 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetect-Order-Construct: A Tree Construction based Approach for Hierarchical Document Structure Analysis
Jan 22, 2024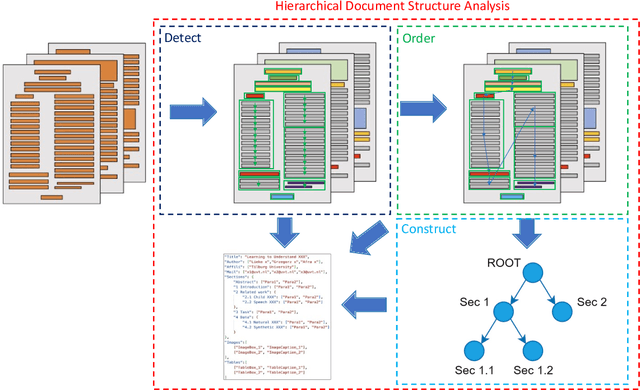
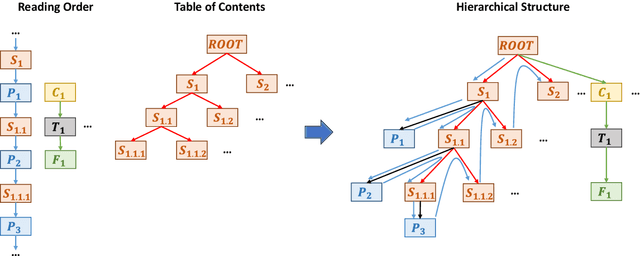
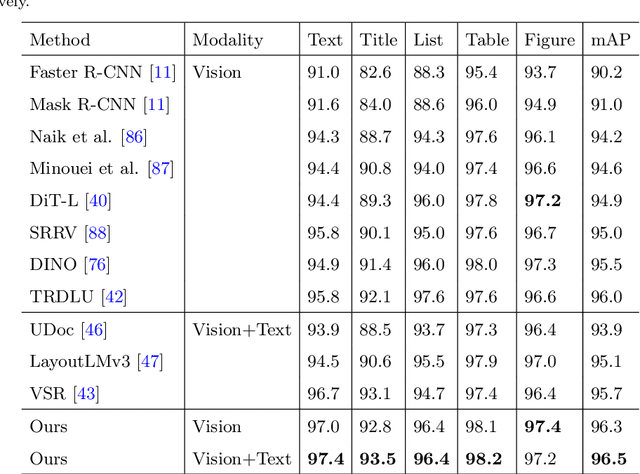
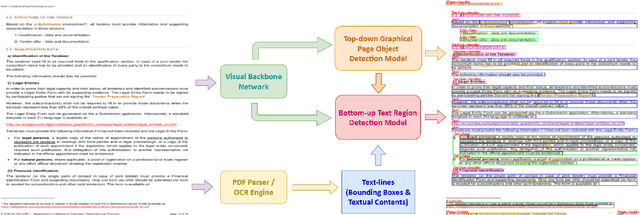
Document structure analysis (aka document layout analysis) is crucial for understanding the physical layout and logical structure of documents, with applications in information retrieval, document summarization, knowledge extraction, etc. In this paper, we concentrate on Hierarchical Document Structure Analysis (HDSA) to explore hierarchical relationships within structured documents created using authoring software employing hierarchical schemas, such as LaTeX, Microsoft Word, and HTML. To comprehensively analyze hierarchical document structures, we propose a tree construction based approach that addresses multiple subtasks concurrently, including page object detection (Detect), reading order prediction of identified objects (Order), and the construction of intended hierarchical structure (Construct). We present an effective end-to-end solution based on this framework to demonstrate its performance. To assess our approach, we develop a comprehensive benchmark called Comp-HRDoc, which evaluates the above subtasks simultaneously. Our end-to-end system achieves state-of-the-art performance on two large-scale document layout analysis datasets (PubLayNet and DocLayNet), a high-quality hierarchical document structure reconstruction dataset (HRDoc), and our Comp-HRDoc benchmark. The Comp-HRDoc benchmark will be released to facilitate further research in this field.
UniVIE: A Unified Label Space Approach to Visual Information Extraction from Form-like Documents
Jan 17, 2024



Existing methods for Visual Information Extraction (VIE) from form-like documents typically fragment the process into separate subtasks, such as key information extraction, key-value pair extraction, and choice group extraction. However, these approaches often overlook the hierarchical structure of form documents, including hierarchical key-value pairs and hierarchical choice groups. To address these limitations, we present a new perspective, reframing VIE as a relation prediction problem and unifying labels of different tasks into a single label space. This unified approach allows for the definition of various relation types and effectively tackles hierarchical relationships in form-like documents. In line with this perspective, we present UniVIE, a unified model that addresses the VIE problem comprehensively. UniVIE functions using a coarse-to-fine strategy. It initially generates tree proposals through a tree proposal network, which are subsequently refined into hierarchical trees by a relation decoder module. To enhance the relation prediction capabilities of UniVIE, we incorporate two novel tree constraints into the relation decoder: a tree attention mask and a tree level embedding. Extensive experimental evaluations on both our in-house dataset HierForms and a publicly available dataset SIBR, substantiate that our method achieves state-of-the-art results, underscoring the effectiveness and potential of our unified approach in advancing the field of VIE.
Dynamic Relation Transformer for Contextual Text Block Detection
Jan 17, 2024



Contextual Text Block Detection (CTBD) is the task of identifying coherent text blocks within the complexity of natural scenes. Previous methodologies have treated CTBD as either a visual relation extraction challenge within computer vision or as a sequence modeling problem from the perspective of natural language processing. We introduce a new framework that frames CTBD as a graph generation problem. This methodology consists of two essential procedures: identifying individual text units as graph nodes and discerning the sequential reading order relationships among these units as graph edges. Leveraging the cutting-edge capabilities of DQ-DETR for node detection, our framework innovates further by integrating a novel mechanism, a Dynamic Relation Transformer (DRFormer), dedicated to edge generation. DRFormer incorporates a dual interactive transformer decoder that deftly manages a dynamic graph structure refinement process. Through this iterative process, the model systematically enhances the graph's fidelity, ultimately resulting in improved precision in detecting contextual text blocks. Comprehensive experimental evaluations conducted on both SCUT-CTW-Context and ReCTS-Context datasets substantiate that our method achieves state-of-the-art results, underscoring the effectiveness and potential of our graph generation framework in advancing the field of CTBD.
Exploring Predicate Visual Context in Detecting of Human-Object Interactions
Aug 11, 2023Recently, the DETR framework has emerged as the dominant approach for human--object interaction (HOI) research. In particular, two-stage transformer-based HOI detectors are amongst the most performant and training-efficient approaches. However, these often condition HOI classification on object features that lack fine-grained contextual information, eschewing pose and orientation information in favour of visual cues about object identity and box extremities. This naturally hinders the recognition of complex or ambiguous interactions. In this work, we study these issues through visualisations and carefully designed experiments. Accordingly, we investigate how best to re-introduce image features via cross-attention. With an improved query design, extensive exploration of keys and values, and box pair positional embeddings as spatial guidance, our model with enhanced predicate visual context (PViC) outperforms state-of-the-art methods on the HICO-DET and V-COCO benchmarks, while maintaining low training cost.
A Question-Answering Approach to Key Value Pair Extraction from Form-like Document Images
Apr 17, 2023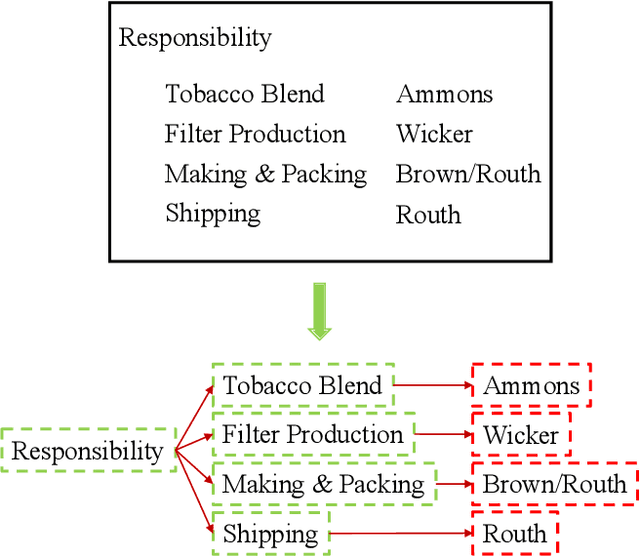
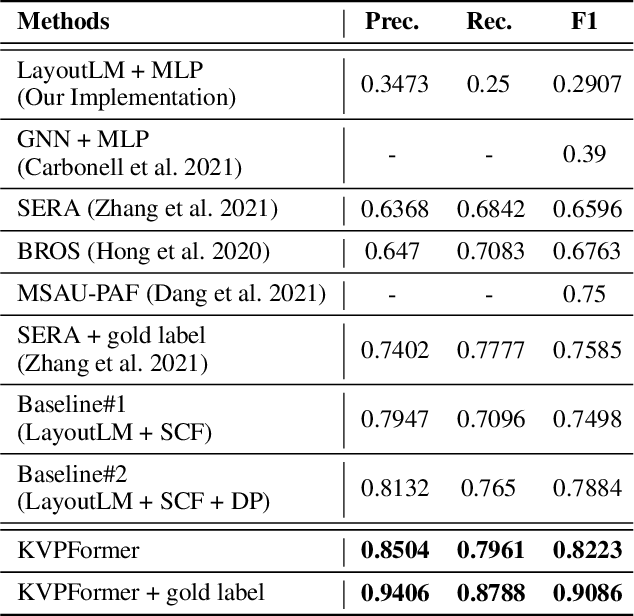
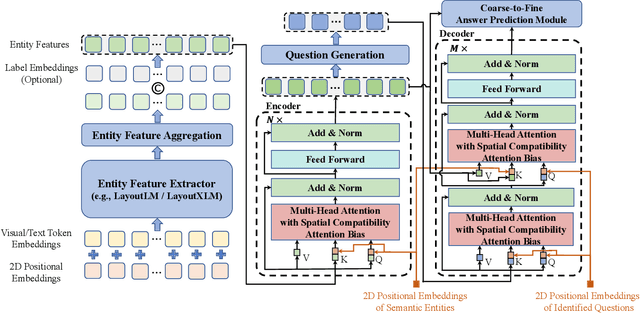
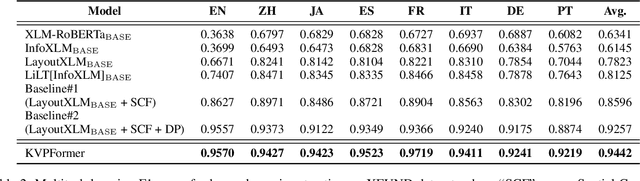
In this paper, we present a new question-answering (QA) based key-value pair extraction approach, called KVPFormer, to robustly extracting key-value relationships between entities from form-like document images. Specifically, KVPFormer first identifies key entities from all entities in an image with a Transformer encoder, then takes these key entities as \textbf{questions} and feeds them into a Transformer decoder to predict their corresponding \textbf{answers} (i.e., value entities) in parallel. To achieve higher answer prediction accuracy, we propose a coarse-to-fine answer prediction approach further, which first extracts multiple answer candidates for each identified question in the coarse stage and then selects the most likely one among these candidates in the fine stage. In this way, the learning difficulty of answer prediction can be effectively reduced so that the prediction accuracy can be improved. Moreover, we introduce a spatial compatibility attention bias into the self-attention/cross-attention mechanism for \Ours{} to better model the spatial interactions between entities. With these new techniques, our proposed \Ours{} achieves state-of-the-art results on FUNSD and XFUND datasets, outperforming the previous best-performing method by 7.2\% and 13.2\% in F1 score, respectively.
ViBERTgrid: A Jointly Trained Multi-Modal 2D Document Representation for Key Information Extraction from Documents
May 25, 2021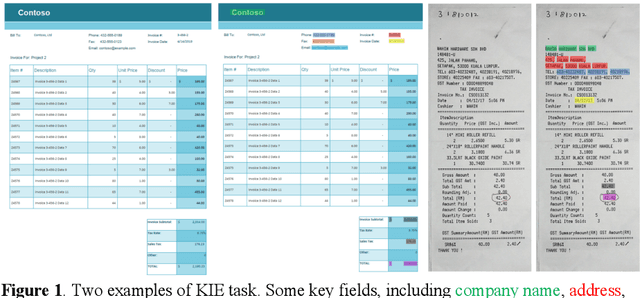
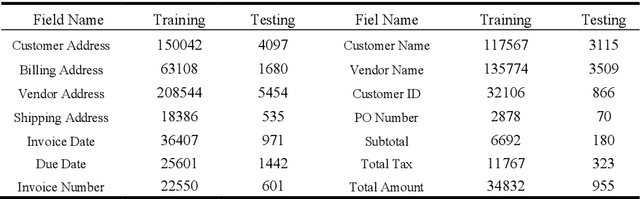
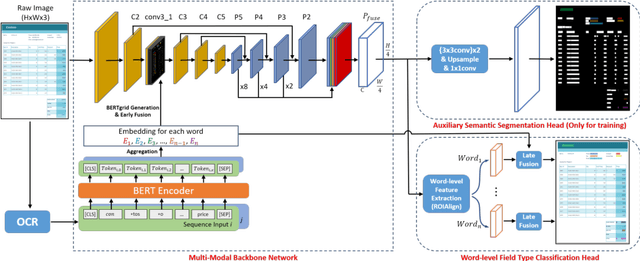
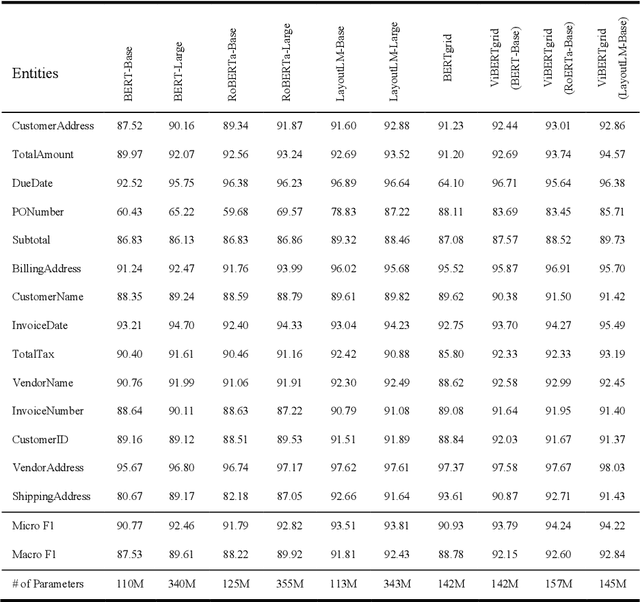
Recent grid-based document representations like BERTgrid allow the simultaneous encoding of the textual and layout information of a document in a 2D feature map so that state-of-the-art image segmentation and/or object detection models can be straightforwardly leveraged to extract key information from documents. However, such methods have not achieved comparable performance to state-of-the-art sequence- and graph-based methods such as LayoutLM and PICK yet. In this paper, we propose a new multi-modal backbone network by concatenating a BERTgrid to an intermediate layer of a CNN model, where the input of CNN is a document image and the BERTgrid is a grid of word embeddings, to generate a more powerful grid-based document representation, named ViBERTgrid. Unlike BERTgrid, the parameters of BERT and CNN in our multimodal backbone network are trained jointly. Our experimental results demonstrate that this joint training strategy improves significantly the representation ability of ViBERTgrid. Consequently, our ViBERTgrid-based key information extraction approach has achieved state-of-the-art performance on real-world datasets.
ReLaText: Exploiting Visual Relationships for Arbitrary-Shaped Scene Text Detection with Graph Convolutional Networks
Mar 16, 2020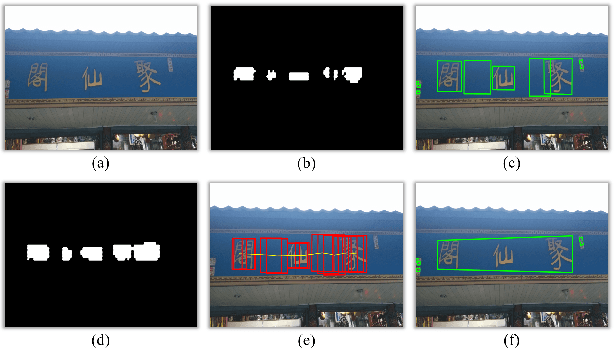
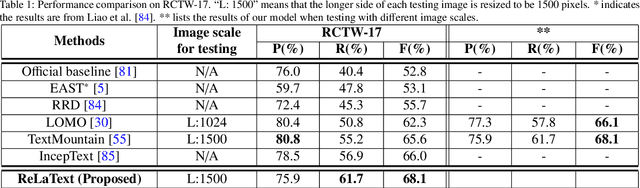
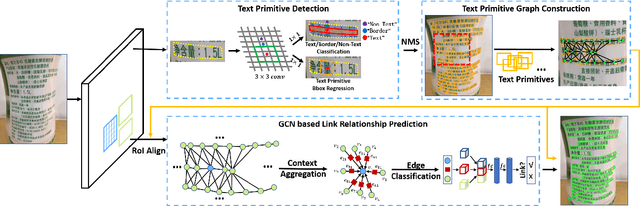
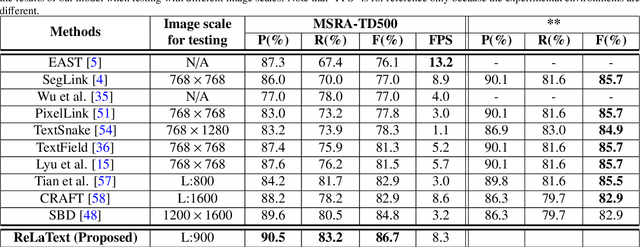
We introduce a new arbitrary-shaped text detection approach named ReLaText by formulating text detection as a visual relationship detection problem. To demonstrate the effectiveness of this new formulation, we start from using a "link" relationship to address the challenging text-line grouping problem firstly. The key idea is to decompose text detection into two subproblems, namely detection of text primitives and prediction of link relationships between nearby text primitive pairs. Specifically, an anchor-free region proposal network based text detector is first used to detect text primitives of different scales from different feature maps of a feature pyramid network, from which a text primitive graph is constructed by linking each pair of nearby text primitives detected from a same feature map with an edge. Then, a Graph Convolutional Network (GCN) based link relationship prediction module is used to prune wrongly-linked edges in the text primitive graph to generate a number of disjoint subgraphs, each representing a detected text instance. As GCN can effectively leverage context information to improve link prediction accuracy, our GCN based text-line grouping approach can achieve better text detection accuracy than previous text-line grouping methods, especially when dealing with text instances with large inter-character or very small inter-line spacings. Consequently, the proposed ReLaText achieves state-of-the-art performance on five public text detection benchmarks, namely RCTW-17, MSRA-TD500, Total-Text, CTW1500 and DAST1500.
Mask R-CNN with Pyramid Attention Network for Scene Text Detection
Nov 22, 2018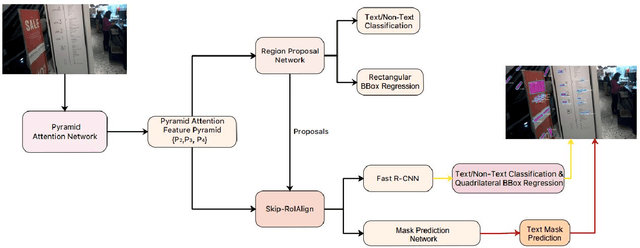
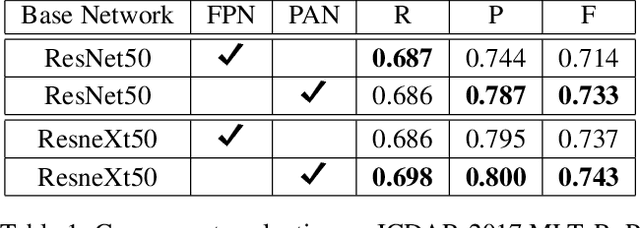
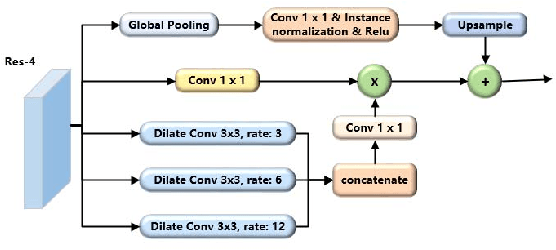
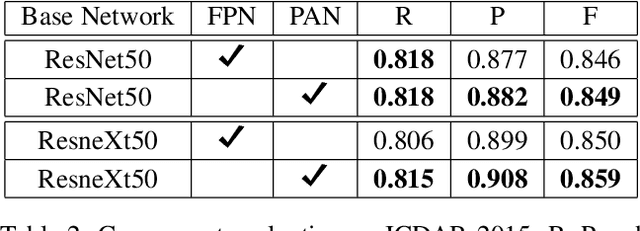
In this paper, we present a new Mask R-CNN based text detection approach which can robustly detect multi-oriented and curved text from natural scene images in a unified manner. To enhance the feature representation ability of Mask R-CNN for text detection tasks, we propose to use the Pyramid Attention Network (PAN) as a new backbone network of Mask R-CNN. Experiments demonstrate that PAN can suppress false alarms caused by text-like backgrounds more effectively. Our proposed approach has achieved superior performance on both multi-oriented (ICDAR-2015, ICDAR-2017 MLT) and curved (SCUT-CTW1500) text detection benchmark tasks by only using single-scale and single-model testing.
An Anchor-Free Region Proposal Network for Faster R-CNN based Text Detection Approaches
Apr 24, 2018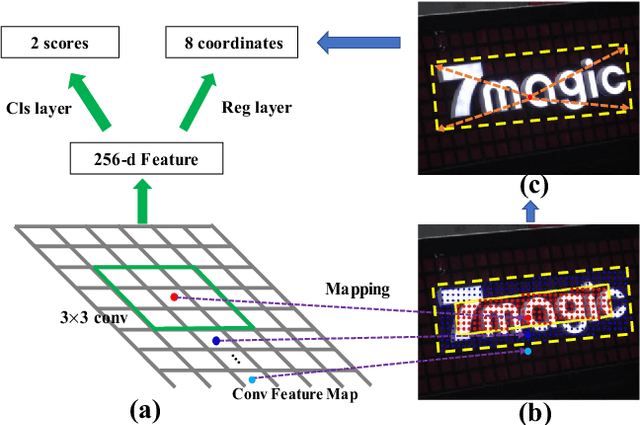

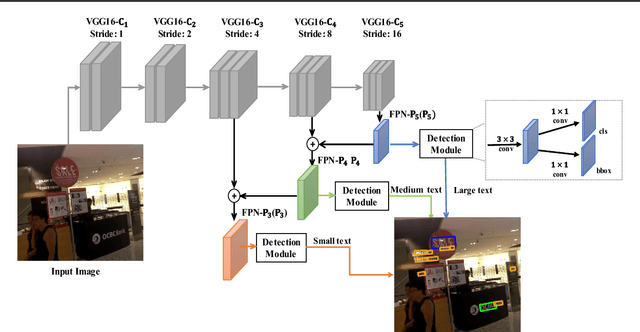
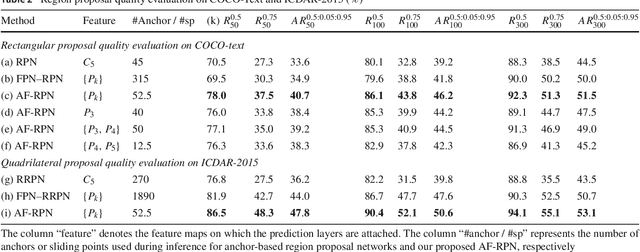
The anchor mechanism of Faster R-CNN and SSD framework is considered not effective enough to scene text detection, which can be attributed to its IoU based matching criterion between anchors and ground-truth boxes. In order to better enclose scene text instances of various shapes, it requires to design anchors of various scales, aspect ratios and even orientations manually, which makes anchor-based methods sophisticated and inefficient. In this paper, we propose a novel anchor-free region proposal network (AF-RPN) to replace the original anchor-based RPN in the Faster R-CNN framework to address the above problem. Compared with a vanilla RPN and FPN-RPN, AF-RPN can get rid of complicated anchor design and achieve higher recall rate on large-scale COCO-Text dataset. Owing to the high-quality text proposals, our Faster R-CNN based two-stage text detection approach achieves state-of-the-art results on ICDAR-2017 MLT, ICDAR-2015 and ICDAR-2013 text detection benchmarks when using single-scale and single-model (ResNet50) testing only.
DeepText: A Unified Framework for Text Proposal Generation and Text Detection in Natural Images
May 24, 2016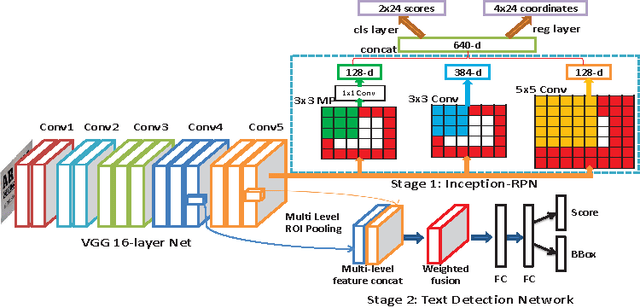
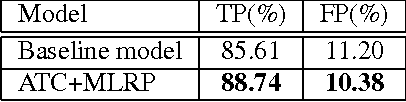

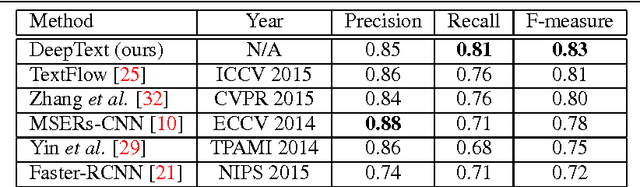
In this paper, we develop a novel unified framework called DeepText for text region proposal generation and text detection in natural images via a fully convolutional neural network (CNN). First, we propose the inception region proposal network (Inception-RPN) and design a set of text characteristic prior bounding boxes to achieve high word recall with only hundred level candidate proposals. Next, we present a powerful textdetection network that embeds ambiguous text category (ATC) information and multilevel region-of-interest pooling (MLRP) for text and non-text classification and accurate localization. Finally, we apply an iterative bounding box voting scheme to pursue high recall in a complementary manner and introduce a filtering algorithm to retain the most suitable bounding box, while removing redundant inner and outer boxes for each text instance. Our approach achieves an F-measure of 0.83 and 0.85 on the ICDAR 2011 and 2013 robust text detection benchmarks, outperforming previous state-of-the-art results.