 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealClawBench: Live OpenClaw Benchmarks from Real Developer-Agent Sessions
Jun 02, 2026Agent benchmarks should reflect what users actually ask deployed agents to do, yet existing benchmarks often miss key realism properties of real developer-agent sessions. We introduce RealClawBench, a live benchmark framework built from real OpenClaw sessions to capture the distribution, diversity, and real-world difficulty of deployed agent use. Real user requests are challenging to benchmark because they often depend on local execution environments, involve implicit or underspecified intent, and require nontrivial verification. RealClawBench addresses these challenges with two core mechanisms: reconstructed execution environments and deterministic verifiable scorers, which together convert real sessions into reproducible, automatically scored tasks. The resulting release contains 281 executable tasks sampled from a much larger real-session pool while preserving the source distribution, with maximum final-vs-source Jensen-Shannon divergence of 0.0448. Evaluating 14 contemporary models shows that the best system solves only 65.8% of tasks, revealing substantial headroom on realistic developer-agent workloads. By turning real deployed sessions into controlled evaluation instances, RealClawBench provides a practical path toward benchmarks that better measure agent capability in actual use. Code is available at:https://anonymous.4open.science/r/real-claw-bench-582B.
Beyond Parameter Arithmetic: Sparse Complementary Fusion for Distribution-Aware Model Merging
Feb 12, 2026Model merging has emerged as a promising paradigm for composing the capabilities of large language models by directly operating in weight space, enabling the integration of specialized models without costly retraining. However, existing merging methods largely rely on parameter-space heuristics, which often introduce severe interference, leading to degraded generalization and unstable generation behaviors such as repetition and incoherent outputs. In this work, we propose Sparse Complementary Fusion with reverse KL (SCF-RKL), a novel model merging framework that explicitly controls functional interference through sparse, distribution-aware updates. Instead of assuming linear additivity in parameter space, SCF-RKL measures the functional divergence between models using reverse Kullback-Leibler divergence and selectively incorporates complementary parameters. This mode-seeking, sparsity-inducing design effectively preserves stable representations while integrating new capabilities. We evaluate SCF-RKL across a wide range of model scales and architectures, covering both reasoning-focused and instruction-tuned models. Extensive experiments on 24 benchmarks spanning advanced reasoning, general reasoning and knowledge, instruction following, and safety demonstrate, vision classification that SCF-RKL consistently outperforms existing model merging methods while maintaining strong generalization and generation stability.
Beyond Static Alignment: Hierarchical Policy Control for LLM Safety via Risk-Aware Chain-of-Thought
Feb 06, 2026Large Language Models (LLMs) face a fundamental safety-helpfulness trade-off due to static, one-size-fits-all safety policies that lack runtime controllabilityxf, making it difficult to tailor responses to diverse application needs. %As a result, models may over-refuse benign requests or under-constrain harmful ones. We present \textbf{PACT} (Prompt-configured Action via Chain-of-Thought), a framework for dynamic safety control through explicit, risk-aware reasoning. PACT operates under a hierarchical policy architecture: a non-overridable global safety policy establishes immutable boundaries for critical risks (e.g., child safety, violent extremism), while user-defined policies can introduce domain-specific (non-global) risk categories and specify label-to-action behaviors to improve utility in real-world deployment settings. The framework decomposes safety decisions into structured Classify$\rightarrow$Act paths that route queries to the appropriate action (comply, guide, or reject) and render the decision-making process transparent. Extensive experiments demonstrate that PACT achieves near state-of-the-art safety performance under global policy evaluation while attaining the best controllability under user-specific policy evaluation, effectively mitigating the safety-helpfulness trade-off. We will release the PACT model suite, training data, and evaluation protocols to facilitate reproducible research in controllable safety alignment.
DiaDem: Advancing Dialogue Descriptions in Audiovisual Video Captioning for Multimodal Large Language Models
Jan 27, 2026Accurate dialogue description in audiovisual video captioning is crucial for downstream understanding and generation tasks. However, existing models generally struggle to produce faithful dialogue descriptions within audiovisual captions. To mitigate this limitation, we propose DiaDem, a powerful audiovisual video captioning model capable of generating captions with more precise dialogue descriptions while maintaining strong overall performance. We first synthesize a high-quality dataset for SFT, then employ a difficulty-partitioned two-stage GRPO strategy to further enhance dialogue descriptions. To enable systematic evaluation of dialogue description capabilities, we introduce DiaDemBench, a comprehensive benchmark designed to evaluate models across diverse dialogue scenarios, emphasizing both speaker attribution accuracy and utterance transcription fidelity in audiovisual captions. Extensive experiments on DiaDemBench reveal even commercial models still exhibit substantial room for improvement in dialogue-aware captioning. Notably, DiaDem not only outperforms the Gemini series in dialogue description accuracy but also achieves competitive performance on general audiovisual captioning benchmarks, demonstrating its overall effectiveness.
Kling-Omni Technical Report
Dec 18, 2025



We present Kling-Omni, a generalist generative framework designed to synthesize high-fidelity videos directly from multimodal visual language inputs. Adopting an end-to-end perspective, Kling-Omni bridges the functional separation among diverse video generation, editing, and intelligent reasoning tasks, integrating them into a holistic system. Unlike disjointed pipeline approaches, Kling-Omni supports a diverse range of user inputs, including text instructions, reference images, and video contexts, processing them into a unified multimodal representation to deliver cinematic-quality and highly-intelligent video content creation. To support these capabilities, we constructed a comprehensive data system that serves as the foundation for multimodal video creation. The framework is further empowered by efficient large-scale pre-training strategies and infrastructure optimizations for inference. Comprehensive evaluations reveal that Kling-Omni demonstrates exceptional capabilities in in-context generation, reasoning-based editing, and multimodal instruction following. Moving beyond a content creation tool, we believe Kling-Omni is a pivotal advancement toward multimodal world simulators capable of perceiving, reasoning, generating and interacting with the dynamic and complex worlds.
Evaluation is All You Need: Strategic Overclaiming of LLM Reasoning Capabilities Through Evaluation Design
Jun 05, 2025Reasoning models represented by the Deepseek-R1-Distill series have been widely adopted by the open-source community due to their strong performance in mathematics, science, programming, and other domains. However, our study reveals that their benchmark evaluation results are subject to significant fluctuations caused by various factors. Subtle differences in evaluation conditions can lead to substantial variations in results. Similar phenomena are observed in other open-source inference models fine-tuned based on the Deepseek-R1-Distill series, as well as in the QwQ-32B model, making their claimed performance improvements difficult to reproduce reliably. Therefore, we advocate for the establishment of a more rigorous paradigm for model performance evaluation and present our empirical assessments of the Deepseek-R1-Distill series models.
Mavors: Multi-granularity Video Representation for Multimodal Large Language Model
Apr 14, 2025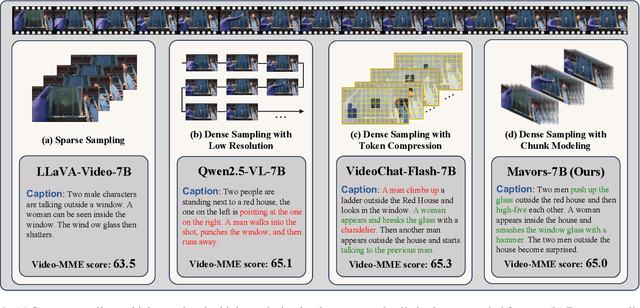
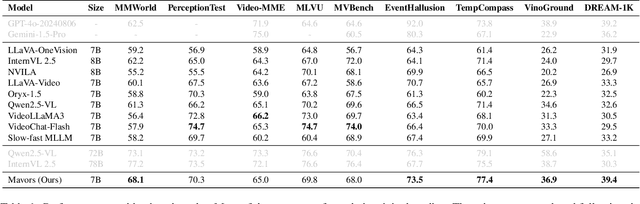
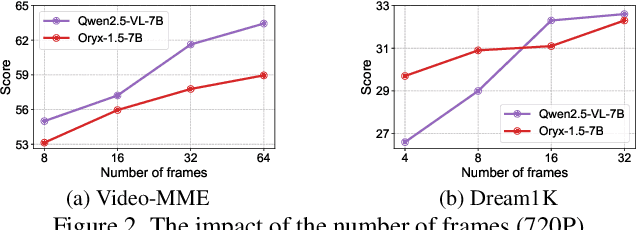
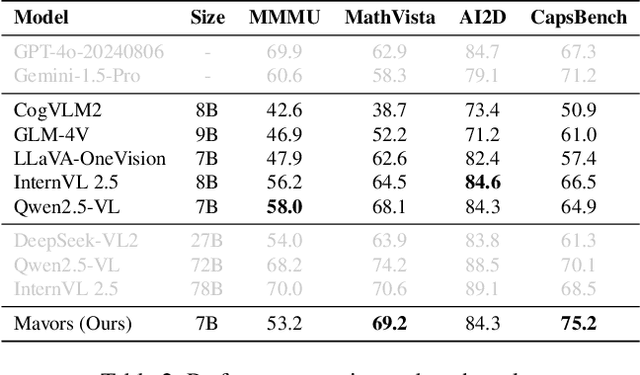
Long-context video understanding in multimodal large language models (MLLMs) faces a critical challenge: balancing computational efficiency with the retention of fine-grained spatio-temporal patterns. Existing approaches (e.g., sparse sampling, dense sampling with low resolution, and token compression) suffer from significant information loss in temporal dynamics, spatial details, or subtle interactions, particularly in videos with complex motion or varying resolutions. To address this, we propose $\mathbf{Mavors}$, a novel framework that introduces $\mathbf{M}$ulti-gr$\mathbf{a}$nularity $\mathbf{v}$ide$\mathbf{o}$ $\mathbf{r}$epre$\mathbf{s}$entation for holistic long-video modeling. Specifically, Mavors directly encodes raw video content into latent representations through two core components: 1) an Intra-chunk Vision Encoder (IVE) that preserves high-resolution spatial features via 3D convolutions and Vision Transformers, and 2) an Inter-chunk Feature Aggregator (IFA) that establishes temporal coherence across chunks using transformer-based dependency modeling with chunk-level rotary position encodings. Moreover, the framework unifies image and video understanding by treating images as single-frame videos via sub-image decomposition. Experiments across diverse benchmarks demonstrate Mavors' superiority in maintaining both spatial fidelity and temporal continuity, significantly outperforming existing methods in tasks requiring fine-grained spatio-temporal reasoning.
TinyR1-32B-Preview: Boosting Accuracy with Branch-Merge Distillation
Mar 06, 2025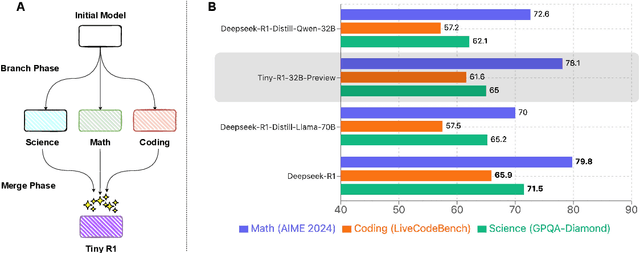
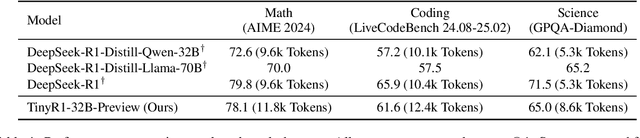
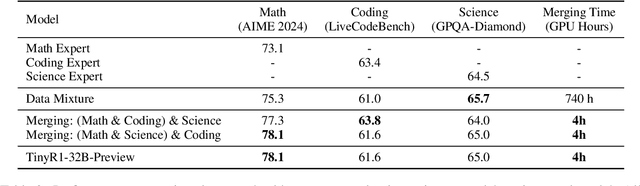
The challenge of reducing the size of Large Language Models (LLMs) while maintaining their performance has gained significant attention. However, existing methods, such as model distillation and transfer learning, often fail to achieve high accuracy. To address this limitation, we introduce the Branch-Merge distillation approach, which enhances model compression through two phases: (1) the Branch Phase, where knowledge from a large teacher model is \textit{selectively distilled} into specialized student models via domain-specific supervised fine-tuning (SFT); And (2) the Merge Phase, where these student models are merged to enable cross-domain knowledge transfer and improve generalization. We validate our distillation approach using DeepSeek-R1 as the teacher and DeepSeek-R1-Distill-Qwen-32B as the student. The resulting merged model, TinyR1-32B-Preview, outperforms its counterpart DeepSeek-R1-Distill-Qwen-32B across multiple benchmarks, including Mathematics (+5.5 points), Coding (+4.4 points) and Science (+2.9 points), while achieving near-equal performance to DeepSeek-R1 on AIME 2024. The Branch-Merge distillation approach provides a scalable solution for creating smaller, high-performing LLMs with reduced computational cost and time.
HAIC: Improving Human Action Understanding and Generation with Better Captions for Multi-modal Large Language Models
Feb 28, 2025


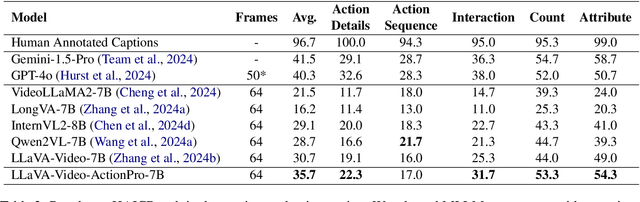
Recent Multi-modal Large Language Models (MLLMs) have made great progress in video understanding. However, their performance on videos involving human actions is still limited by the lack of high-quality data. To address this, we introduce a two-stage data annotation pipeline. First, we design strategies to accumulate videos featuring clear human actions from the Internet. Second, videos are annotated in a standardized caption format that uses human attributes to distinguish individuals and chronologically details their actions and interactions. Through this pipeline, we curate two datasets, namely HAICTrain and HAICBench. \textbf{HAICTrain} comprises 126K video-caption pairs generated by Gemini-Pro and verified for training purposes. Meanwhile, \textbf{HAICBench} includes 500 manually annotated video-caption pairs and 1,400 QA pairs, for a comprehensive evaluation of human action understanding. Experimental results demonstrate that training with HAICTrain not only significantly enhances human understanding abilities across 4 benchmarks, but can also improve text-to-video generation results. Both the HAICTrain and HAICBench are released at https://huggingface.co/datasets/KuaishouHAIC/HAIC.
UniVIE: A Unified Label Space Approach to Visual Information Extraction from Form-like Documents
Jan 17, 2024



Existing methods for Visual Information Extraction (VIE) from form-like documents typically fragment the process into separate subtasks, such as key information extraction, key-value pair extraction, and choice group extraction. However, these approaches often overlook the hierarchical structure of form documents, including hierarchical key-value pairs and hierarchical choice groups. To address these limitations, we present a new perspective, reframing VIE as a relation prediction problem and unifying labels of different tasks into a single label space. This unified approach allows for the definition of various relation types and effectively tackles hierarchical relationships in form-like documents. In line with this perspective, we present UniVIE, a unified model that addresses the VIE problem comprehensively. UniVIE functions using a coarse-to-fine strategy. It initially generates tree proposals through a tree proposal network, which are subsequently refined into hierarchical trees by a relation decoder module. To enhance the relation prediction capabilities of UniVIE, we incorporate two novel tree constraints into the relation decoder: a tree attention mask and a tree level embedding. Extensive experimental evaluations on both our in-house dataset HierForms and a publicly available dataset SIBR, substantiate that our method achieves state-of-the-art results, underscoring the effectiveness and potential of our unified approach in advancing the field of VIE.