in both perception and prediction modules. Incorporated into our design is the unique capability to tolerate realistic V2X bandwidth limitations and transmission delays, while dealing with bulky perception representations. We also propose a prediction aggregation module, which unifies the predictions obtained by different CAVs and generates the final prediction. Through extensive experiments and ablation studies, we demonstrate the effectiveness of our method in cooperative perception, tracking, and motion prediction tasks. In particular, CMP reduces the average prediction error by 17.2\% with fewer missing detections compared with the no cooperation setting. Our work marks a significant step forward in the cooperative capabilities of CAVs, showcasing enhanced performance in complex scenarios.
CSI: Enhancing the Robustness of 3D Point Cloud Recognition against Corruption
Oct 05, 2023



Despite recent advancements in deep neural networks for point cloud recognition, real-world safety-critical applications present challenges due to unavoidable data corruption. Current models often fall short in generalizing to unforeseen distribution shifts. In this study, we harness the inherent set property of point cloud data to introduce a novel critical subset identification (CSI) method, aiming to bolster recognition robustness in the face of data corruption. Our CSI framework integrates two pivotal components: density-aware sampling (DAS) and self-entropy minimization (SEM), which cater to static and dynamic CSI, respectively. DAS ensures efficient robust anchor point sampling by factoring in local density, while SEM is employed during training to accentuate the most salient point-to-point attention. Evaluations reveal that our CSI approach yields error rates of 18.4\% and 16.3\% on ModelNet40-C and PointCloud-C, respectively, marking a notable improvement over state-of-the-art methods by margins of 5.2\% and 4.2\% on the respective benchmarks. Code is available at \href{https://github.com/masterwu2115/CSI/tree/main}{https://github.com/masterwu2115/CSI/tree/main}
A Question-Answering Approach to Key Value Pair Extraction from Form-like Document Images
Apr 17, 2023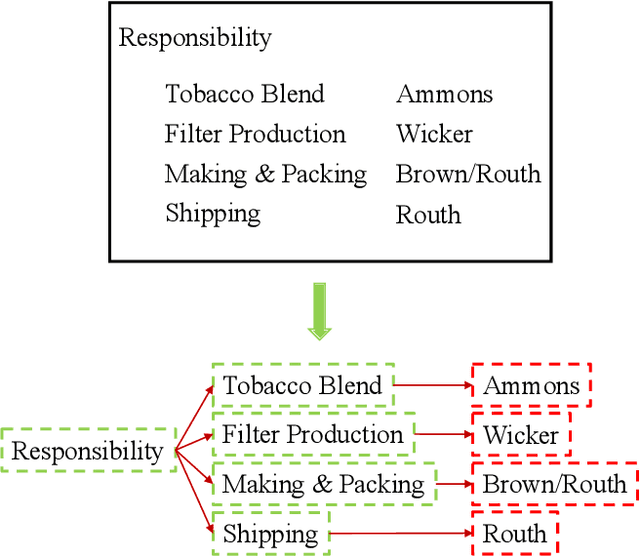
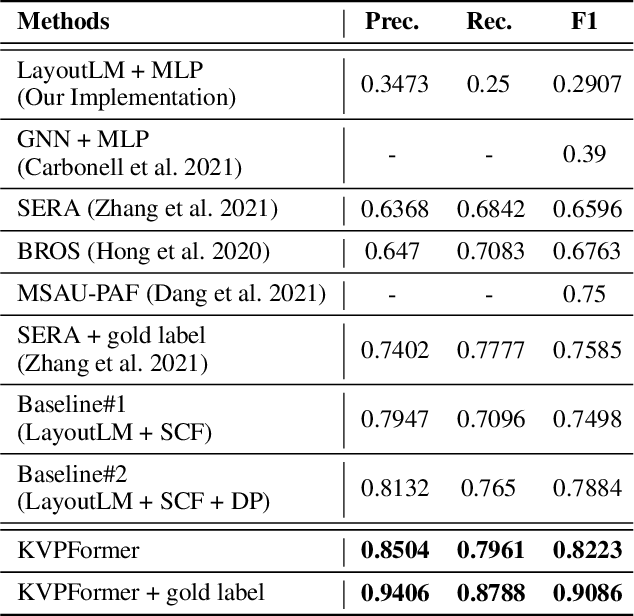
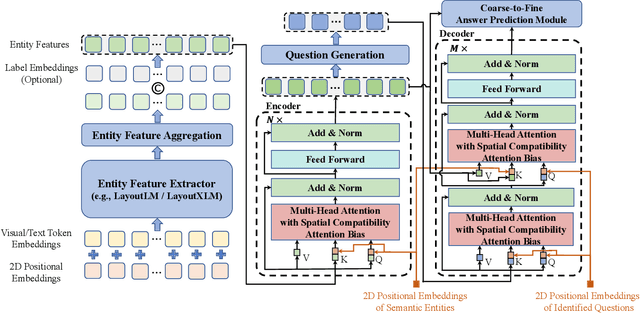
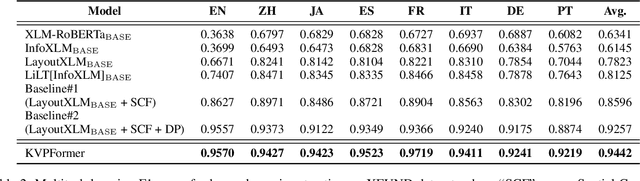
In this paper, we present a new question-answering (QA) based key-value pair extraction approach, called KVPFormer, to robustly extracting key-value relationships between entities from form-like document images. Specifically, KVPFormer first identifies key entities from all entities in an image with a Transformer encoder, then takes these key entities as \textbf{questions} and feeds them into a Transformer decoder to predict their corresponding \textbf{answers} (i.e., value entities) in parallel. To achieve higher answer prediction accuracy, we propose a coarse-to-fine answer prediction approach further, which first extracts multiple answer candidates for each identified question in the coarse stage and then selects the most likely one among these candidates in the fine stage. In this way, the learning difficulty of answer prediction can be effectively reduced so that the prediction accuracy can be improved. Moreover, we introduce a spatial compatibility attention bias into the self-attention/cross-attention mechanism for \Ours{} to better model the spatial interactions between entities. With these new techniques, our proposed \Ours{} achieves state-of-the-art results on FUNSD and XFUND datasets, outperforming the previous best-performing method by 7.2\% and 13.2\% in F1 score, respectively.
Dynamic Attentive Graph Learning for Image Restoration
Sep 14, 2021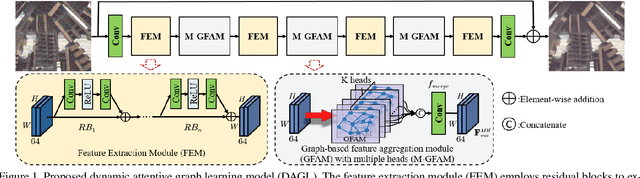



Non-local self-similarity in natural images has been verified to be an effective prior for image restoration. However, most existing deep non-local methods assign a fixed number of neighbors for each query item, neglecting the dynamics of non-local correlations. Moreover, the non-local correlations are usually based on pixels, prone to be biased due to image degradation. To rectify these weaknesses, in this paper, we propose a dynamic attentive graph learning model (DAGL) to explore the dynamic non-local property on patch level for image restoration. Specifically, we propose an improved graph model to perform patch-wise graph convolution with a dynamic and adaptive number of neighbors for each node. In this way, image content can adaptively balance over-smooth and over-sharp artifacts through the number of its connected neighbors, and the patch-wise non-local correlations can enhance the message passing process. Experimental results on various image restoration tasks: synthetic image denoising, real image denoising, image demosaicing, and compression artifact reduction show that our DAGL can produce state-of-the-art results with superior accuracy and visual quality. The source code is available at https://github.com/jianzhangcs/DAGL.
Dense Deep Unfolding Network with 3D-CNN Prior for Snapshot Compressive Imaging
Sep 14, 2021

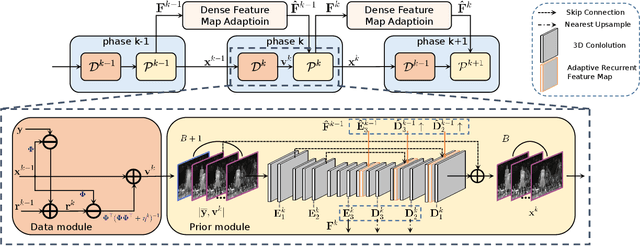

Snapshot compressive imaging (SCI) aims to record three-dimensional signals via a two-dimensional camera. For the sake of building a fast and accurate SCI recovery algorithm, we incorporate the interpretability of model-based methods and the speed of learning-based ones and present a novel dense deep unfolding network (DUN) with 3D-CNN prior for SCI, where each phase is unrolled from an iteration of Half-Quadratic Splitting (HQS). To better exploit the spatial-temporal correlation among frames and address the problem of information loss between adjacent phases in existing DUNs, we propose to adopt the 3D-CNN prior in our proximal mapping module and develop a novel dense feature map (DFM) strategy, respectively. Besides, in order to promote network robustness, we further propose a dense feature map adaption (DFMA) module to allow inter-phase information to fuse adaptively. All the parameters are learned in an end-to-end fashion. Extensive experiments on simulation data and real data verify the superiority of our method. The source code is available at https://github.com/jianzhangcs/SCI3D.
Cross-ethnicity Face Anti-spoofing Recognition Challenge: A Review
Apr 23, 2020

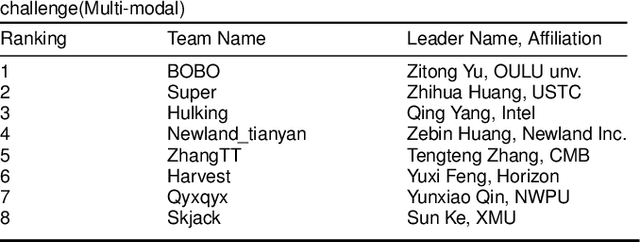
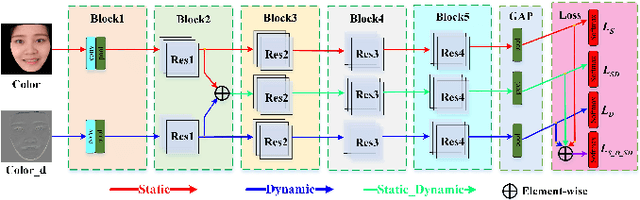
Face anti-spoofing is critical to prevent face recognition systems from a security breach. The biometrics community has %possessed achieved impressive progress recently due the excellent performance of deep neural networks and the availability of large datasets. Although ethnic bias has been verified to severely affect the performance of face recognition systems, it still remains an open research problem in face anti-spoofing. Recently, a multi-ethnic face anti-spoofing dataset, CASIA-SURF CeFA, has been released with the goal of measuring the ethnic bias. It is the largest up to date cross-ethnicity face anti-spoofing dataset covering $3$ ethnicities, $3$ modalities, $1,607$ subjects, 2D plus 3D attack types, and the first dataset including explicit ethnic labels among the recently released datasets for face anti-spoofing. We organized the Chalearn Face Anti-spoofing Attack Detection Challenge which consists of single-modal (e.g., RGB) and multi-modal (e.g., RGB, Depth, Infrared (IR)) tracks around this novel resource to boost research aiming to alleviate the ethnic bias. Both tracks have attracted $340$ teams in the development stage, and finally 11 and 8 teams have submitted their codes in the single-modal and multi-modal face anti-spoofing recognition challenges, respectively. All the results were verified and re-ran by the organizing team, and the results were used for the final ranking. This paper presents an overview of the challenge, including its design, evaluation protocol and a summary of results. We analyze the top ranked solutions and draw conclusions derived from the competition. In addition we outline future work directions.