 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifiedMLLM: Enabling Unified Representation for Multi-modal Multi-tasks With Large Language Model
Aug 05, 2024
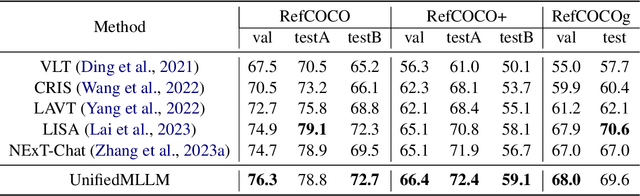
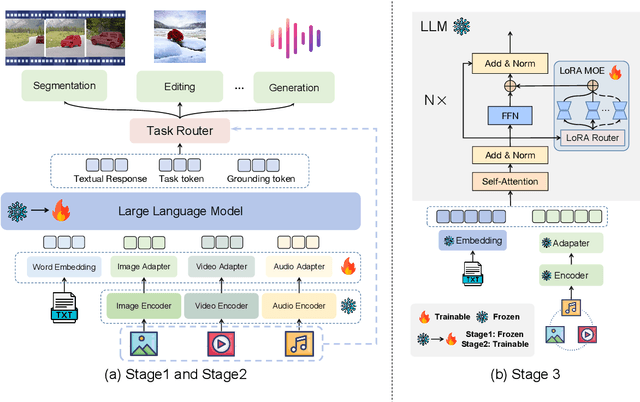

Significant advancements has recently been achieved in the field of multi-modal large language models (MLLMs), demonstrating their remarkable capabilities in understanding and reasoning across diverse tasks. However, these models are often trained for specific tasks and rely on task-specific input-output formats, limiting their applicability to a broader range of tasks. This raises a fundamental question: Can we develop a unified approach to represent and handle different multi-modal tasks to maximize the generalizability of MLLMs? In this paper, we propose UnifiedMLLM, a comprehensive model designed to represent various tasks using a unified representation. Our model exhibits strong capabilities in comprehending the implicit intent of user instructions and preforming reasoning. In addition to generating textual responses, our model also outputs task tokens and grounding tokens, serving as indicators of task types and task granularity. These outputs are subsequently routed through the task router and directed to specific expert models for task completion. To train our model, we construct a task-specific dataset and an 100k multi-task dataset encompassing complex scenarios. Employing a three-stage training strategy, we equip our model with robust reasoning and task processing capabilities while preserving its generalization capacity and knowledge reservoir. Extensive experiments showcase the impressive performance of our unified representation approach across various tasks, surpassing existing methodologies. Furthermore, our approach exhibits exceptional scalability and generality. Our code, model, and dataset will be available at \url{https://github.com/lzw-lzw/UnifiedMLLM}.
GroundingGPT:Language Enhanced Multi-modal Grounding Model
Jan 30, 2024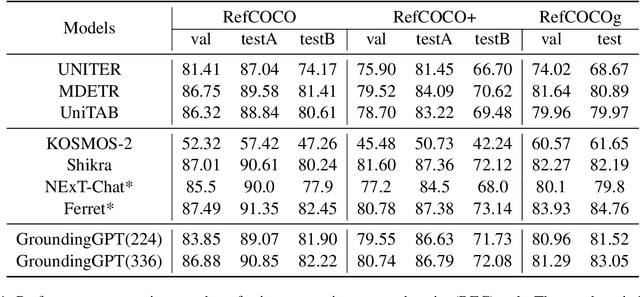
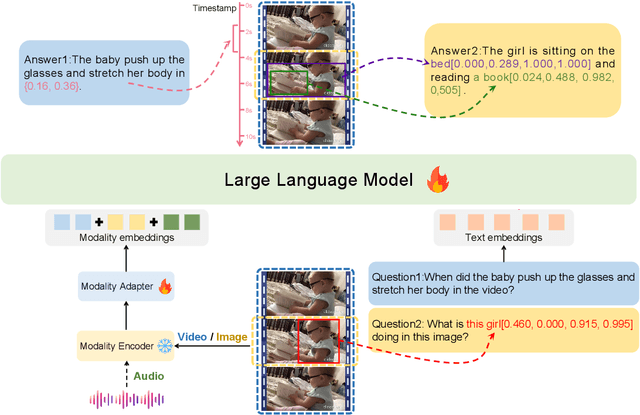
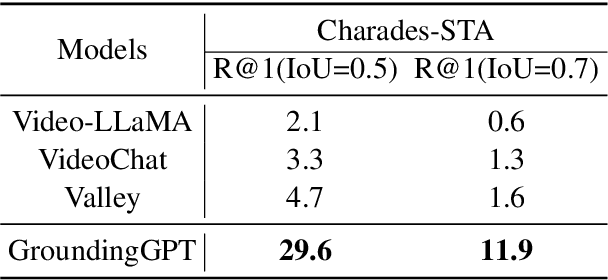
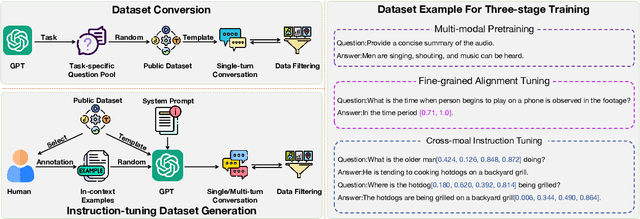
Multi-modal large language models have demonstrated impressive performance across various tasks in different modalities. However, existing multi-modal models primarily emphasize capturing global information within each modality while neglecting the importance of perceiving local information across modalities. Consequently, these models lack the ability to effectively understand the fine-grained details of input data, limiting their performance in tasks that require a more nuanced understanding. To address this limitation, there is a compelling need to develop models that enable fine-grained understanding across multiple modalities, thereby enhancing their applicability to a wide range of tasks. In this paper, we propose GroundingGPT, a language enhanced multi-modal grounding model. Beyond capturing global information like other multi-modal models, our proposed model excels at tasks demanding a detailed understanding of local information within the input. It demonstrates precise identification and localization of specific regions in images or moments in videos. To achieve this objective, we design a diversified dataset construction pipeline, resulting in a multi-modal, multi-granularity dataset for model training. The code, dataset, and demo of our model can be found at https: //github.com/lzw-lzw/GroundingGPT.
MagFace: A Universal Representation for Face Recognition and Quality Assessment
Apr 03, 2021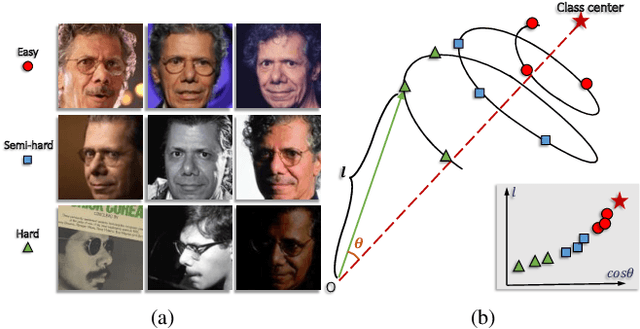



The performance of face recognition system degrades when the variability of the acquired faces increases. Prior work alleviates this issue by either monitoring the face quality in pre-processing or predicting the data uncertainty along with the face feature. This paper proposes MagFace, a category of losses that learn a universal feature embedding whose magnitude can measure the quality of the given face. Under the new loss, it can be proven that the magnitude of the feature embedding monotonically increases if the subject is more likely to be recognized. In addition, MagFace introduces an adaptive mechanism to learn a wellstructured within-class feature distributions by pulling easy samples to class centers while pushing hard samples away. This prevents models from overfitting on noisy low-quality samples and improves face recognition in the wild. Extensive experiments conducted on face recognition, quality assessments as well as clustering demonstrate its superiority over state-of-the-arts. The code is available at https://github.com/IrvingMeng/MagFace.
* accepted at CVPR 2021, Oral
Visible Feature Guidance for Crowd Pedestrian Detection
Sep 16, 2020
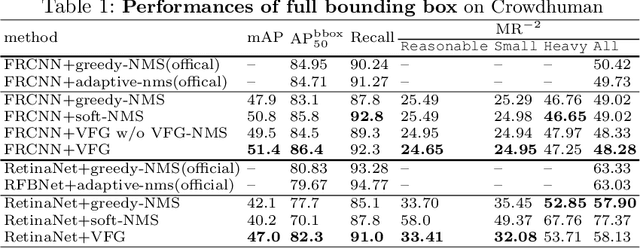
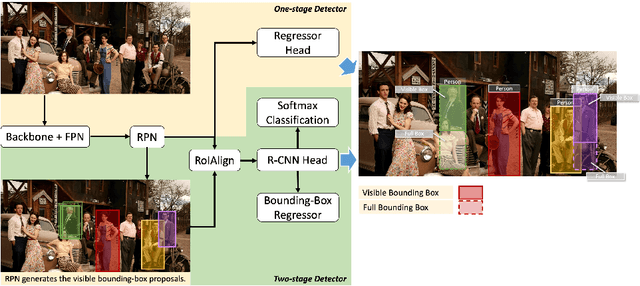
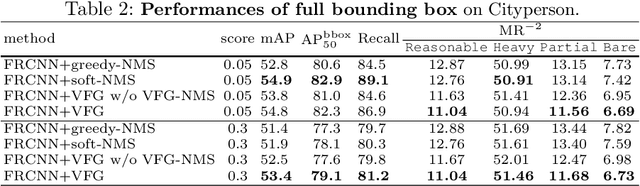
Heavy occlusion and dense gathering in crowd scene make pedestrian detection become a challenging problem, because it's difficult to guess a precise full bounding box according to the invisible human part. To crack this nut, we propose a mechanism called Visible Feature Guidance (VFG) for both training and inference. During training, we adopt visible feature to regress the simultaneous outputs of visible bounding box and full bounding box. Then we perform NMS only on visible bounding boxes to achieve the best fitting full box in inference. This manner can alleviate the incapable influence brought by NMS in crowd scene and make full bounding box more precisely. Furthermore, in order to ease feature association in the post application process, such as pedestrian tracking, we apply Hungarian algorithm to associate parts for a human instance. Our proposed method can stably bring about 2~3% improvements in mAP and AP50 for both two-stage and one-stage detector. It's also more effective for MR-2 especially with the stricter IoU. Experiments on Crowdhuman, Cityperson, Caltech and KITTI datasets show that visible feature guidance can help detector achieve promisingly better performances. Moreover, parts association produces a strong benchmark on Crowdhuman for the vision community.
Mask R-CNN with Pyramid Attention Network for Scene Text Detection
Nov 22, 2018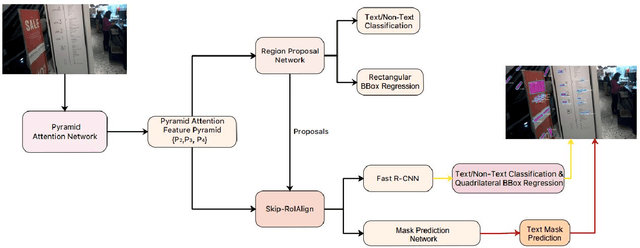
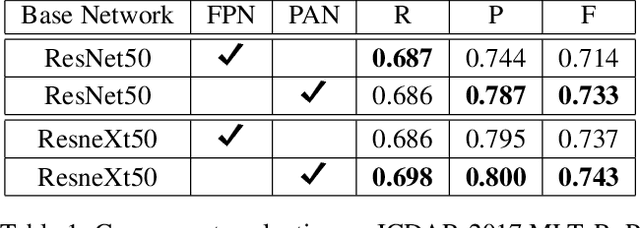
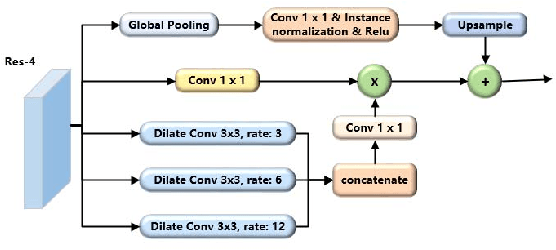
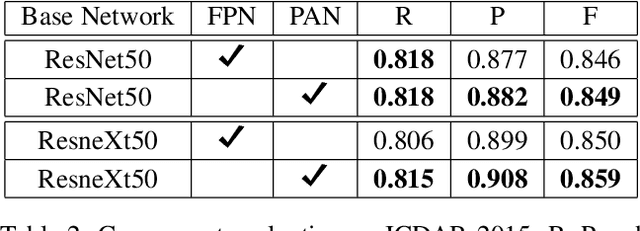
In this paper, we present a new Mask R-CNN based text detection approach which can robustly detect multi-oriented and curved text from natural scene images in a unified manner. To enhance the feature representation ability of Mask R-CNN for text detection tasks, we propose to use the Pyramid Attention Network (PAN) as a new backbone network of Mask R-CNN. Experiments demonstrate that PAN can suppress false alarms caused by text-like backgrounds more effectively. Our proposed approach has achieved superior performance on both multi-oriented (ICDAR-2015, ICDAR-2017 MLT) and curved (SCUT-CTW1500) text detection benchmark tasks by only using single-scale and single-model testing.