 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniHDSA: A Unified Relation Prediction Approach for Hierarchical Document Structure Analysis
Mar 20, 2025



Document structure analysis, aka document layout analysis, is crucial for understanding both the physical layout and logical structure of documents, serving information retrieval, document summarization, knowledge extraction, etc. Hierarchical Document Structure Analysis (HDSA) specifically aims to restore the hierarchical structure of documents created using authoring software with hierarchical schemas. Previous research has primarily followed two approaches: one focuses on tackling specific subtasks of HDSA in isolation, such as table detection or reading order prediction, while the other adopts a unified framework that uses multiple branches or modules, each designed to address a distinct task. In this work, we propose a unified relation prediction approach for HDSA, called UniHDSA, which treats various HDSA sub-tasks as relation prediction problems and consolidates relation prediction labels into a unified label space. This allows a single relation prediction module to handle multiple tasks simultaneously, whether at a page-level or document-level structure analysis. To validate the effectiveness of UniHDSA, we develop a multimodal end-to-end system based on Transformer architectures. Extensive experimental results demonstrate that our approach achieves state-of-the-art performance on a hierarchical document structure analysis benchmark, Comp-HRDoc, and competitive results on a large-scale document layout analysis dataset, DocLayNet, effectively illustrating the superiority of our method across all sub-tasks.
DLAFormer: An End-to-End Transformer For Document Layout Analysis
May 20, 2024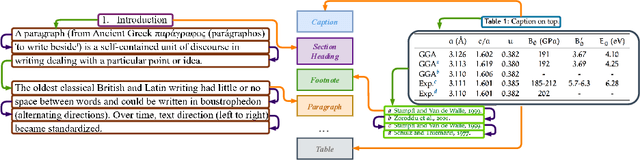
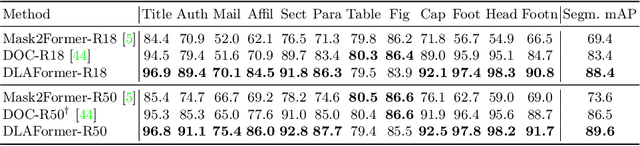
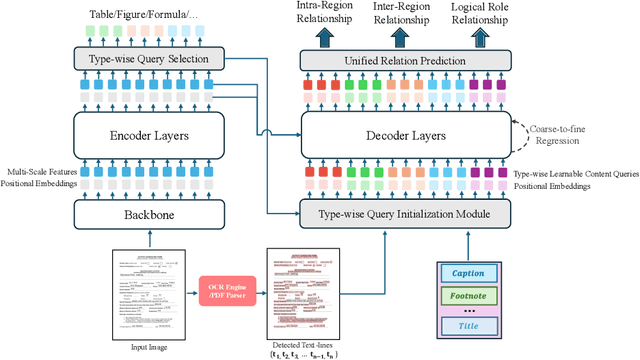

Document layout analysis (DLA) is crucial for understanding the physical layout and logical structure of documents, serving information retrieval, document summarization, knowledge extraction, etc. However, previous studies have typically used separate models to address individual sub-tasks within DLA, including table/figure detection, text region detection, logical role classification, and reading order prediction. In this work, we propose an end-to-end transformer-based approach for document layout analysis, called DLAFormer, which integrates all these sub-tasks into a single model. To achieve this, we treat various DLA sub-tasks (such as text region detection, logical role classification, and reading order prediction) as relation prediction problems and consolidate these relation prediction labels into a unified label space, allowing a unified relation prediction module to handle multiple tasks concurrently. Additionally, we introduce a novel set of type-wise queries to enhance the physical meaning of content queries in DETR. Moreover, we adopt a coarse-to-fine strategy to accurately identify graphical page objects. Experimental results demonstrate that our proposed DLAFormer outperforms previous approaches that employ multi-branch or multi-stage architectures for multiple tasks on two document layout analysis benchmarks, DocLayNet and Comp-HRDoc.
Detect-Order-Construct: A Tree Construction based Approach for Hierarchical Document Structure Analysis
Jan 22, 2024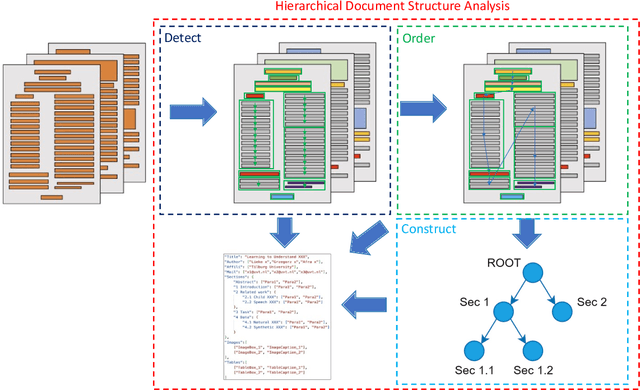
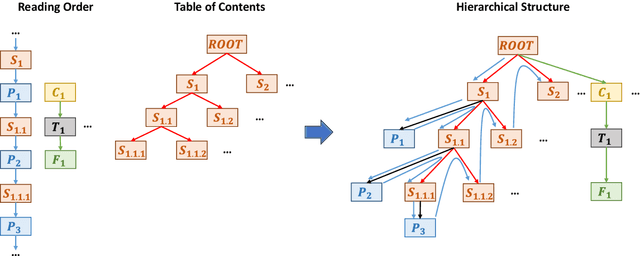
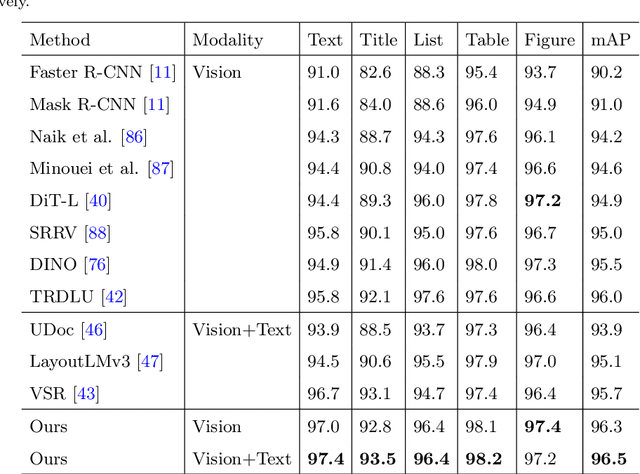
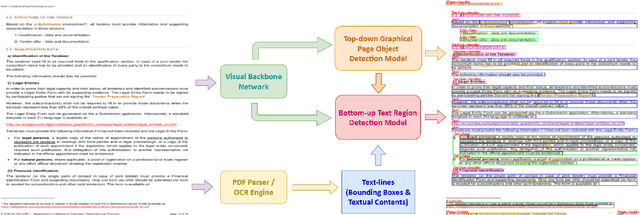
Document structure analysis (aka document layout analysis) is crucial for understanding the physical layout and logical structure of documents, with applications in information retrieval, document summarization, knowledge extraction, etc. In this paper, we concentrate on Hierarchical Document Structure Analysis (HDSA) to explore hierarchical relationships within structured documents created using authoring software employing hierarchical schemas, such as LaTeX, Microsoft Word, and HTML. To comprehensively analyze hierarchical document structures, we propose a tree construction based approach that addresses multiple subtasks concurrently, including page object detection (Detect), reading order prediction of identified objects (Order), and the construction of intended hierarchical structure (Construct). We present an effective end-to-end solution based on this framework to demonstrate its performance. To assess our approach, we develop a comprehensive benchmark called Comp-HRDoc, which evaluates the above subtasks simultaneously. Our end-to-end system achieves state-of-the-art performance on two large-scale document layout analysis datasets (PubLayNet and DocLayNet), a high-quality hierarchical document structure reconstruction dataset (HRDoc), and our Comp-HRDoc benchmark. The Comp-HRDoc benchmark will be released to facilitate further research in this field.
Dynamic Relation Transformer for Contextual Text Block Detection
Jan 17, 2024



Contextual Text Block Detection (CTBD) is the task of identifying coherent text blocks within the complexity of natural scenes. Previous methodologies have treated CTBD as either a visual relation extraction challenge within computer vision or as a sequence modeling problem from the perspective of natural language processing. We introduce a new framework that frames CTBD as a graph generation problem. This methodology consists of two essential procedures: identifying individual text units as graph nodes and discerning the sequential reading order relationships among these units as graph edges. Leveraging the cutting-edge capabilities of DQ-DETR for node detection, our framework innovates further by integrating a novel mechanism, a Dynamic Relation Transformer (DRFormer), dedicated to edge generation. DRFormer incorporates a dual interactive transformer decoder that deftly manages a dynamic graph structure refinement process. Through this iterative process, the model systematically enhances the graph's fidelity, ultimately resulting in improved precision in detecting contextual text blocks. Comprehensive experimental evaluations conducted on both SCUT-CTW-Context and ReCTS-Context datasets substantiate that our method achieves state-of-the-art results, underscoring the effectiveness and potential of our graph generation framework in advancing the field of CTBD.
UniVIE: A Unified Label Space Approach to Visual Information Extraction from Form-like Documents
Jan 17, 2024



Existing methods for Visual Information Extraction (VIE) from form-like documents typically fragment the process into separate subtasks, such as key information extraction, key-value pair extraction, and choice group extraction. However, these approaches often overlook the hierarchical structure of form documents, including hierarchical key-value pairs and hierarchical choice groups. To address these limitations, we present a new perspective, reframing VIE as a relation prediction problem and unifying labels of different tasks into a single label space. This unified approach allows for the definition of various relation types and effectively tackles hierarchical relationships in form-like documents. In line with this perspective, we present UniVIE, a unified model that addresses the VIE problem comprehensively. UniVIE functions using a coarse-to-fine strategy. It initially generates tree proposals through a tree proposal network, which are subsequently refined into hierarchical trees by a relation decoder module. To enhance the relation prediction capabilities of UniVIE, we incorporate two novel tree constraints into the relation decoder: a tree attention mask and a tree level embedding. Extensive experimental evaluations on both our in-house dataset HierForms and a publicly available dataset SIBR, substantiate that our method achieves state-of-the-art results, underscoring the effectiveness and potential of our unified approach in advancing the field of VIE.
Improving Handwritten OCR with Training Samples Generated by Glyph Conditional Denoising Diffusion Probabilistic Model
May 31, 2023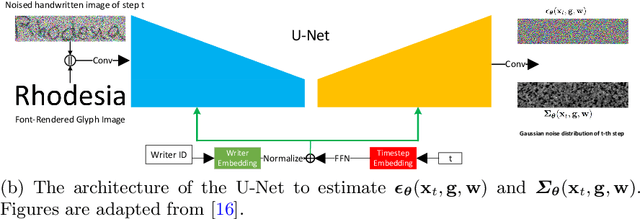
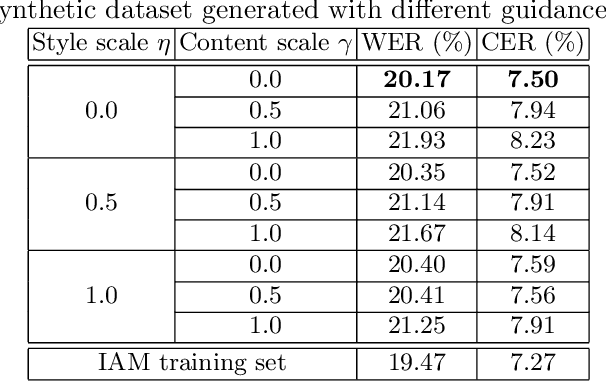

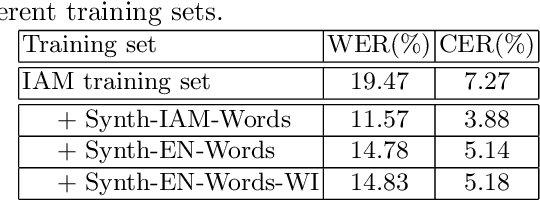
Constructing a highly accurate handwritten OCR system requires large amounts of representative training data, which is both time-consuming and expensive to collect. To mitigate the issue, we propose a denoising diffusion probabilistic model (DDPM) to generate training samples. This model conditions on a printed glyph image and creates mappings between printed characters and handwritten images, thus enabling the generation of photo-realistic handwritten samples with diverse styles and unseen text contents. However, the text contents in synthetic images are not always consistent with the glyph conditional images, leading to unreliable labels of synthetic samples. To address this issue, we further propose a progressive data filtering strategy to add those samples with a high confidence of correctness to the training set. Experimental results on IAM benchmark task show that OCR model trained with augmented DDPM-synthesized training samples can achieve about 45% relative word error rate reduction compared with the one trained on real data only.
Zero-shot Generation of Training Data with Denoising Diffusion Probabilistic Model for Handwritten Chinese Character Recognition
May 25, 2023



There are more than 80,000 character categories in Chinese while most of them are rarely used. To build a high performance handwritten Chinese character recognition (HCCR) system supporting the full character set with a traditional approach, many training samples need be collected for each character category, which is both time-consuming and expensive. In this paper, we propose a novel approach to transforming Chinese character glyph images generated from font libraries to handwritten ones with a denoising diffusion probabilistic model (DDPM). Training from handwritten samples of a small character set, the DDPM is capable of mapping printed strokes to handwritten ones, which makes it possible to generate photo-realistic and diverse style handwritten samples of unseen character categories. Combining DDPM-synthesized samples of unseen categories with real samples of other categories, we can build an HCCR system to support the full character set. Experimental results on CASIA-HWDB dataset with 3,755 character categories show that the HCCR systems trained with synthetic samples perform similarly with the one trained with real samples in terms of recognition accuracy. The proposed method has the potential to address HCCR with a larger vocabulary.
A Question-Answering Approach to Key Value Pair Extraction from Form-like Document Images
Apr 17, 2023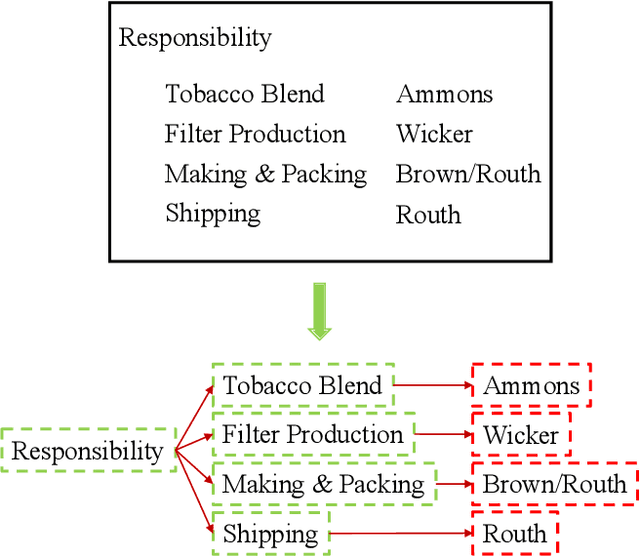
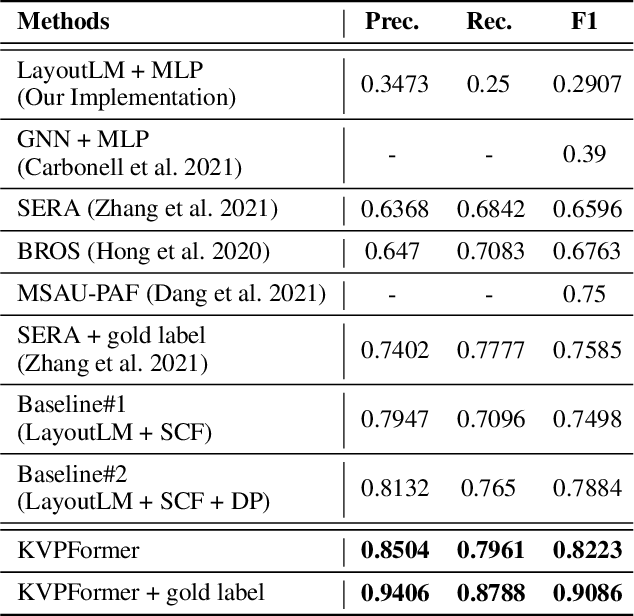
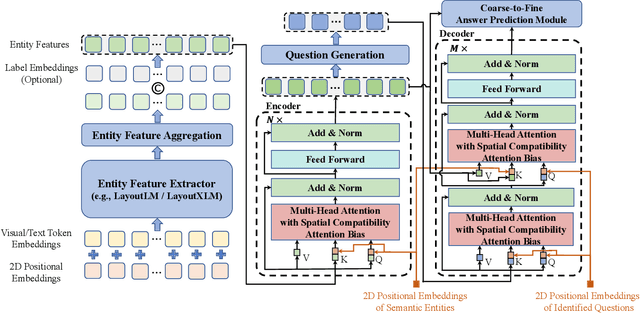
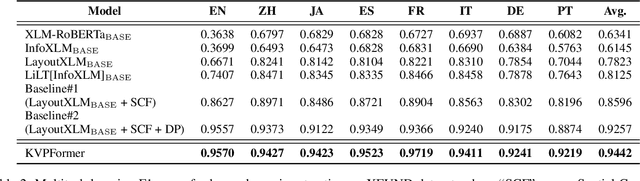
In this paper, we present a new question-answering (QA) based key-value pair extraction approach, called KVPFormer, to robustly extracting key-value relationships between entities from form-like document images. Specifically, KVPFormer first identifies key entities from all entities in an image with a Transformer encoder, then takes these key entities as \textbf{questions} and feeds them into a Transformer decoder to predict their corresponding \textbf{answers} (i.e., value entities) in parallel. To achieve higher answer prediction accuracy, we propose a coarse-to-fine answer prediction approach further, which first extracts multiple answer candidates for each identified question in the coarse stage and then selects the most likely one among these candidates in the fine stage. In this way, the learning difficulty of answer prediction can be effectively reduced so that the prediction accuracy can be improved. Moreover, we introduce a spatial compatibility attention bias into the self-attention/cross-attention mechanism for \Ours{} to better model the spatial interactions between entities. With these new techniques, our proposed \Ours{} achieves state-of-the-art results on FUNSD and XFUND datasets, outperforming the previous best-performing method by 7.2\% and 13.2\% in F1 score, respectively.
Robust Table Structure Recognition with Dynamic Queries Enhanced Detection Transformer
Mar 21, 2023



We present a new table structure recognition (TSR) approach, called TSRFormer, to robustly recognizing the structures of complex tables with geometrical distortions from various table images. Unlike previous methods, we formulate table separation line prediction as a line regression problem instead of an image segmentation problem and propose a new two-stage dynamic queries enhanced DETR based separation line regression approach, named DQ-DETR, to predict separation lines from table images directly. Compared to Vallina DETR, we propose three improvements in DQ-DETR to make the two-stage DETR framework work efficiently and effectively for the separation line prediction task: 1) A new query design, named Dynamic Query, to decouple single line query into separable point queries which could intuitively improve the localization accuracy for regression tasks; 2) A dynamic queries based progressive line regression approach to progressively regressing points on the line which further enhances localization accuracy for distorted tables; 3) A prior-enhanced matching strategy to solve the slow convergence issue of DETR. After separation line prediction, a simple relation network based cell merging module is used to recover spanning cells. With these new techniques, our TSRFormer achieves state-of-the-art performance on several benchmark datasets, including SciTSR, PubTabNet, WTW and FinTabNet. Furthermore, we have validated the robustness and high localization accuracy of our approach to tables with complex structures, borderless cells, large blank spaces, empty or spanning cells as well as distorted or even curved shapes on a more challenging real-world in-house dataset.
TSRFormer: Table Structure Recognition with Transformers
Aug 09, 2022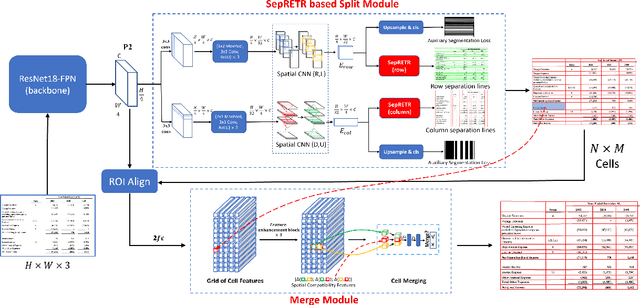
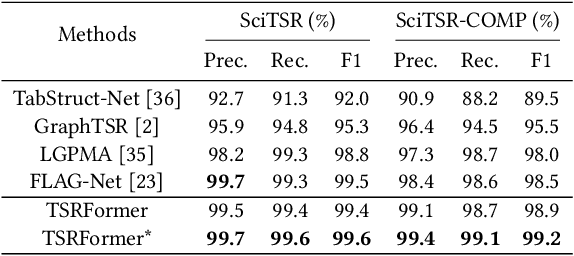
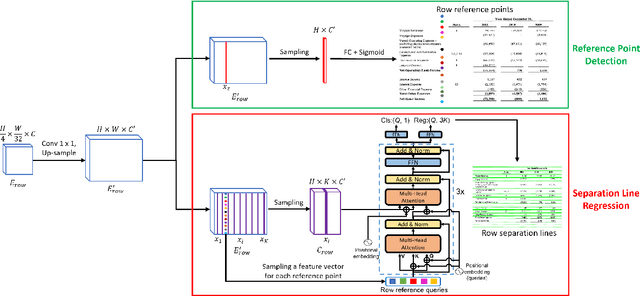
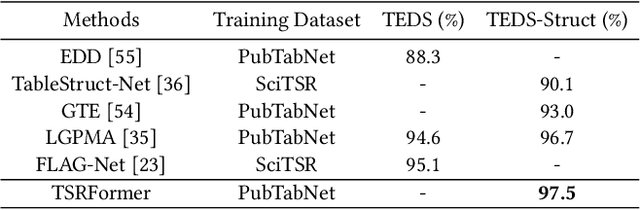
We present a new table structure recognition (TSR) approach, called TSRFormer, to robustly recognizing the structures of complex tables with geometrical distortions from various table images. Unlike previous methods, we formulate table separation line prediction as a line regression problem instead of an image segmentation problem and propose a new two-stage DETR based separator prediction approach, dubbed \textbf{Sep}arator \textbf{RE}gression \textbf{TR}ansformer (SepRETR), to predict separation lines from table images directly. To make the two-stage DETR framework work efficiently and effectively for the separation line prediction task, we propose two improvements: 1) A prior-enhanced matching strategy to solve the slow convergence issue of DETR; 2) A new cross attention module to sample features from a high-resolution convolutional feature map directly so that high localization accuracy is achieved with low computational cost. After separation line prediction, a simple relation network based cell merging module is used to recover spanning cells. With these new techniques, our TSRFormer achieves state-of-the-art performance on several benchmark datasets, including SciTSR, PubTabNet and WTW. Furthermore, we have validated the robustness of our approach to tables with complex structures, borderless cells, large blank spaces, empty or spanning cells as well as distorted or even curved shapes on a more challenging real-world in-house dataset.